Deskriptivstatistik für Nominal- und Ordinalskalen
Kernfragen dieser Lehreinheit
- Wie werden Häufigkeitstabellen erstellt?
- Wie können aus absoluten Häufigkeitstabellen relative Häufigkeitstabellen gemacht werden?
- Wie kann der Modus bestimmt werden?
- Auf welche Weise lässt sich der relative Informationsgehalt bestimmen, obwohl es dafür in R keine Funktion gibt?
- Wie bestimmt man den Median und Interquartilsbereich unter Beachtung von fehlenden Werten in den Daten?
- Welche Befehle können genutzt werden, um Balken-, Kuchendiagramme und Histogramme zu erzeugen?
- Welche Möglichkeiten gibt es, um Grafiken anzupassen?
- Wie können Grafiken gespeichert werden?
Wiederholung aus der Vorlesung: Skalenniveaus
| Skala | Aussage | Transformation | Zentrale Lage | Dispersion |
|---|---|---|---|---|
| Nominal | Äquivalenz | eineindeutig | Modus | Relativer Informationsgehalt |
| Ordinal | Ordnung | monoton | Median | Interquartilsbereich |
| Intervall | Verhältnis von Differenzen | positiv linear | Mittelwert | Standardabweichung, Varianz |
| Verhältnis | Verhältnisse | Ähnlichkeit | … | … |
| Absolut | absoluter Wert | Identität | … | … |
Vorbereitende Schritte
Nachdem wir in der letzten Sitzung die Arbeit mit dem CSV Format kennen gelernt haben, nutzen wir jetzt die Datei im RDA Format für das Einlesen des Datensatzes. Die Datei können Sie hier
herunterladen. Außerdem ist es prinzipiell ratsam, zu Beginn wieder das Arbeitsverzeichnis mit Hilfe von setwd() zu bestimmen. Dies stellt sicher, dass wenn Sie später Daten speichern (z.B. Datensätze oder Grafiken), diese auch am gewünschten Ort auf Ihrem Computer abgelegt werden.
Eine alternative Variante ist, den Datensatz direkt mit dem folgenden Befehl aus dem Internet einzuladen. Dies ist immer dann möglich, wenn der Datensatz auch über eine URL aufrufbar ist.
load(url('https://pandar.netlify.app/post/fb22.rda')) # Daten laden
names(fb22) # Namen der Variablen## [1] "prok1" "prok2" "prok3" "prok4" "prok5" "prok6" "prok7"
## [8] "prok8" "prok9" "prok10" "nr1" "nr2" "nr3" "nr4"
## [15] "nr5" "nr6" "lz" "extra" "vertr" "gewis" "neuro"
## [22] "intel" "nerd" "grund" "fach" "ziel" "lerntyp" "geschl"
## [29] "job" "ort" "ort12" "wohnen" "uni1" "uni2" "uni3"
## [36] "uni4"dim(fb22) # Anzahl Zeile und Spalten## [1] 159 36In der letzten Sitzung haben wir schon einige Befehle für das Screening eines Datensatzes kennen gelernt. Dabei zeigt names() alle Variablennamen an, während dim() uns Zeilen und Spalten ausgibt. Der Datensatz hat also 159 Beobachtungen auf 36 Variablen.
Nominalskalierte Variablen
Typische Beispiele für nominalskalierte Variablen in der Psychologie sind das Geschlecht (z.B. Variable “geschl” in fb22), die Experimentalbedingung (z.B. “Experimentalgruppe” und “Kontrollgruppe”). Nominalskalierte Variablen sollten in R als Faktoren hinterlegt werden. Faktoren in R sind Vektoren mit einer vorab definierten Menge an vorgegebenen möglichen Ausprägungsmöglichkeiten. Sowohl numerische als auch character-Variablen können als Faktor kodiert werden, was mit jeweiligen Vorteilen einhergeht:
- für numerische Variablen: es können (aussagekräftige) Labels zugewiesen (“hinterlegt”) werden. Diese werden dann für Tabellen und Grafiken übernommen
- Für character-Variablen: Faktoren können für Analysen verwendet werden (z.B. als Prädiktoren in einer Regression), was für character-Variablen nicht möglich gewesen wäre
Jeder numerischen Faktorstufe (level) kann ein Label zugewiesen werden. Faktorstufe und –label bestehen auch dann, wenn die entsprechende Ausprägung empirisch nicht auftritt.
Beispiel 1: Die (numerische) Variable geschl als Faktor aufbereiten
str(fb22$geschl)## int [1:159] 1 2 2 2 1 NA 2 1 1 1 ...fb22$geschl## [1] 1 2 2 2 1 NA 2 1 1 1 1 2 2 1 1 1 1 1 1 1 1 1 2 1 NA
## [26] 1 1 1 1 1 2 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1
## [51] 1 1 1 NA 1 2 1 2 1 1 1 2 1 NA NA 1 3 1 1 1 1 1 1 1 1
## [76] 1 1 1 2 2 2 1 2 2 1 1 1 1 1 1 1 1 1 1 NA 1 1 1 1 1
## [101] 1 NA 2 1 1 1 1 NA 1 NA 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1
## [126] 2 1 1 NA 2 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [151] 1 1 1 1 1 1 2 1 1Die Variable geschl liegt numerisch vor, es treten die Werte 1, 2 und 3 empirisch auf. Die Bedeutung von NA wird später betrachtet. Anhand des Kodierschemas (
Variablenübersicht) kann den Zahlen eine inhaltliche Bedeutung zugewiesen werden. Beispielsweise bedeutet der Wert 1 “weiblich”. Diese Label werden nun im Faktor hinterlegt.
Vorgehensweise:
- Erstellung einer neuen Variable im Datensatz per Objektzuweisung:
datensatz$neueVariable <- factor(...) - Faktor erstellen mit der Funktion
factor(Ausgangsvariable, levels = Stufen, labels = Label) - Spezifikation der Faktorstufen im Argument
levels, also der numerischen Ausprägungen auf der Ursprungsvariable (hier: 1, 2 und 3) - Spezifikation des Arguments
labels, also die Label für die inlevelshinterlegten numerischen Stufen (hier: “weiblich”, “männlich”, “anderes”; unbedingt auf gleiche Reihenfolge achten!)
fb22$geschl_faktor <- factor(fb22$geschl, # Ausgangsvariable
levels = 1:3, # Faktorstufen
labels = c("weiblich", "männlich", "anderes")) # Label für Faktorstufen
str(fb22$geschl_faktor)## Factor w/ 3 levels "weiblich","männlich",..: 1 2 2 2 1 NA 2 1 1 1 ...head(fb22$geschl_faktor)## [1] weiblich männlich männlich männlich weiblich <NA>
## Levels: weiblich männlich anderesBeispiel 2: Lieblingsfach (numerisch) als Faktor aufbereiten
Analog dazu wird nachfolgend die ebenfalls numerische Variable fach in einen Faktor umgewandelt. Sie wurde wie folgt erhoben:
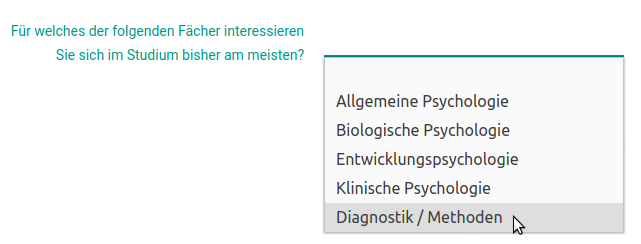
fb22$fach## [1] 5 4 1 4 2 NA 1 4 3 4 3 2 2 2 4 3 2 3 4 4 1 3 4 4 NA
## [26] 3 NA 2 3 4 4 1 3 2 1 3 1 NA 2 4 4 4 4 4 4 1 4 1 3 1
## [51] 1 3 4 NA 4 2 4 4 4 4 3 4 2 NA NA 4 4 3 4 3 4 3 3 1 3
## [76] 4 4 4 3 3 4 2 3 3 2 3 4 2 4 3 4 2 3 3 NA 4 2 4 2 2
## [101] 4 NA 2 3 2 1 1 3 5 NA 4 5 1 1 4 4 3 2 2 2 NA 3 5 4 3
## [126] 5 2 4 NA 1 4 3 3 5 4 1 4 4 2 3 3 4 3 2 4 4 4 4 4 5
## [151] 2 1 3 1 2 3 4 4 4Es treten die Ausprägungen 1 bis 5 empirisch auf. Auch hier werden die Label aus dem Kodierschema zugewiesen.
fb22$fach <- factor(fb22$fach,
levels = 1:5,
labels = c('Allgemeine', 'Biologische', 'Entwicklung', 'Klinische', 'Diag./Meth.'))
str(fb22$fach)## Factor w/ 5 levels "Allgemeine","Biologische",..: 5 4 1 4 2 NA 1 4 3 4 ...Hinweis: In Beispiel 2 wurde die Ursprungsvariable mit dem Faktor überschrieben. Sie ist nun verschwunden, der Datensatz enthält nur noch den Faktor, nicht mehr die numerische Variable.
Beispiel 3: Einen character-Vektor als Faktor aufbereiten
Um einen character-Vektor in einen Faktor umzukodieren, kann die Funktion as.factor() verwendet werden (siehe Skript zur Lehreinheit 1). Die Ausprägungen werden dann automatisch als Labels übernommen. Die numerischen Stufen (levels) werden anhand der alphabetischen Reihenfolge der labels vergeben.
Nachfolgend wird zur Illustration die offene Freitextantwort zum Grund für das Psychologiestudium (Variable grund) in einen Faktor umgewandelt.
str(fb22$grund) # Ursprungsvariable: Character## chr [1:159] "Interesse" "Allgemeines Interesse schon seit der Kindheit" ...fb22$grund_faktor <- as.factor(fb22$grund) # Umwandlung in Faktor
str(fb22$grund_faktor) # neue Variable: Faktor## Factor w/ 135 levels "- Aus Interesse ",..: 62 9 102 113 51 70 26 87 24 90 ...Die neue Variable ist nun ein Faktor mit 135 Stufen. Das Vorgehen ist nur zur Anschauung gedacht und in diesem speziellen Fall nicht sinnvoll, da jede einzelne Freitextantwort vermutlich nur genau einmal vorkommt und später sowieso nicht (ohne zusätzliche Kodierung) in statistischen Analysen weiterverwendet werden kann.
Wir haben nun also gelernt, dass Faktoren auf verschiedene Weisen erstellt werden können. Wir benutzen nun die Funktion factor(), wenn unsere Variable zunächst nur numerisch vorlag (Beispiele 1 und 2) und wir eine Bedeutung zuordnen wollen. Wenn die Variable als character (Beispiel 3 und Intro-Sitzung), nutzen wir die Funktion as.factor().
Hinweise zu den Levels und Labels
Die Reihenfolge von Levels und Labels ergibt sich während der Faktorerstellung:
- bei numerischen Variablen: entspricht den Ausprägungen der numerischen Ursprungsvariable
- bei character-Variablen: entspricht der alphabetischen Reihenfolge der Ausprägungen auf der Ursprungsvariable
Die Labels eines Faktors können mit der Funktion levels() abgerufen werden. Die Reihenfolge kann mithilfe der relevel()-Funktion geändert werden. Dafür muss dasjenige Label angesprochen werden, das die erste Position einnehmen soll (hier: ‘Diag./Meth.’).
levels(fb22$fach) # Abruf## [1] "Allgemeine" "Biologische" "Entwicklung" "Klinische" "Diag./Meth."fb22$fach <- relevel(
fb22$fach, # Bezugskategorie wechseln
'Diag./Meth.') # Neue BezugskategorieHäufigkeitstabellen
Eine deskriptivstatistische Möglichkeit zur Darstellung diskreter (zählbarer) nominalskalierter Variablen sind Häufigkeitstabellen. Diese können in R mit der Funktion table() angefordert werden.
Absolute Häufigkeiten
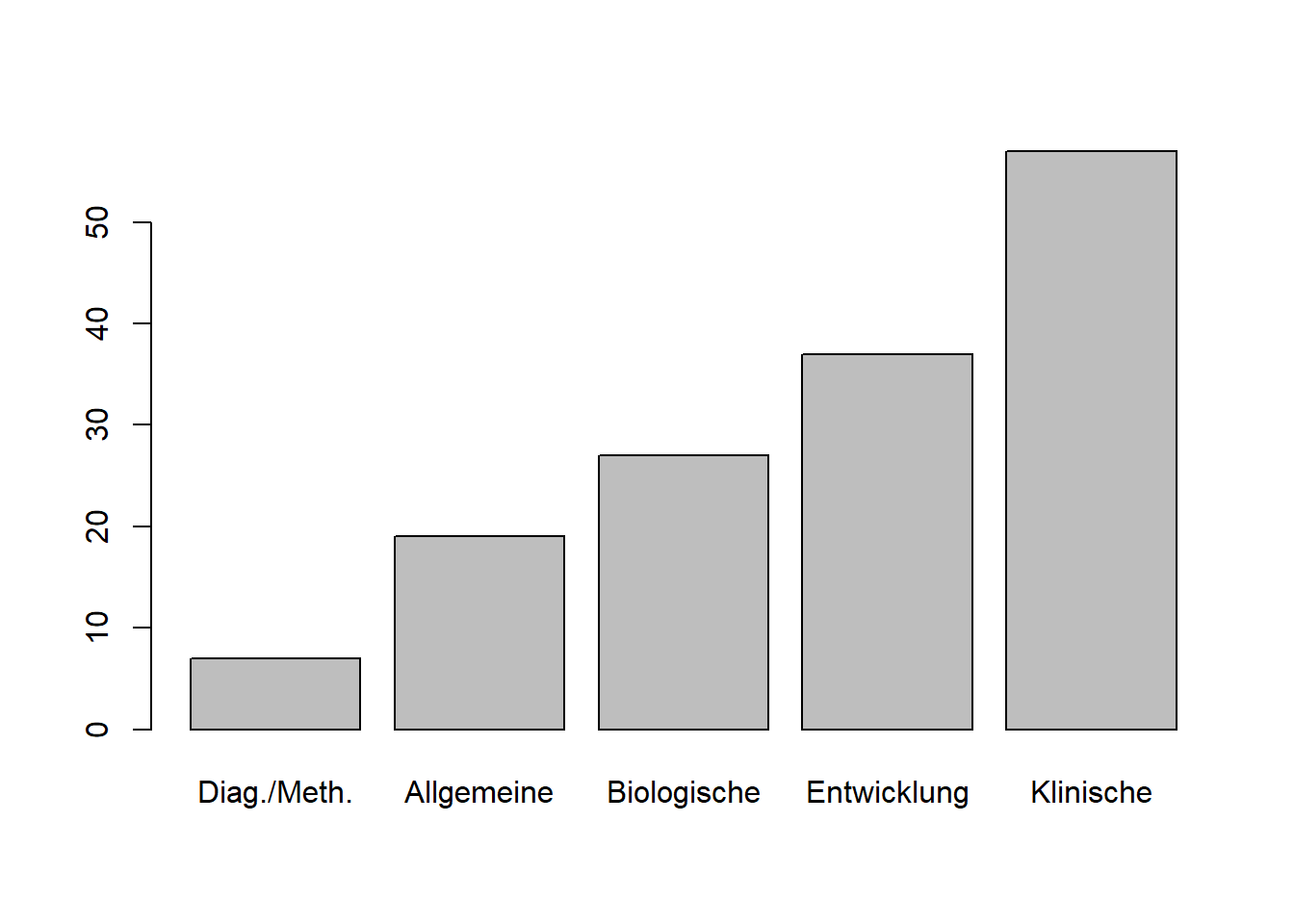
table(fb22$fach)##
## Diag./Meth. Allgemeine Biologische Entwicklung Klinische
## 7 19 27 37 57Häufig sind relative Häufigkeiten informativer. Nachfolgend werden zwei Möglichkeiten zur Erstellung von relativen Häufigkeitstabellen in R gezeigt.
Relative Häufigkeiten (manuell)
Relative Häufigkeiten können aus absoluten Häufigkeiten abgeleitet werden: \(h_j = \frac{n_j}{n}\).
Diese einfache Rechenvorschrift (Kategorienhäufigkeit geteilt durch Gesamthäufigkeit) kann auf das gesamte Tabellenobjekt angewendet werden. So wird jede einzelne absolute Kategorienhäufigkeit am Gesamtwert relativiert, es resultiert eine Tabelle der relativen Häufigkeiten.
tab <- table(fb22$fach) # Absolute Haeufigkeiten
sum(tab) # Gesamtzahl## [1] 147tab / sum(tab) # Relative Haeufigkeiten##
## Diag./Meth. Allgemeine Biologische Entwicklung Klinische
## 0.04761905 0.12925170 0.18367347 0.25170068 0.38775510Relative Häufigkeiten (per Funktion)
Alternativ kann die Funktion prop.table() auf das Tabellenobjekt mit den absoluten Häufigkeiten angewendet werden.
tab <- table(fb22$fach) # Absolute
prop.table(tab) # Relative##
## Diag./Meth. Allgemeine Biologische Entwicklung Klinische
## 0.04761905 0.12925170 0.18367347 0.25170068 0.38775510Ungefähr 4.76% Ihres Jahrgangs geben als Lieblingsfach “Diagnostik/Methoden” an! Vielleicht können wir ja noch mehr von Ihnen mit dem nächsten Thema begeistern. :-)
Grafiken in R
Die Darstellung als Tabelle wirkt häufig langweilig. Zu viele Tabellen in einem Bericht / einer Arbeit schrecken Leser:innen meist ab. Nachfolgend werden mögliche grafische Darstellungsformen für diskrete nominalskalierte Variablen gezeigt. Hierfür haben Sie in der Vorlesung die Optionen eines Balken- bzw. Säulendiagramms und eines Tortendiagramms kennengelernt.
Säulen- oder Balkendiagramm
Die Erstellung ist mit der Funktion barplot() möglich. Diese braucht zunächst nur ein Tabellenobjekt als Input, dass die absoluten Häufigkeiten für die verschiedenen Kategorien einer Variable enthält.
barplot(tab)Die Grafik erscheint in der RStudio-Standardansicht “unten rechts” im Reiter “Plots”:

Tortendiagramm
Die Erstellug eines Tortendiagramms ist ebenfalls leicht zu erreichen. Die Funktion heißt pie() und braucht denselben Input wie barplot().
pie(tab)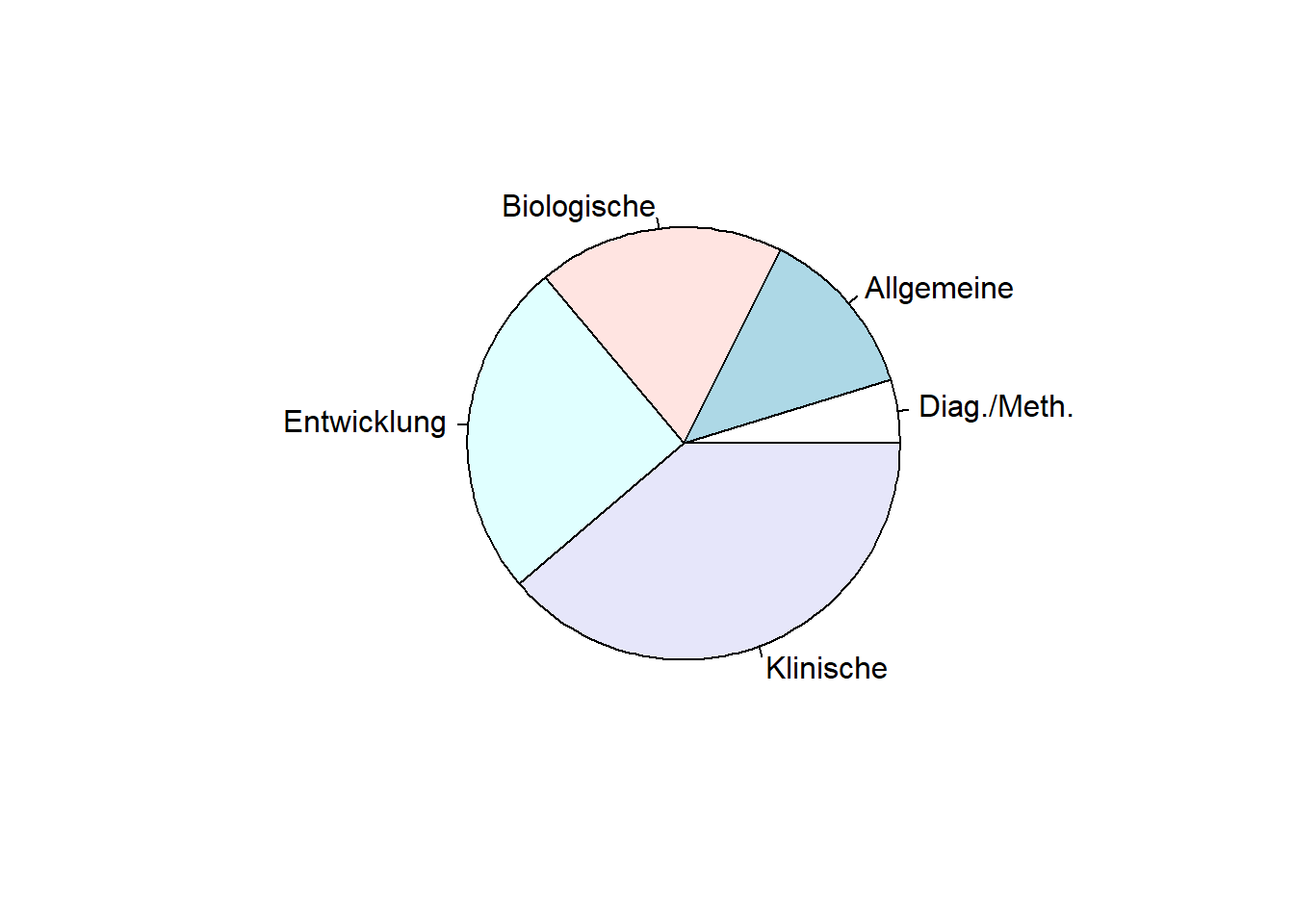
In der Vorlesung haben Sie bereits gelernt, dass diese Form der Darstellung aber nicht zu empfehlen ist, weil Erkenntnisse daraus viel schwerer zu ziehen sind. Bei den Zusatzargumenten werden wir uns also nur mit der Funktion barplot() beschäftigen.
Zusatzargumente für Plots
Die Funktionen zur Erstellung sehr simpler Grafiken sind also denkbar einfach - die Grafiken selbst aber zunächst nicht unbedingt hübsch. R bietet diverse Zusatzargumente zur Anpassung der Optik von Grafiken.
| Argument | Bedeutung |
|---|---|
| main | Überschrift |
| las | Schriftausrichtung (0, 1, 2, 3) |
| col | Farbenvektor |
| legend.text | Beschriftung in der Legende |
| xlim, ylim | Beschränkung der Achsen |
| xlab, ylab | Beschriftung der Achsen |
Farben in R
R kennt eine ganze Reihe vordefinierter Farben ($N = $ 657) mit teilweise sehr poetischen Namen. Diese können mit der Funktion colors() (ohne Argument) abgerufen werden. Hier sind die ersten 20 Treffer:
colors()[1:20]## [1] "white" "aliceblue" "antiquewhite" "antiquewhite1"
## [5] "antiquewhite2" "antiquewhite3" "antiquewhite4" "aquamarine"
## [9] "aquamarine1" "aquamarine2" "aquamarine3" "aquamarine4"
## [13] "azure" "azure1" "azure2" "azure3"
## [17] "azure4" "beige" "bisque" "bisque1"Die Farben aus der Liste können als Zahl (Index) oder per Name angesprochen werden. Eine vollständige Liste der Farben findet sich zum Beispiel unter http://www.stat.columbia.edu/~tzheng/files/Rcolor.pdf. Farben können aber auch per RGB-Vektor (Funktion rgb()) oder HEX-Wert angesprochen werden.
Zusätzlich können Farbpaletten verwendet werden. Sie bestehen aus einem Farbverlauf, aus dem einzelne Farben “herausgezogen” werden, wodurch ein zusammengehöriges Farbthema in einer Abbildung entsteht. R liefert einige dieser Paletten: rainbow(...), heat.colors(...), topo.colors(...), … Die Farbpalette wird ebenfalls per col-Argugment spezifiziert. Technisch handelt es sich um eine Funktion, für die als Argument die Anzahl der Farben spezifiziert werden muss, die aus der Palette “gezogen” werden sollen. Es wäre also so, als würden wir diese 5 Farben per Hand eingeben, nur dass wir die Person entscheiden lassen, die eine Palette programmiert hat Beispielsweise werden mit col = rainbow(5) fünf Farben aus der rainbow-Palette gezogen. Der Output würde so aussehen.
rainbow(5)## [1] "#FF0000" "#CCFF00" "#00FF66" "#0066FF" "#CC00FF"Die Farben werden hier nicht direkt mit ihrem Namen, sondern mit dem Hex-Code ausgegeben. #FF0000 steht dabei beispielsweise für ein rot.
Beispiel für angepasste Abbildung
barplot(tab,
col = rainbow(5), # Farbe
ylab = 'Anzahl Studierende', # y-Achse Bezeichnung
main = 'Lieblingsfach im 1. Semester', # Überschrift der Grafik
las = 2, # Ausrichtung der Labels
cex.names = 0.8) # Schriftgröße der Labels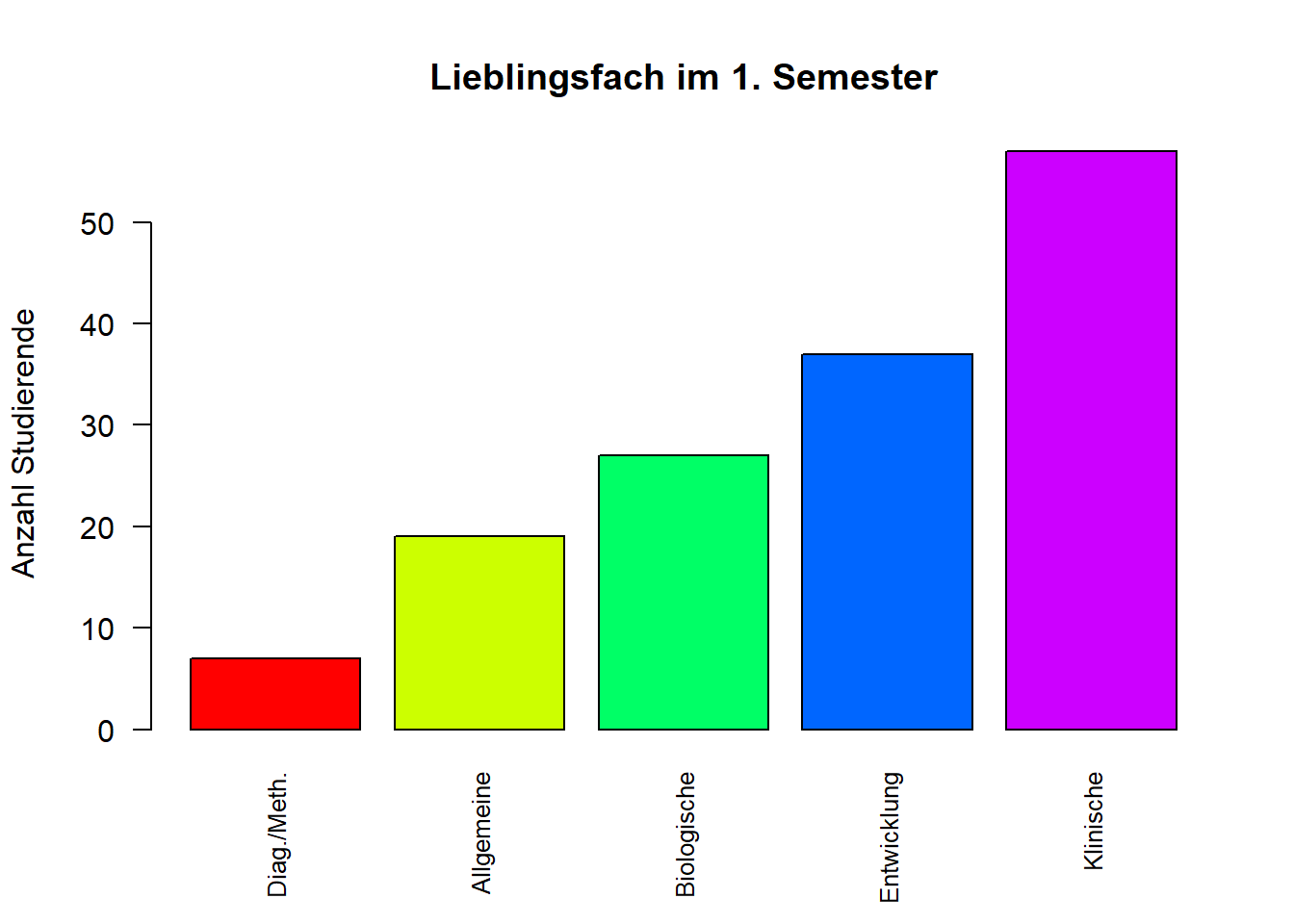
Alle verwendeten Argumente (bis auf eines) sind bereits in der Tabelle oben beschrieben. Wir fügen einen Titel zur y-Achse mittels ylab hinzu. main ist verantwortlich für den Titel der Grafik, während las die Beschriftung der Säulen dreht. Das bisher nicht genannte Argument cex.names verändert die Schriftgröße für die Beschriftung der Balken. Wenn wir diese nicht anpassen würden, würde die Schrift den Rahmen der Standardeinstellungen für Grafen in R sprengen und damit teilweise außerhalb des Bildes stehen.
Hinweis: Es gibt natürlich noch viele weitere Argumente, mit denen Sie Bestandteile des Diagramms anpassen können. Falls Sie sich beispielsweise fragen, wie sie aus dem Säulendiagramm ein Balkendiagramm machen können, könnten Sie das mit dem Argument horiz erreichen. Wenn Sie also die horizontale Ausrichtung der Grafik auf TRUE setzen, erhalten Sie horizontale Balken anstatt vertikale Säulen.
Grafiken speichern
Es gibt zwei Möglichkeiten, um in R erzeugte Grafiken als Bilddatei zu speichern: manuell und per Funktion.
Möglichkeit 1: Manuelles Speichern
Klicken Sie auf die Schaltfläche “Export” und dann auf “Save as Image”…
…und spezifizieren Sie dann Dateiname (ggf. Pfad) und Größe/Größenverhältnis.
Wenn kein Pfad spezifiziert wird, erscheint die Datei in Ihrem aktuellen Arbeitsverzeichnis.
Möglichkeit 2: Speichern mit der Funktion jpeg("Dateiname.jpg")
Auch ohne die grafische Oberfläche von RStudio ist die Erstellung und das Speichern einer Grafik mittels R möglich. Zunächst wird das für Euch keinen großen Einfluss haben, da wir nicht nur in der Konsole arbeiten. Wenn jemand sich doch in die Richtung vertieft, ist die Interaktion mit Servern auf Grundlage einer Konsole selten zu vermeiden. Dann könnte auch die folgende Erstellung eine Rolle spielen.
Wir starten die Erstellung einer Grafik mittels Code mit der jpeg()-Funktion. Hierin machen wir sozusagen eine grafische Umgebung auf. In dieser legen wir bereits einige Paramter der Bilddatei fest (wie Höhe, Breite und auch Auflösung). Als nächstes kommt der Code für die Grafik. Diesen haben wir bereits gesehen. Der entstehende Plot wird jetzt in die zuvor erzeugte grafische Umgebung “abgelegt”. Mit der Funktion dev.off() wird die Erstellung beendet. Die grafische Umgebung (und damit die Entwicklung unserer Bild-Datei) wird damit “geschlossen”.
jpeg("Mein-Barplot.jpg", width=15, height=10, units="cm", res=150) # Eröffnung Bilderstellung
barplot(tab,
col = rainbow(5),
ylab = 'Anzahl Studierende',
main = 'Lieblingsfach im 1. Semester',
las = 2,
cex.names = 0.8)
dev.off() # Abschluss BilderstellungAuch hier gilt: Wenn kein Pfad spezifiziert wurde, liegt die Datei in Ihrem Arbeitsverzeichnis. In der Funktion jpeg() kann mit den Argumenten units angegeben werden, in welcher Einheit die anderen Argumente zu verstehen sind.
Deskriptivstatistische Kennwerte auf Nominalskalenniveau
Der Modus (Mo) ist ein Maß der zentralen Tendenz, das die häufigste Ausprägung einer Variable anzeigt. Die Häufigkeiten sind ja schon in der Häufigkeitstabelle enthalten. Man könnte den Modus also einfach ablesen. Das gleiche lässt sich allerdings auch anhand von Funktionen tun:
tab # Tabelle ausgeben##
## Diag./Meth. Allgemeine Biologische Entwicklung Klinische
## 7 19 27 37 57max(tab) # Größte Häufigkeit## [1] 57which.max(tab) # Modus## Klinische
## 5Der Modus der Variable fach lautet also Klinische, die Ausprägung trat 57 mal auf.
Der relative Informationsgehalt ist ein Dispersionsmaß, das schon auf Nominalskalenniveau funktioniert. Dafür gibt es in R allerdings keine Funktion! Aus Lehreinheit 1 wissen Sie jedoch, dass R als Taschenrechner genutzt werden kann, folglich können beliebig komplexe Gleichungen in R umgesetzt werden. Die Formel zur Berechnung des relativen Informationsgehalts \(H\) lautet:
\[H = -\frac{1}{\ln(k)} \sum_{j=1}^k{h_j * \ln h_j} \]
Wir benötigen also \(h_j\), was die relativen Häufigkeiten der einzelnen Kategorien bezeichnet. Hier haben wir schon gelernt, dass wir diese durch anwenden der Funktion prop.table auf unser Objekt tab erhalten können. Anschließend muss noch mit der Funktion log gearbeitet werden, die den natürlichen Logarithmus als Standardeinstellung berechnet. \(k\) ist in diesem Fall die maximale Nummer einer unserer Kategorien - also die Kategorienanzahl 5. Falls wir diese nicht selbst zählen möchten, kann dim uns die Anzahl an Spalten in tab verraten. Der Rest ist dann nur einfache Multiplikation, Addition und Division.
hj <- prop.table(tab) # hj erstellen
ln_hj <- log(hj) # Logarithmus bestimmen
ln_hj # Ergebnisse für jede Kategorie##
## Diag./Meth. Allgemeine Biologische Entwicklung Klinische
## -3.0445224 -2.0459936 -1.6945957 -1.3795147 -0.9473813summand <- ln_hj * hj # Berechnung für jede Kategorie
summe <- sum(summand) # Gesamtsumme
k <- dim(tab) # Anzahl Kategorien
relinf <- -1/log(k) * summe # Relativer Informationsgehalt
relinf## [1] 0.8917737Eine kleine Abkürzung durch Einsparen der Schritte am Ende könnte hier folgendermaßen mittels Pipe erreicht werden:
relinf <- (ln_hj * hj) |> sum() * (-1/log(k)) # Relativer Informationsgehalt
relinf## [1] 0.8917737Eine alternative Schreibweise, die ohne Zwischenschritte auskommt, dafür aber in Form von vielen Klammern stark verschachtelt ist, lautet:
- 1/log(dim(table(fb22$fach))) * sum(prop.table(table(fb22$fach)) * log(prop.table(table(fb22$fach))))## [1] 0.8917737Wie man hier sieht, stößt die Schachtelung ohne das Speichern von Zwischenergebnissen oder das nutzen der Pipe schnell an die Grenzen der Übersichtlichkeit.
In allen drei Varianten kommen wir aber zum gleichen Schluss: der relative Informationsgehalt der Variable fach beträgt 0.892. Da der mögliche Wertebereich zwischen 0 (für alle Personen selbe Kategorie) und 1 (für alle Kategorien gleich viele Personen) variiert, kann hier von einer starken Verteilung der Personen ausgegangen werden.
Ordinalskalierte Variablen
In diesem Abschnitt lernen Sie deskriptivstatistische Kennwerte für ordinalskalierte Variablen kennen. Aus der Vorlesung wissen Sie schon, dass Median und Interquartilsabstand (IQA) nur für die Klasse der geordneten Kategorien (auch “Rangklassen”) sinnvoll sind, nicht für singuläre Daten (“Rangwerte”).
Zunächst aber eine Wiederholung: Wie Sie aus der Vorlesung wissen, können die in der Tabelle am Anfang dieses Dokuments aufgeführten statistischen Kennwerte (Zentrale Lage, Dispersion) auch für Skalenniveaus genutzt werden, die “weiter unten” in der Tabelle stehen. Für ordinalskalierte Variablen (Rangklassen) kann also auch der Modus berechnet werden.
Nachfolgend soll mit Item 4 des Prokrastinationsfragebogens gearbeitet werden. Es wurde wie folgt erhoben:
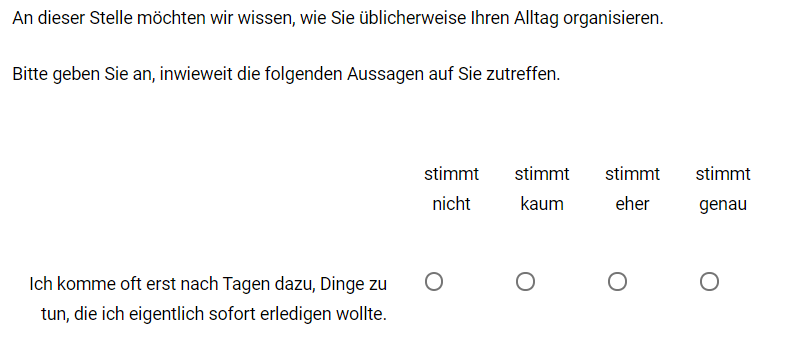
Es treten die Werte 1 bis 4 empirisch auf, außerdem gibt es 2 fehlende Werte (dargestellt als NA):
fb22$prok4## [1] 2 4 4 NA 3 2 2 3 3 4 1 2 3 2 3 NA 2 4 2 2 2 3 3 2 3
## [26] 2 2 2 1 3 2 3 3 3 3 2 3 2 3 2 3 3 3 4 3 3 3 4 2 4
## [51] 3 2 3 4 3 3 2 1 4 2 2 2 2 2 2 2 2 2 3 2 2 2 3 2 3
## [76] 3 3 2 2 3 1 2 2 1 3 2 3 2 2 3 3 2 2 2 1 1 3 2 4 3
## [101] 2 4 3 3 1 2 2 3 4 3 1 3 2 2 3 2 2 2 3 4 3 1 2 2 3
## [126] 3 4 3 3 3 3 4 3 1 2 3 2 2 3 2 2 4 4 2 3 2 3 2 4 2
## [151] 2 2 2 4 3 4 3 3 3Wiederholung:
table(fb22$prok4) # Absolute Haeufigkeiten##
## 1 2 3 4
## 11 66 60 20prop.table(table(fb22$prok4)) # Relative Haeufigkeiten##
## 1 2 3 4
## 0.07006369 0.42038217 0.38216561 0.12738854which.max(table(fb22$prok4)) # Modus## 2
## 2Fehlende Werte
Fehlende Werte (dargestellt als NA) in empirischen Untersuchungen können aus vielen Gründen auftreten:
- Fragen überlesen / nicht gesehen
- Antwort verweigert
- Unzulässige Angaben gemacht (im Papierformat)
- Unleserliche Schrift (im Papierformat)
- …
Für statistische Analysen sind fehlende Werte ein Problem, weil sie außerhalb der zulässigen Antworten liegen.
Fehlende Werte in R
Fehlende Werte werden im Datensatz als NA dargestellt. In R kann man solche Fälle auf zwei unterschiedlichen Ebenen berücksichtigen:
- Global:
na.omit(datensatz)- Entfernt alle Beobachtungen, die auf irgendeiner Variable einen fehlenden Wert haben
- Häufig auch “listenweiser Fallausschluss” genannt
- Entfernt alle Beobachtungen, die auf irgendeiner Variable einen fehlenden Wert haben
- Lokal:
na.rm = TRUE- Das Argument
na.rmist in vielen Funktionen für univariate Statistiken enthalten - Per Voreinstellung wird
NAals Ergebnis produziert, wenn fehlende Werte vorliegen - Fehlende Werte werden nur für diese eine Analyse ausgeschlossen, wenn sie auf der darin untersuchten Variable keinen Wert haben - Datensatz bleibt erhalten
- Das Argument
Fehlende Werte sind ein ganz eigenes Forschungsgebiet der Methodik und man könnte eine ganze Veranstaltung nur zu diesem Thema halten. Hierfür haben wir leider keine Zeit, weshalb wir uns der sehr einfachen Methode bedienen, dass wir fehlende Werte von der Analyse ausschließen. Dies ist kein empfohlenes Vorgehen für empirische Arbeiten im fortgeschrittenen Verlauf des Studium!
Deskriptivstatistische Kennwerte ab Ordinalskalenniveau
Wir können uns den Einfluss fehlender Werte auf die Arbeit mit R mit der Betrachtung der Funktion für den Median, die praktischerweise median() heißt, veranschaulichen, indem wir einmal ein extra Argument benennen.
median(fb22$prok4) # Ohne Argument für NA: funktioniert nicht## [1] NAmedian(fb22$prok4, na.rm = TRUE) # Expliziter Ausschluss: funktioniert## [1] 3Ohne Argument für die Behandlung der fehlenden Werte wird NA auch als Ergebnis ausgegeben. Mit passendem Argument erhalten wir ein numerisches Ergebnis: Der Median für die Variable prok4 beträgt also 3.
Für eine Beschreibung der Dispersion wird häufig der Interquartilsbereich (IQB) genutzt. IQB ist der Bereich zwischen dem 1. und dem 3. Quartil.
Um die Quartile oder jedes beliebige andere Quantil einer Verteilung zu erhalten, kann die Funktion quantile() verwendet werden. Beispielsweise können wir die Grenzen des IQB und den Median mit folgender Eingabe gleichzeitig abfragen.
quantile(fb22$prok4,
c(.25, .5, .75), # Quartile anfordern
na.rm = T)## 25% 50% 75%
## 2 3 3Der Interquartilsbereich liegt also zwischen 2 und 3.
Den Interquartilsabstand (IQA) können wir nun bestimmen, indem wir das Ergebnis für das dritte und das erste Quartil subtrahieren.
\[IQA = Q_3 - Q_1\]
Mit quantile() ist die Umsetzung in R etwas umständlich, da wir die Funktion zwei Mal aufrufen und die Differenz daraus bilden müssen.
quantile(fb22$prok4, .75, na.rm=T) - quantile(fb22$prok4, .25, na.rm=T)## 75%
## 1Dabei ist in der Ausgabe besonders die Überschrift verwirrend (75%), die hier nichts mit der Bedeutung des Wertes zu tun hat. Der IQA der Variable prok4 beträgt 1. Für die Berechnung des IQA gibt es auch die direkte Funktion IQR(), die uns das ganze einfacher macht.
IQR(fb22$prok4, na.rm = TRUE)## [1] 1Boxplots
Eine geeignete grafische Darstellungsform für (mindestens) ordinalskalierte Daten ist der Boxplot. Er kann über die Funktion boxplot() angefordert werden:
boxplot(fb22$prok4)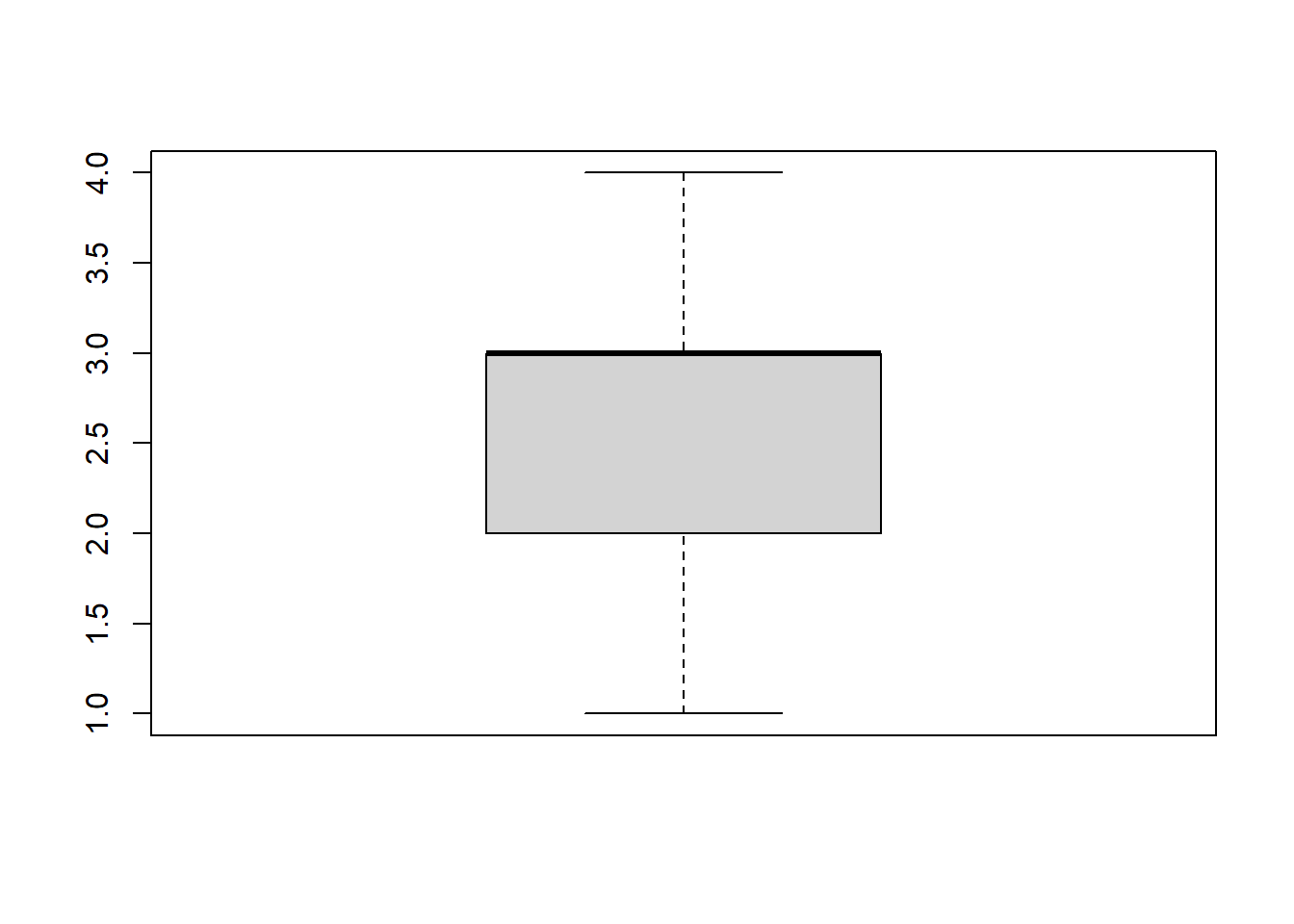
Zur Erinnerung:
- Box: Quartile
- Schwarzer Balken: Median
- Whisker: der jeweils extremste empirische Wert im Bereich
Q3 + 1.5*IQAfür das Maximum bzw.Q1 - 1.5*IQAfür das Minimum - Noch extremere Werte werden als Punkte dargestellt
In diesem Beispiel betragen Median und Q3 jeweils 3, sodass sich die entsprechenden Linien überlagern. Ein Beispiel für einen “schöneren” Boxplot (ohne Überlagerung) ist dieses:
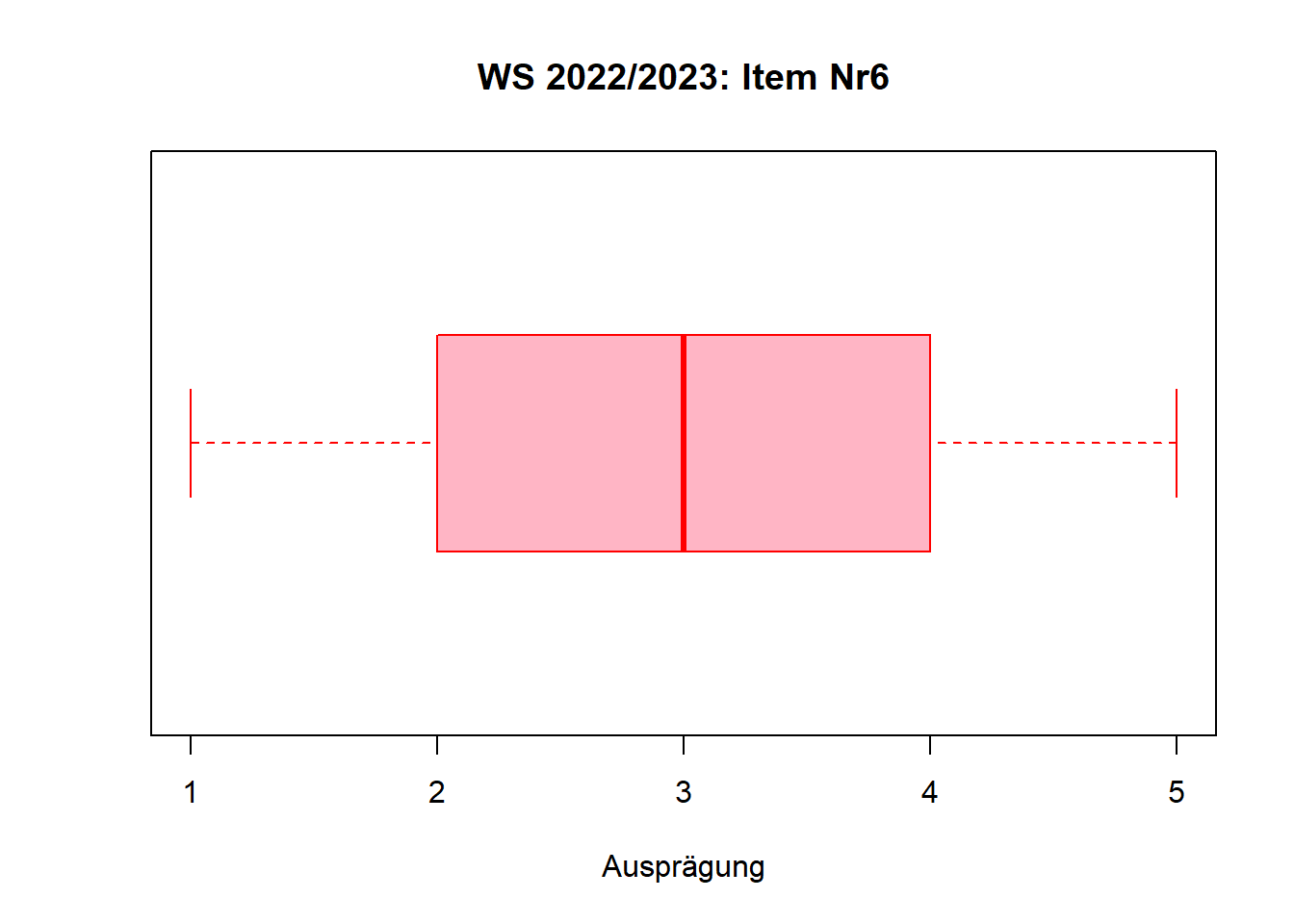
boxplot(fb22$nr6)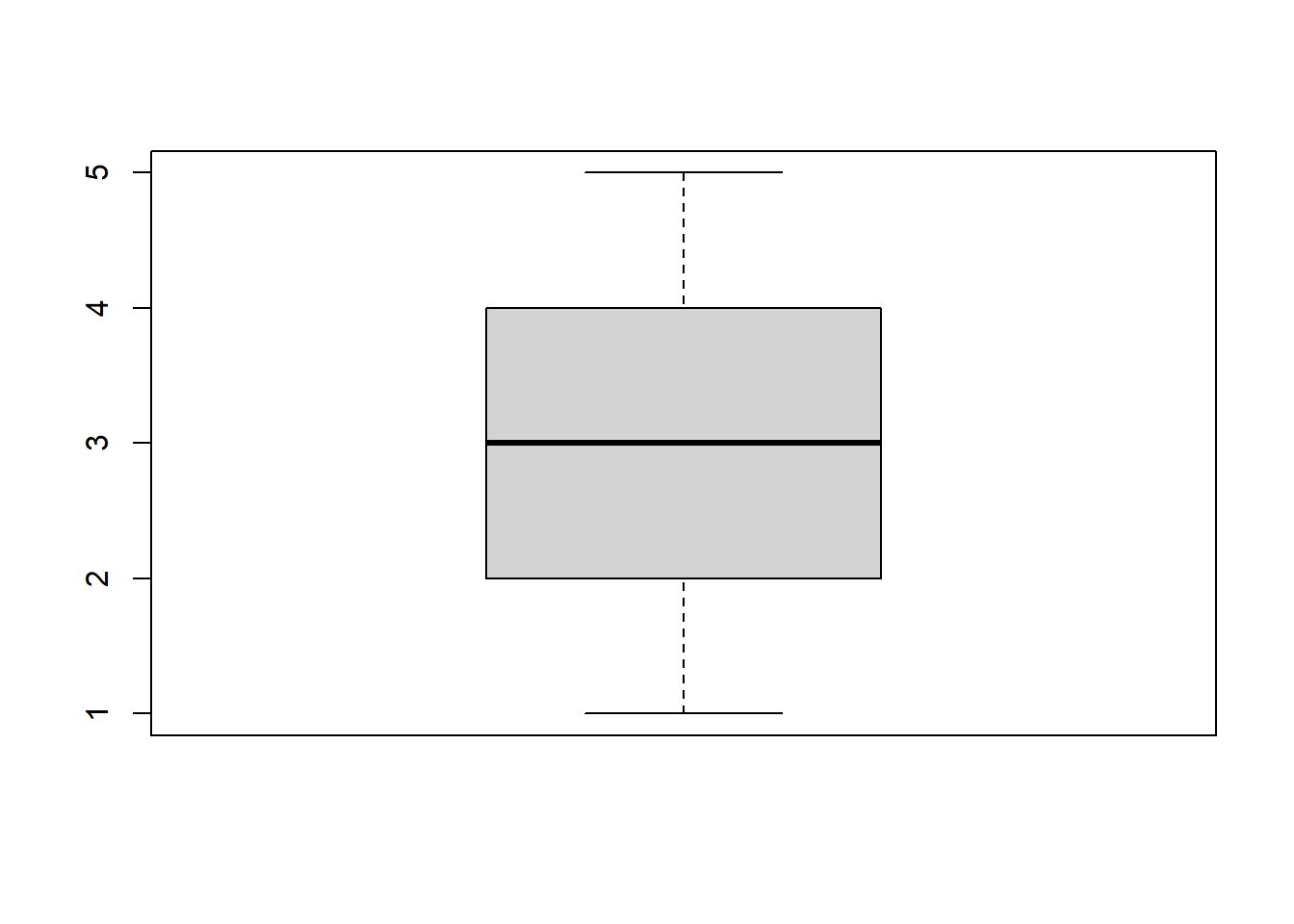
Auch ein Boxplot kann grafisch angepasst werden. Nachfolgend sehen Sie ein Beispiel, in dem möglichst viel verändert wurde, um die verschiedenen Möglichkeiten aufzuzeigen. Nicht alle Veränderungen sind unbedingt sinnvoll in diesem Fall.
boxplot(fb22$nr6,
horizontal = TRUE, # Ausrichtung des Boxplots
main = "WS 2022/2023: Item Nr6", # Überschrift der Grafik
xlab = "Ausprägung", # x-Achse Bezeichnung
las = 1, # Ausrichtung der Labels
border = "red", # Farbe der Linien im Boxplot
col = "pink1") # Farbe der Fläche innerhalb der Box