
formr - FAQ
In diesem Tutorial soll gezeigt werden, wie ihr mit Hilfe von formr Umfragen erstellen können. Das Tutorial soll Sie dabei speziell auf die Anforderungen vorbereiten, die sich Ihnen im Rahmen eurer Gruppenarbeit in PsyBSc2 stellen werden. Das bedeutet, dass ihr lernt, wie ihr euren Fragebögen für formr erstellen könnte. Weiterhin wird gezeigt, wie diese Umfrage mit dem von uns bereit gestellten Teil zu Versuchspersonenminuten-Abfrage verbunden werden kann. Auch die Einwilligung in Teilnahmebedinungen und Datenschutz sowie die Auswirkungen deren Ablehnung sind essentielle Bestandteile der Beschreibung.
Wir präsentieren die Funktionsweise von formr anhand einer abgewandelten und auch verkürzten Version des Fragebogens, welchen ihr in der ersten Woche im Praktikum selbst ausgefüllt haben.
1. Schritt bei formr anmelden
Um eine Umfrage durchführen zu können, braucht eine Person eurer Gruppe logischerweise einen Account bei formr. Eine Registrierung ist zum Zeitpunkt der Erstellung dieses Tutorials nur über diesen Link möglich. Bei der Registrierung ist es zwingend erforderlich, dass ihr den Referall-Token eingebt, den ihr im Praktikum erhalten habt! Denn unter Angabe dieses Tokens bekommt euer Account die für das Durchführen einer Umfrage notwendigen Administratorrechte. Der Token ist eine sehr bequeme Art die Adminrechte zu erlangen. Die einzige andere Möglichkeit ist eine Mail an die Betreiber, die aber nicht “überrannt” werden sollen.
Wenn wir uns nach der Erstellung des Accounts einloggen, sollte die Oberfläche so gestaltet sein.
Wir sehen bereits einige Buttons, die wir später benutzen werden. Die Items unserer Umfrage werden jedoch nicht in dieser online Umgebung definiert, sondern sollten als Tabellenblatt hochgeladen werden. Damit werden wir uns jetzt zunächst beschäftigen, bevor wir auf die weiteren Funktionen von formr eingehen.
2. Schritt Spreadsheet erstellen
Wie bereits beschrieben lassen sich Frageböge bei formr über Spreadsheets / Tabellen erstellen. Wir müssen also eine Datei erstellen, die wir dann in unserem Account hochladen, damit formr eine optisch ansprechende Umfrage daraus erstellt. Die Tabelle kann mit einem Tabellenprogramm wie Excel, Gnumeric oder auch mit einem etwaigen Google Account über Google Sheets erstellt werden. Wichtig ist nur, dass wir ein zeitgemäßes Dateiformat nutzen wie das XLSX-Format (das XLS-Format ist zum Beispielt veraltet). Außerdem darf die Datei im Namen keine Leerzeichen haben. Ein Dateiname wie “tabelle 1.xlsx” kann zu einem Fehler beim Import führen. Anstelle von Leerzeichen können wir Unterstriche benutzen, z. B. “tabelle_1.xlsx”.
Die erstellte Tabelle sollte folgende Spalten besitzen:
- Explanation
- Label
- Class
- Type
- Optional
- Name
- Showif
- Choice1, choice2, …
Im Folgenden ist ein Spreadsheet, das die genannten Spalten und auch schon einige Einträge enthält, zu sehen.
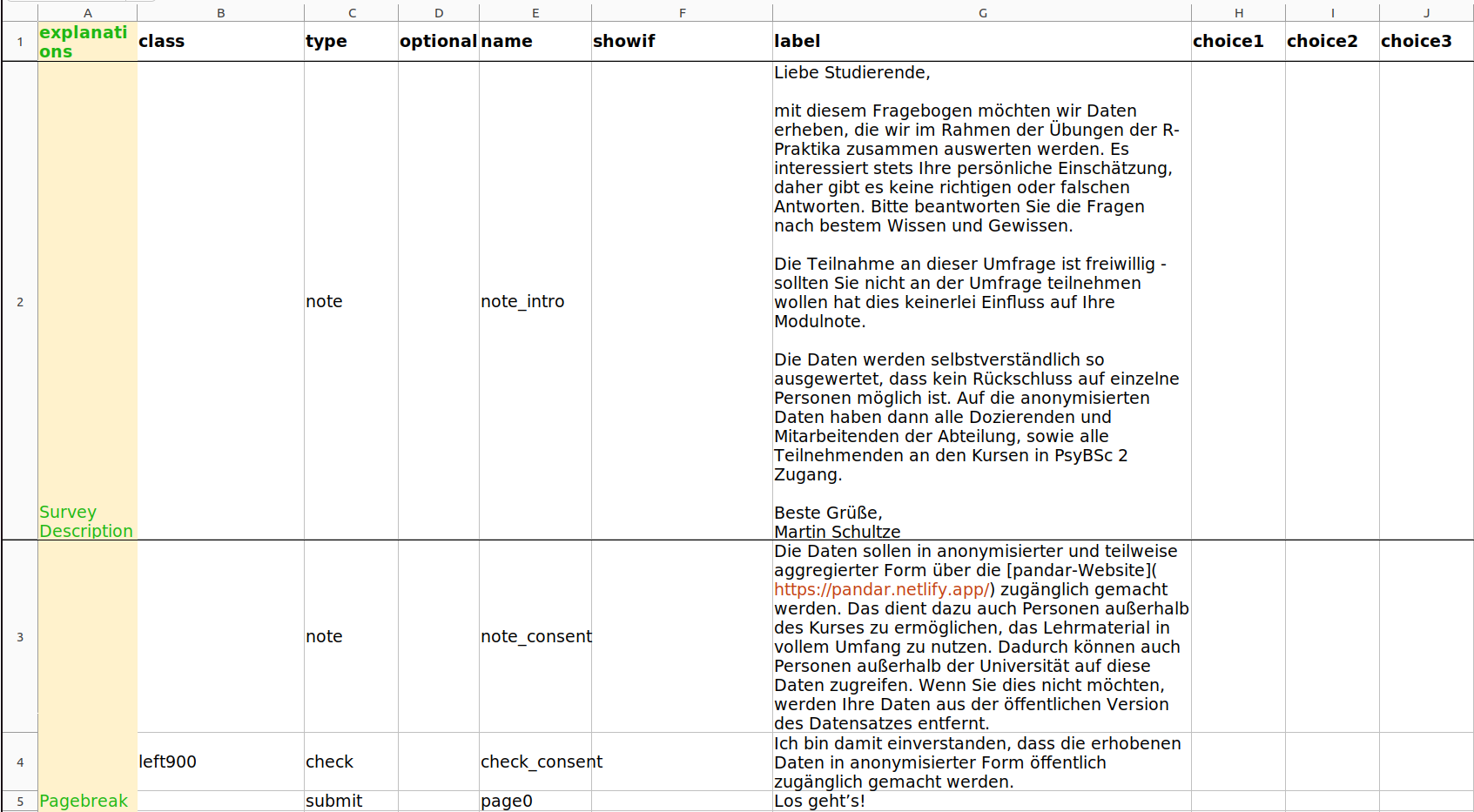
Die Reihenfolge der Spalten ist obligatorisch, im Folgenden werden die Spalten aus didaktischen Gründen jedoch in einer anderen Reihenfolge erläutert. Wir schauen uns zunächst die Spalte label an, die in der Abbildung die größten Einträge hat. Hier werden die Textelemente hineingeschrieben, die für die Teilnehmenden sichtbar sein sollen.
Mit type wird die Art des Items festgelegt. Der type “note” wird verwendet, wenn der Text, den wir in die Spalte label geschrieben haben, bloß dargestellt werden soll. Die Datenschutzerklärung in Zeile 4 soll hingegen nicht nur dargestellt werden, sondern die Teilnehmenden müssen dieser auch zustimmen. Dafür wird der type “check” verwendet, der eine Box erstellt, die zur Bestätigung angeklickt werden kann. (Wie der restliche Fragebogen nur bei Anklicken ausgefüllt werden kann, wird später noch erläutert.) Um eine Seite zu beenden wird “submit” verwendet. Auch hier können wir den Text des Buttons unter label festlegen.
Die Spalte explanantions ist für Ordnung und das eigene Verständnis da. Hier können wir eigene Notizen hinterlassen, die für die Teilnehmenden nicht sichtbar sind. Bei der Erhebung invertierter Items ist hier ein Vermerk zu empfehlen, damit diese bei der Auswertung nicht übersehen werden.
In der Spalte name können wir den Variablen ein Name gegeben. Die Namen sind für die Teilnehmenden ebenfalls nicht sichtbar. Allerdings muss in der Spalte name immer ein Eintrag stehen. Dabei handelt sich um die Variablennamen, mit denen wir bei R die Auswertung durchführen. Leerzeichen in den Variablennamen in der Spalte name sind unzulässig. R erlaubt ebenfalls keine Leerzeichen in Variablennamen. Außerdem dürfen keine Umlaute, Interpunktion und sonstige Sonderzeichen verwendet werden. Zudem müssen die Variablennamen bzw. Elementnamen eindeutig sein (,im Fachjargon spricht man auch von diskret oder eineindeutig).
In der Spalte class können visuelle Formatierungen vorgenommen werden. Mit „left900” (bzw. 100, …, 900) kann so zB ein Inhalt nach rechts eingeschoben werden.
Die erste Seite unseres Fragebogens wird später dann also so aussehen:
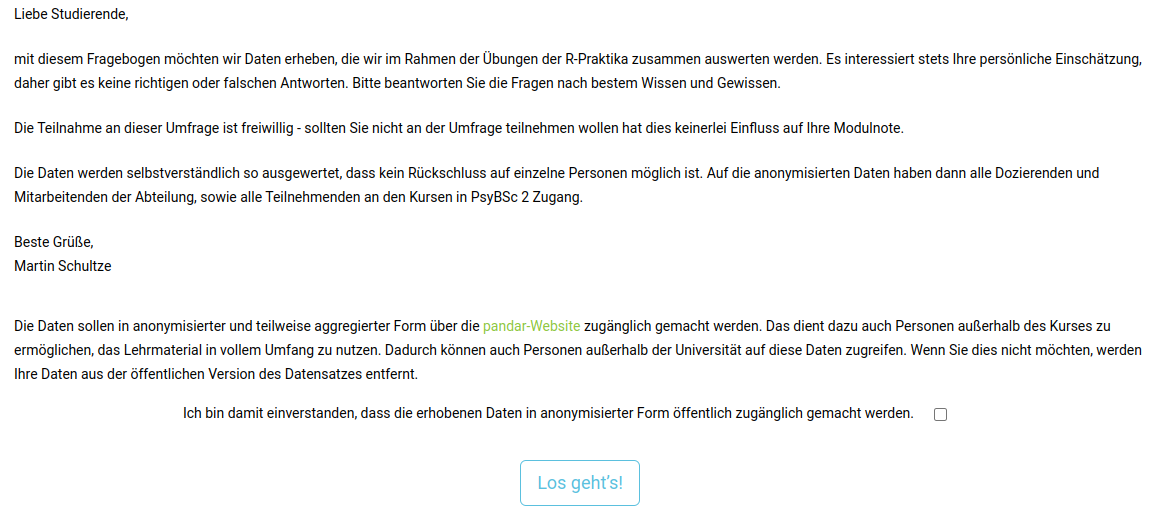
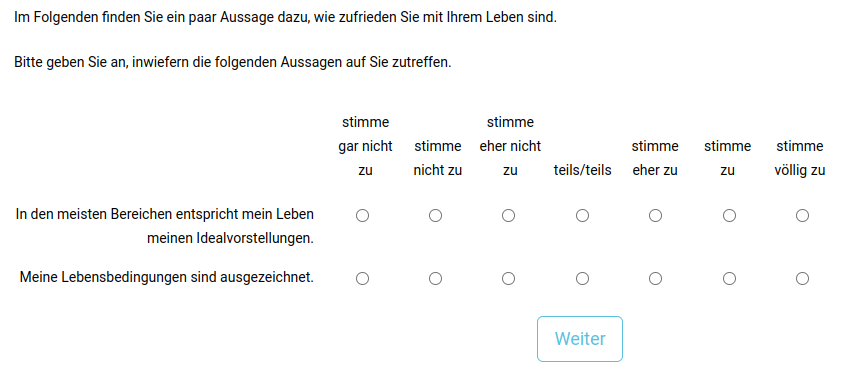
Nachdem die Teilnehmenden die einleitenden Worte gelesen und der Datenschutzerklärung zugestimmt haben, sollen sie einige Items bearbeiten. Damit die Teilnehmenden beispielsweise angeben können, inwiefern die Aussage “In den meisten Bereichen entspricht mein Leben meinen Idealvorstellungen.” auf sie zutrifft, muss ein Single Choice Item erstellt werden. Dies gelingt, indem in die Spalte type “mc” eingetragen wird. (Multiple Choice Items werden mit “mc_multiple” erzeugt.) Überschriften für die einzelnen Kategorien werden mit dem type “mc_heading” erstellt.

Wie in der Abbildung zu sehen ist, kommen jetzt auch die Spalten choice1, choice2, … ins Spiel. In diesen werden die Bezeichnungen für die Antwortmöglichkeiten angegeben. Wichtig ist, dass wir gleich viele choice-Optionen vergeben, wie wir Antwortmöglichkeiten haben. Sollten wir bspw. eine Sieben-Punkte-Likert-Skala haben, allerdings nur choice1 bis choice6 als Spaltennamen in der Tabelle haben, führt dies zu einem Fehler beim Import. Umgekehrt ist es nicht schlimm, wenn die Spalte choice6 existiert, obwohl wir eine Fünf-Punkte-Likert-Skala verwenden. Für die in der Abbildung angegebenen Single-Choice Frage sind die Antwortmöglichkeiten „stimme gar nicht zu”, „stimme nicht zu”, “stimme eher nicht zu”, “teils/teils”, “stimme eher zu”, “stimme zu” und “stimme völlig zu”. Für Items von Fragebögen zu einem gemeinsamen Konstrukt empfiehlt es sich hier, die Spalte name mit einem bedeutsamen Präfix (“swls” als Namen des Fragbogens zur Lebenszufriedenheit) und einer anschließenden Nummerierung des Items zu füllen.
Durch die Einträge in der Spalte class wurden außerdem folgende Formatierungen vorgenommen: Mit “mc_width70” (bzw. 50, … ,100, 150, 200) kann bei Single/Multiple Choice Items der Abstand zwischen den Auswahlmöglichkeiten eingestellt werden. Es empfiehlt sich eine Angabe zum Abstand zu machen, weil die Auswahlmöglichkeiten ansonsten eventuell versetzt unter den Überschriften stehen. Mit “hide_label mc_width70” (bzw. 50, … ,100, 150, 200) wird der Abstand eingestellt und zusätzlich unterbunden, dass die Auswahlmöglichkeiten angezeigt werden. So kann man dafür sorgen, dass die Auswahlmöglichkeiten nicht neben jedem einzelnen Auswahlkästchen stehen, sondern nur einmal in der Überschrift auftauchen. Es ist wichtig die Reihenfolge einzuhalten und erst “hide_label” und dann “mc_width70” zu schreiben.
Im Fragebogen sieht das Ganze dann also so aus:
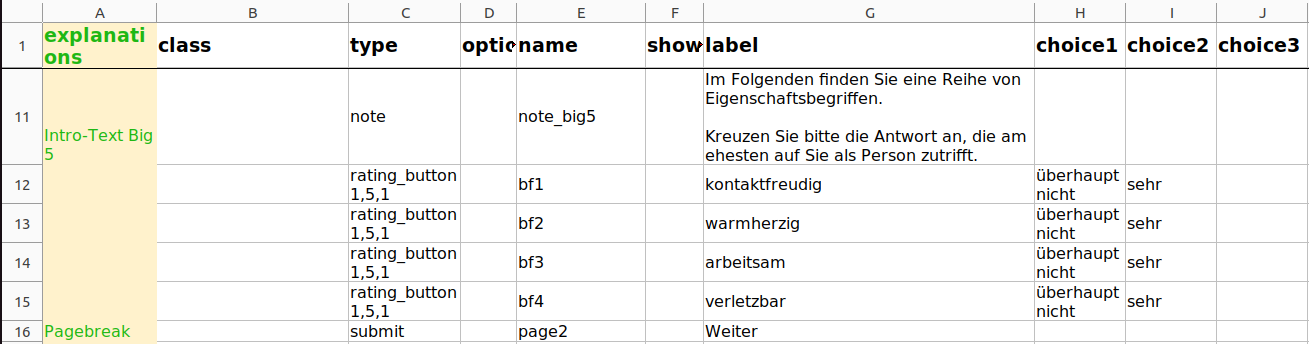
Neben Single oder Multiple Choice Items werden außerdem häufig Ratingbuttons benötigt. Ratingbuttons lassen sich mit dem type „rating_button min,max,step“, wobei min, max und step für das niedrigste Rating, das höchste Rating und die Schrittweite stehen. Bei formr ist ein Leerzeichen zwischen dem Typ-Namen und etwaigen Argumenten notwendig, so würde “rating_button1,5,1” statt “rating_button 1,5,1” zu einer Fehlermeldung führen. In choice1 und choice2 können dann die Anker für die Antworten links und rechts der Ratingbuttons angegeben werden.
Der entsprechende Fragebogenabschnitt:
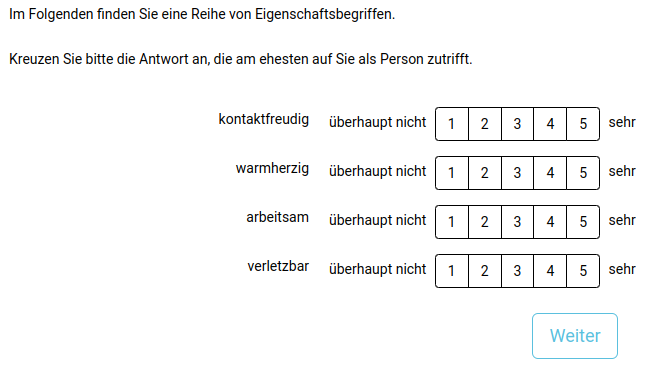
Sollen die Teilnehmenden hingegen frei antworten können, ist dies mit dem type “text” möglich.
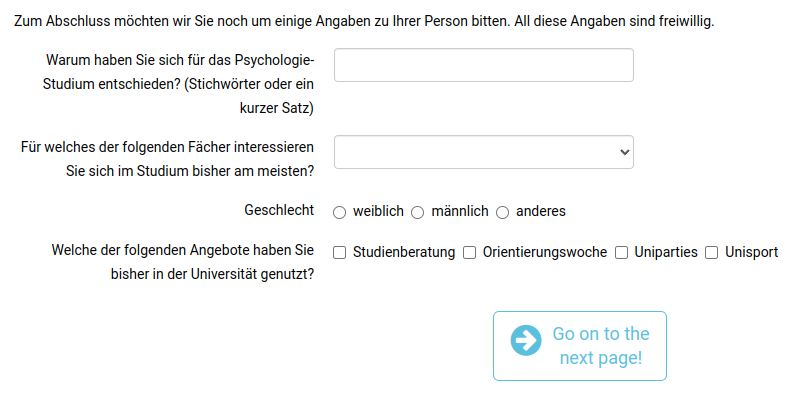
Bei dem type “select_one” kann aus einem Dropdown-Menü an Antwortmöglichkeiten, die wieder in den choice1, choice2, … -Spalten festgehalten werden, gewählt werden.
In der unteren Abbildung kommt außerdem wieder der type “mc” vor, der bei Single Choice Items verwendet wird. Hier kann also nur eine einzige Antwortmöglichkeit ausgewählt werden. Mit dem type “mc_multiple” werden hingegen Multiple Choice Items generiert, das heißt, mehrere Antwortmöglichkeiten können ausgewählt werden.

Der Fragebogen sieht an dieser Stelle also folgendermaßen aus:
Weitere mögliche Optionen für type, um die Art der Items zu ändern, sind hier zu finden.
Wer aufgepasst hat, dem ist aufgefallen, dass in dem zuletzt abgebildeten Spreadsheet-Abschnitt, auch in Spalte optional Einträge standen. In dieser Spalte können wir mit “*” deutlich machen, dass das Item nicht beantwortet werden muss. Das Item wird dann im Fragebogen als “optional” markiert. Alternativ kann unter optional auch definiert werden, dass das Bearbeiten eines Elementes für alle nachfolgenden Elemente erforderlich ist. Dafür kann man in die Spalte optional ein Ausrufezeichen (!) einsetzen. Das Ausrufezeichen gibt die Notwendigkeit an.
Widmen wir uns nun dem Thema des Consents und damit der Spalte showif. Wir erinnern uns, dass auf der ersten Seite unseres Fragebogens die Einwilligung der Teilnehmenden in die Durchfürhung der Studie und Verarbeitung ihrer personenbezogenen Daten abgefragt wird (bspw. “Ich bin damit einverstanden, dass die erhobenen Daten in anonymisierter Form öffentlich zugänglich gemacht werden.”). Diese Abfrage der Zustimmung ist ein zentraler Bestandteil des Datenschutzrechtes, die gewährleisten soll, dass jede Person selbst bestimmt, wer welche Informationen über sie erhält. Außerdem soll eine informierte Teilnahme an der Studie sichergestellt werden. Im Rahmen des Praktikums halten wir uns natürlich an das Datenschutzrecht - wenn jemand nicht möchte, dass seine/ihre Daten gespeichert und verarbeitet werden, muss der Einwilligung nicht zugestimmt werden. Allerdings kann die Person dann den Fragebogen auch nicht ausfüllen. Wir wollen also einrichten, dass nur bei Zustimmung der Fragebogen angezeigt wird. Dies tun wir mittels der Spalte showif. In diese können wir eine Bedingung eintragen unter der ein Item angezeigt werden soll. Eine Bedingung wird in R-Code formuliert. Wir wollen, dass den Teilnehmenden alle Items unseres Fragebogen nur unter der Bedingung angezeigt wird, dass sie der Datenschutzerklärung auf der ersten Seite zugestimmt haben. In der Zeile unseres Spreadsheets, in der die Zustimmung abgefragt wurde, hatten wir den Variablennamen “check_consent” eingetragen. Wenn hier jemand also das Kästchen anklickt, gilt check_consent == TRUE. In allen darauffolgenden Zeilen muss nun also in der Spalte showif die Bedingung check_consent == TRUE eingetragen werden. Falls euer Item zur Abfrage der Zustimmung anders in name benannt wurde, muss dieser Befehl natürlich angepasst werden.
Eine Möglichkeit, die Einwilligung zu erzwingen, wäre gewesen, in der Zeile, in der der Consent abgefragt wird, ein Ausrufezeichen (!) bei optional einzutragen (statt in allen folgenden Zeilen bei showif “check_consent == TRUE” zu schreiben). Dann würde keine weitere Bewegung entstehen. Allerdings sollten Teilnehmenden nach einer Verabschiedung zumindest auf eine Verabschiedungsseite geleitet werden, weshalb wir das für unsere Fragebögen im Rahmen des Praktikums nicht umsetzen. Eine mögliche finale Tabelle mit Items sieht dann so aus:
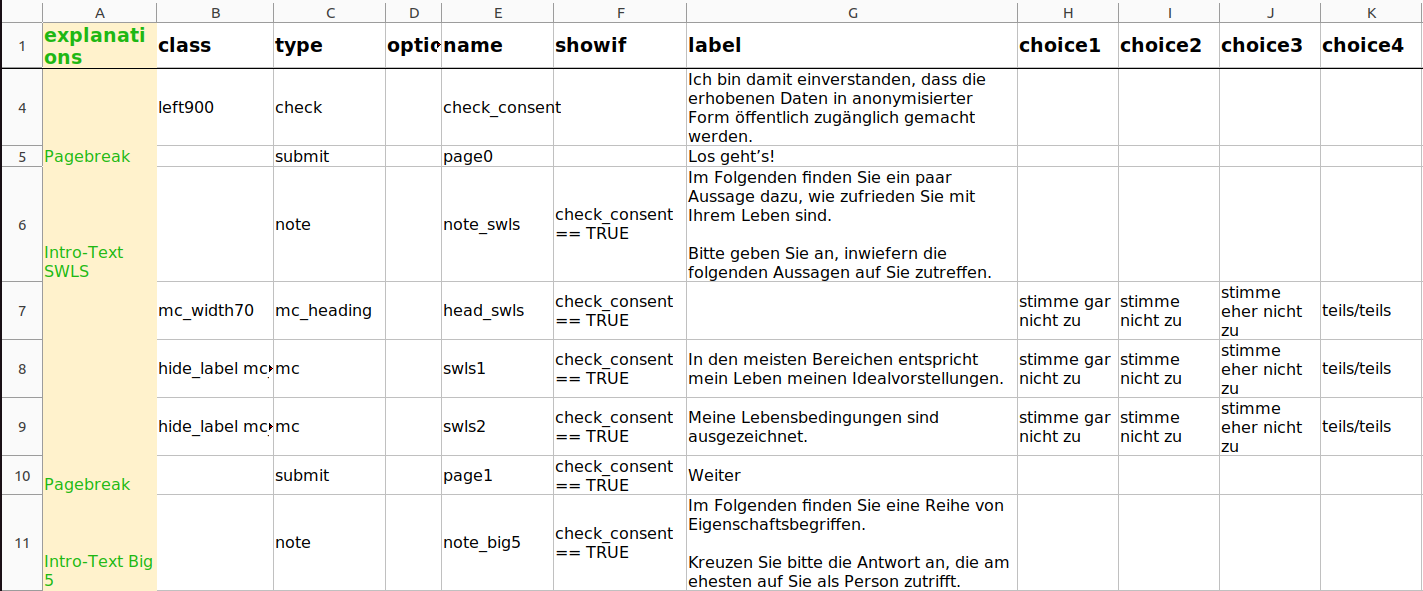
Beachtet, dass wir hier keine Seite zur Verabschiedung erstellt haben, die aber alleine aus Höflichkeit essentiell ist. Diese werden wir direkt ind der formr online-Umgebung erstellen können.
Formatierung des Textes
Sowohl unser Instruktionstext auf Seite 1 als auch der Text im Fragebogen können formatiert werden. Durch die Formatierung wird der Text lesbarer und die wichtigsten Informationen werden hervorgehoben. Dafür können sogenannte präsentationsbezogene Elemente verwendet werden. Diese wurden mit HTML5 eingeführt und können mittlerweile von allen gängigen Browsern interpretiert werden. Text können wir fett (engl. bold) schreiben, indem wir im Spreadsheet <b> vor den fett zu formatierenden Text schreiben und </b> dahinter. Beispielsweise können wir so im Instruktionstext das Wort “freiwillig” hervorheben:


<i> und </i> macht den Text kursiv (engl. italic) und <u> und </u> unterstrichen (engl. underlined). Es ist zu empfehlen, mit den üblichen Formatierungsmöglichkeiten (fett / kursiv) zu arbeiten. Mit <u> sollte sparsam umgegangen werden. Denn üblicherweise sind Hyperlinks – also Verweise auf andere Websites – durch Unterstreichung hervorgehoben.
In Mozzilas Entwickler*innen-Guide ist die Funktionsweise der Formatierungsoptionen wie folgt beschrieben:
<i>kursiver Text wird für folgende Aspekte verwendet: Fremdwörter, Taxonomische Begriffe, Fachwörter, Gedanken[.]
<b>fett-gedruckter Text wird für folgende Aspekte verwendet: Stichwörter, Produktnamen, wichtige Sätze[.]
<u>unterstrichener Text wird für folgende Aspekte verwendet: richtige Namen, Rechtschreibfehler[.]
3. Schritt Survey erstellen
Sind wir nun mit unserem Spreadsheet zufrieden, können wir mit einem Admin-Account bei formr eine neue Umfrage erstellen, indem wir oben rechts auf die Adminansicht klicken. Eventuell seid ihr aber auch direkt bei der Adminasicht - diese ist im übernächsten Screenshot abgebildet.
 Die Adminansicht sieht so aus:
Die Adminansicht sieht so aus:
Hier können wir mit Create Survey neue Umfragen erstellen. Wir gelangen dann auf diese Seite:
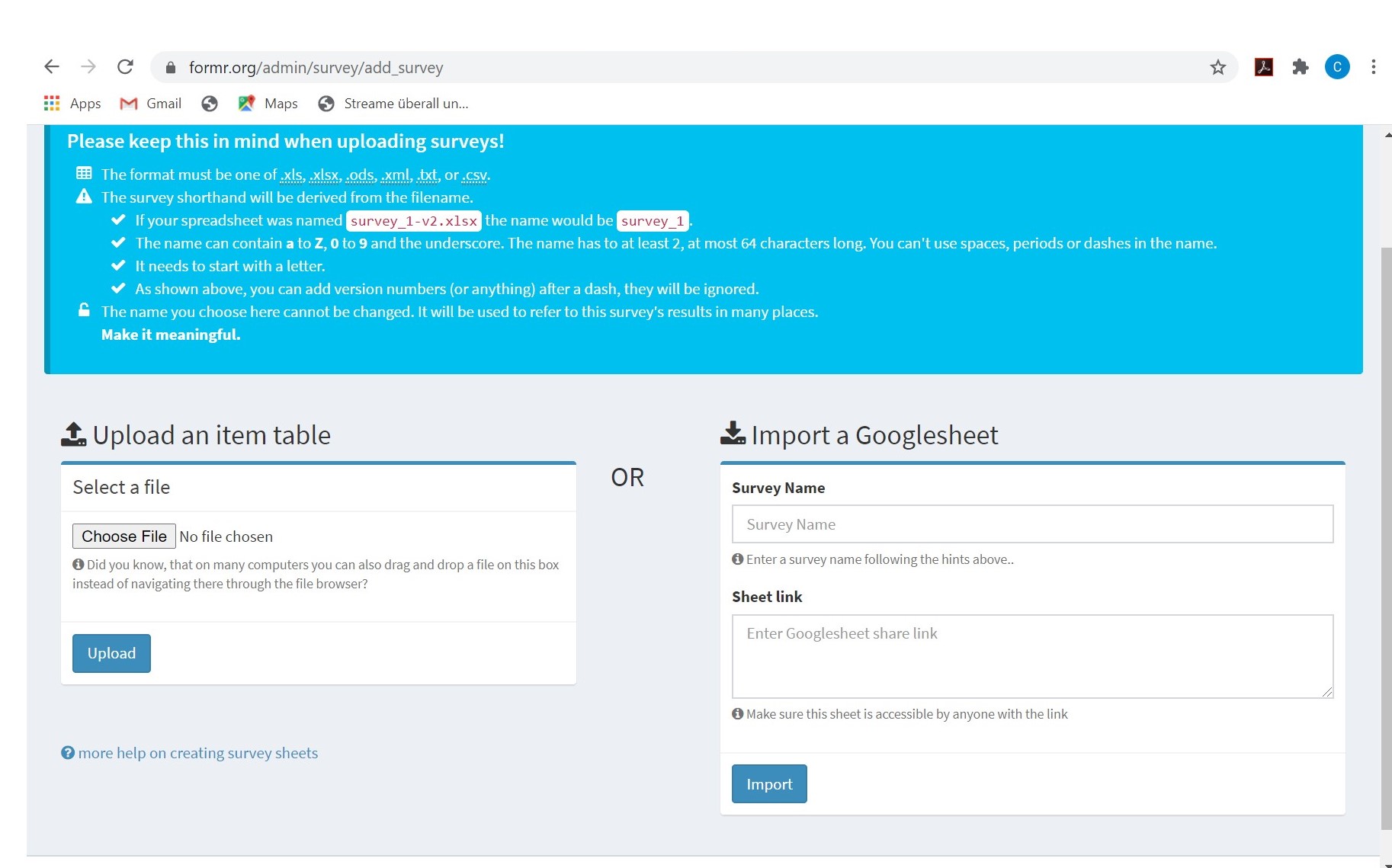
Hier können wir entweder eine Tabelle (links) oder den Link von unserem Google Spreadsheet eingeben (rechts). Der Survey wird den Namen des Spreadsheets übernehmen. Auf dem Bild unten können wir sehen, wie es aussieht, wenn das Hochladen funktioniert hat. Hier wird uns auch angezeigt, dass die explanations (wie angekündigt) ignoriert wurden, da diese nur zur eigenen Orientierung dienen. Auf der linken Seite ist der Button Test Survey. Hier können wir einen Test-Account erstellen, um die Studie zu testen.
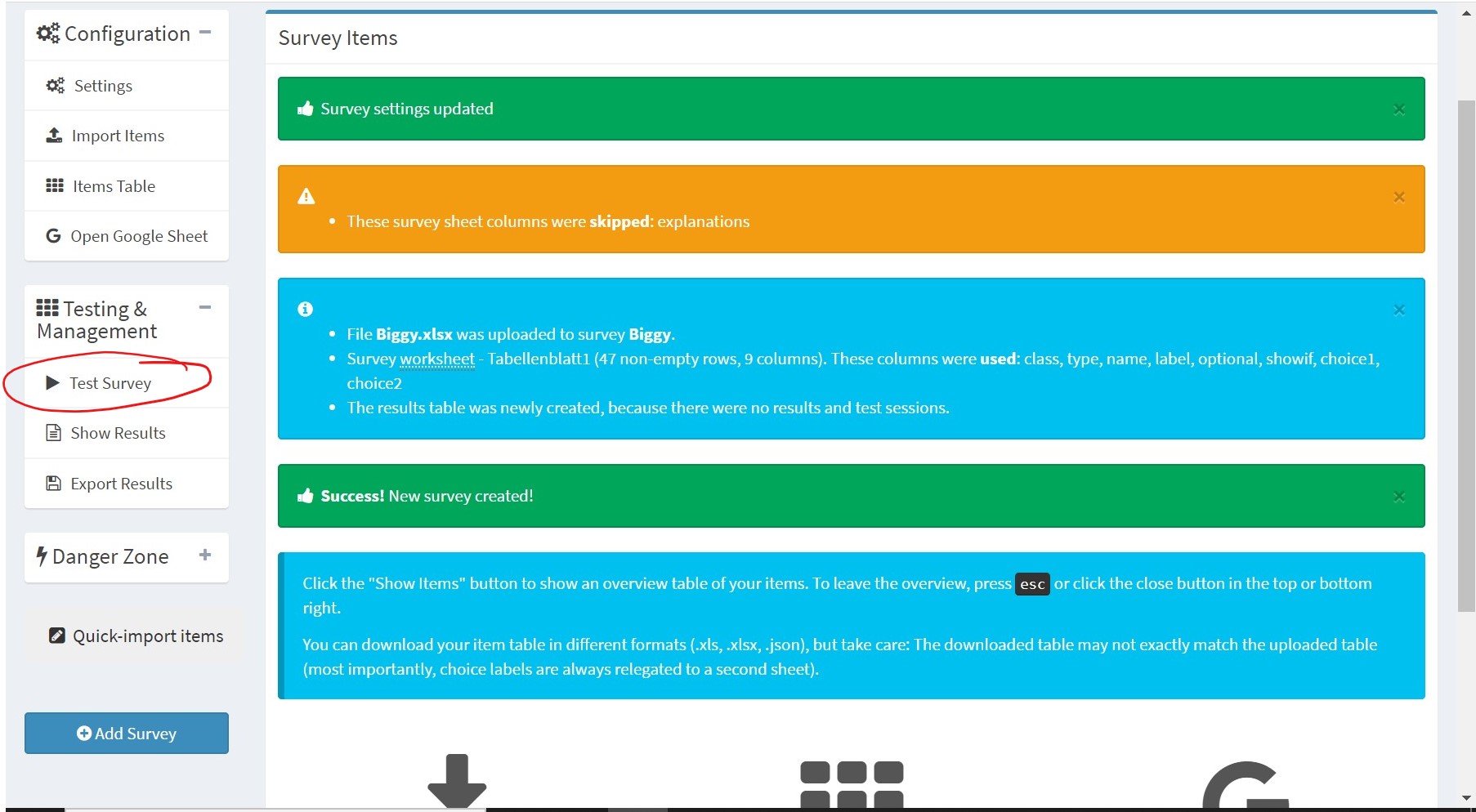
Sollte beispielsweise beim Durchlaufen des Test Survey auffallen, dass die Umfrage noch mancher Änderungen bedarf, kann sie über den Danger Zone-Button auf der linken Seite gelöscht werden. Dann kann das Spreadsheet korrigiert und erneut hochgeladen werden.
4. Schritt Umfrage zu Versuchspersonenminuten (VPM) hochladen und Anonymität sicherstellen
Die Vorlage für die Erhebung der Namen und Email-Adressen, die wir für die Ausstellung der VPM benötigen, sind im Moodle Kurs (der Link führt direkt zum Download, wobei man dafür in Moodle angemeldet sein muss) zu finden. Dieses Sheet müssen wir herunterladen und lokal auf unserem Computer abspeichern. An dem Sheet soll keine Änderung vorgenommen werden - es soll auch nicht einfach in unseren ersten Fragebogen rein kopiert werden. Die Aufteilung in zwei verschiedene Spreadsheets ist essentiell, damit die personenbezogenen Angaben zu den VPM von den Antworten im Fragebogen getrennt werden. Wir müssen also für die VPM-Umfrage ein zweites Survey erstellen. Die Funktionsweise haben wir bereits beschrieben. Um zurück zur Adminansicht zu gelangen, in der der Create Survey-Button angezeigt wird, kann man in der Leiste oben links auf form{'r} klicken.
Um die Anonymität der Teilnehmenden zu gewährleisten, müssen wir zusätzlich noch sicherstellen, dass keine Log-Daten aufgezeichnet werden und die Daten nicht in der gleichen Reihenfolge sind, wie die Daten aus der vorher erstellten Befragung. Um das zu ermöglichen, gehen wir über den Menü-Punkt Surveys zu der Versuchspersonenminuten-Umfrage. Eventuell seid ihr in der daraus folgenden Ansicht aber auch ohnehin gerade drin.
Jetzt müssen wir in die Einstellungen der VPM-Umfrage. Auch dort könntet ihr eventuell schon automatisch sein. Falls dem nicht so sein sollte, nutzen wir links den Button Settings.
Um die Anonymität der Teilnehmenden zu gewährleisten, setzen wir in den Einstellungen das Häkchen bei Unlink Survey und speichern die Änderung. Dies führt dazu, dass die Reihenfolge der Einträge im Datensatz randomisiert wird und wir auch erst Zugriff bekommen, sobald 10 Personen teilgenommen haben.
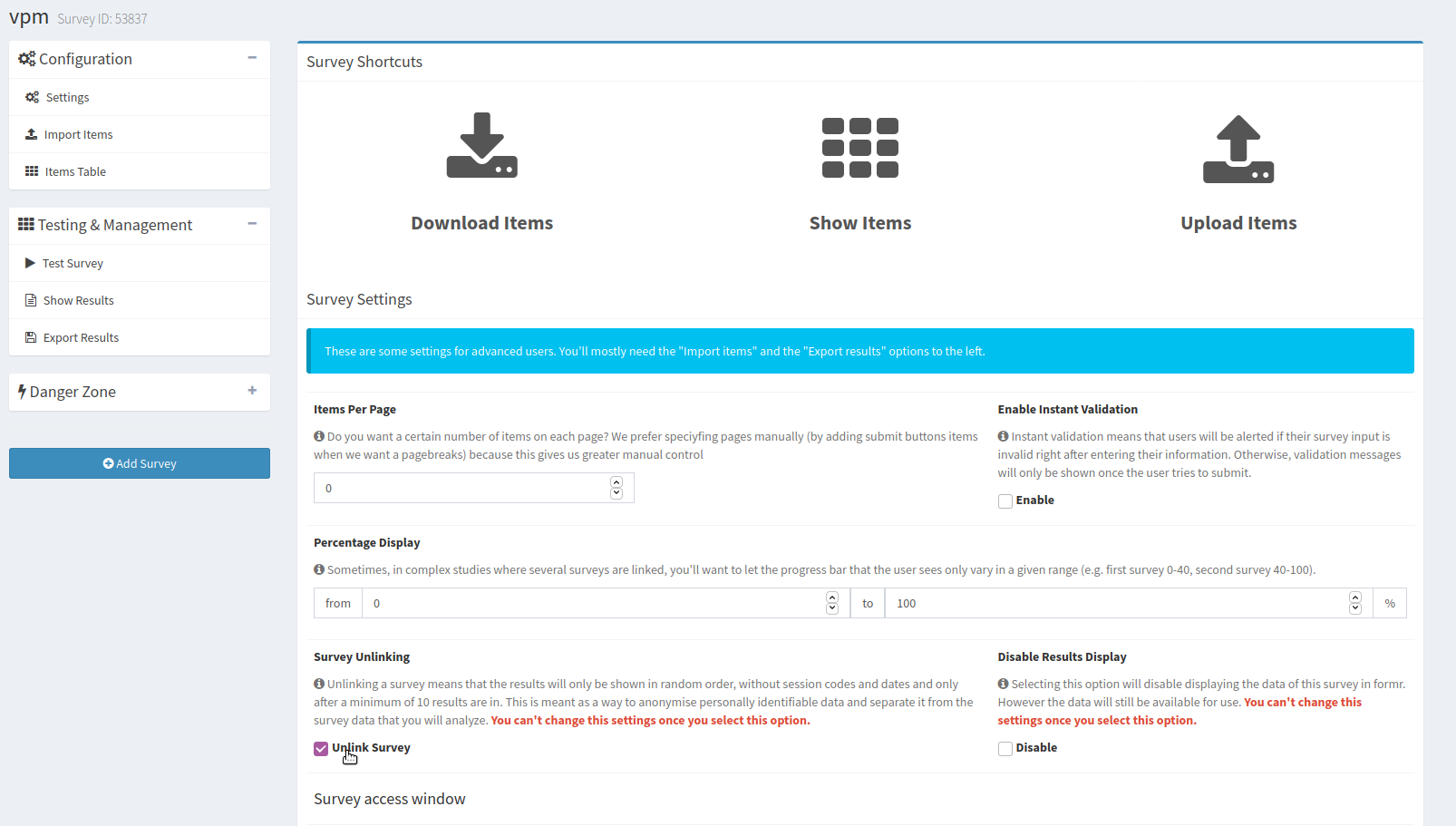
Wir werden hier darauf hingewiesen, dass wir diesen Schritt nicht rückgängig machen können (logisch, sonst könnten wir die Anonymität unserer Teilnehmenden ja im Nachhinein wieder aufheben). Es müssen dann mindestens 10 Personen an unserer Umfrage teilnehmen, bevor wir die Ergebnisse bezüglich der VPM einsehen können.
5. Schritt einen Run erstellen
Für unsere fertige Studie, müssen wir nun einen Run erstellen. Runs sind Zusammenstellungen von mehreren Surveys. Wir benötigen Runs in jedem Fall, um unseren Fragebogen – auch wenn dieser nur aus einem Survey besteht – zu veröffentlichen. Wir können so aber unseren Fragebogen mit der VPM-Abfrage verknüpfen. Weitere Informationen zu Runs und den Modulen eines Runs finden Sie in der formr-Dokumentation. Einen Run erstellen wir, indem wir in der Adminansicht auf Create Run drücken.
Diesem Run müssen wir einen Namen geben, welcher noch nicht vorhanden ist. Anschließend gelangen wir auf die Übersicht unseres Runs.
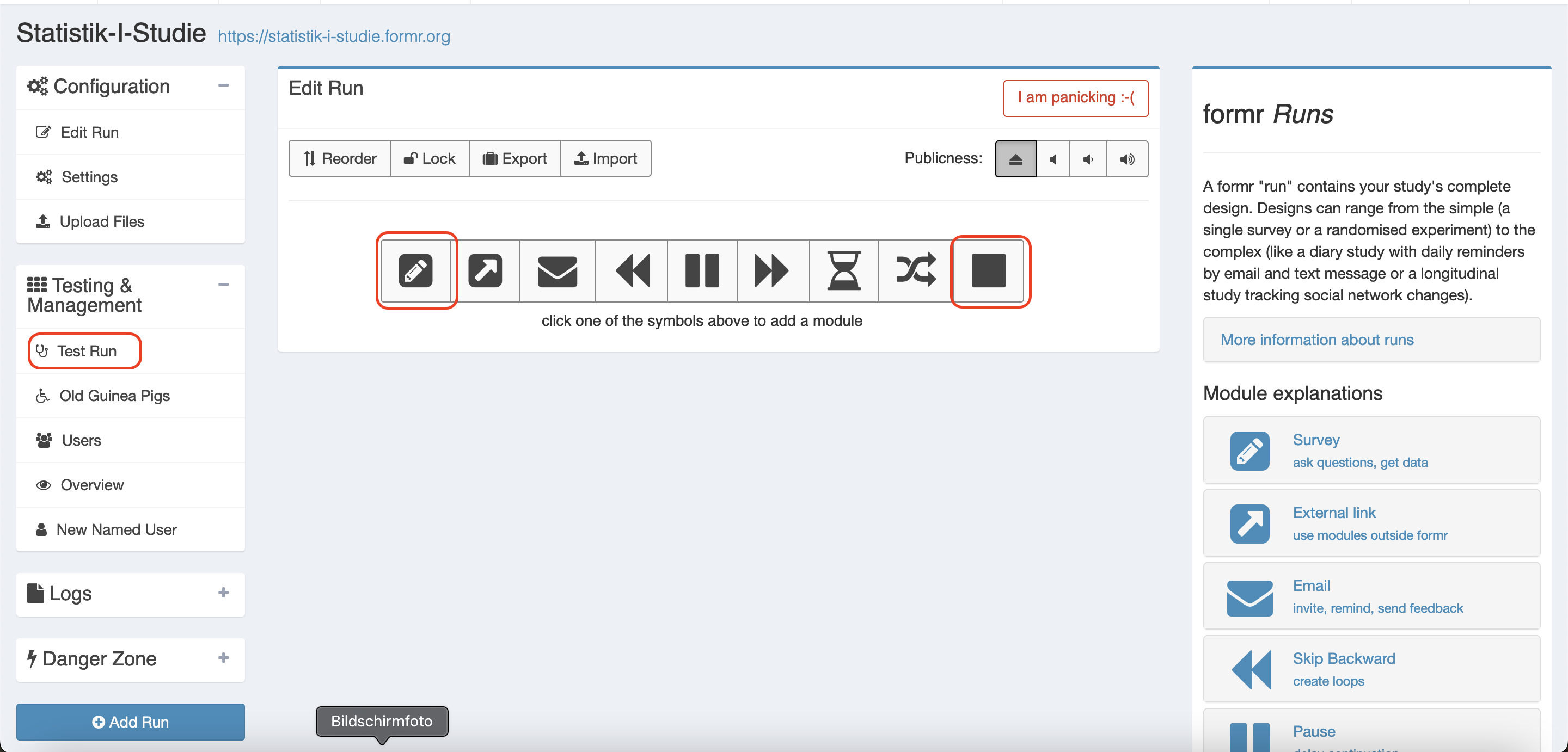
Von diesen Buttons benötigen wir erstmal nur zwei: den ersten und den letzten. Mit dem ersten Button (Add Survey) können wir eine (oder mehrere) Umfrage(n) einfügen, in diesem Fall die Umfrage für das Gruppenprojekt und die VPM-Abfrage. Mit dem letzten Button (Add a stop point) kennzeichnen wir das Ende des Runs beziehungsweise unserer Studie. Hier könnt ihr im Textfeld noch einen Satz schreiben, mit dem ihr euch bei euren Teilnehmenden bedankt und euch verabschiedet.
Von den weiteren Button benötigen wir im nächsten Schritt nur den Button, mit den zwei Pfeilen die nach rechts zeigen (Skip Forward). Dessen Nützlichkeit ist später beschrieben. Die anderen Buttons brauchen wir erstmal nicht, im Folgenden sollen dennoch in aller Kürze ihre Funktionen beschrieben werden: Das zweite Symbol von links, der Pfeil, kann externe Links einfügen und somit auch andere Module miteinbeziehen, wie beispielsweise eine bereits bestehende Umfrage von SoSciSurvey. Mit dem Briefumschlag-Button können wir E-Mails verschicken. Dies ist vor allem bei Langzeitstudien sinnvoll, um die Teilnehmenden an kommende Termine zu erinnern. Mit den Pfeilen können Schleifen erstellt werden, wenn wir z.B. die Stabilität der Big Five herausfinden möchten und dafür ein Jahr lang jeden Monat unsere Probanden einen Big Five Fragebogen ausfüllen lassen möchten. Außerdem können wir auch Pausen und Wartezeiten hinzufügen. Mit dem Shuffle-Button können wir unsere Teilnehmenden randomisieren.
6. Schritt VPM-Abfrage nur bei Consent anzeigen lassen und Fußzeile modifzieren
Im Prinzip ist eure Umfrage jetzt fertig, allerdings wollen wir eigentlich, dass die VPM-Abfrage nur dann ausgefüllt werden kann, wenn der Fragebogen tatsächlich auch bearbeitet wurde. Das wiederum ist dann der Fall, wenn ganz zu Beginn der Umfrage die Consent-Box angeklickt wurde. Ansonsten soll man direkt zur letzten Seite geleitet werden.
In formr kann man mit der “Skip Forward” Funktionalität einstellen, dass unsere Teilnehmenden unter bestimmten Bedingungen im Run springen. Mithilfe dieser Funktion bearbeiten wir unseren Run also nochmal. Zunächst fügen wir einen Jump zu unserem Run hinzu. Diesen möchten wir an zweiter Stelle, also nach dem Fragebogen stehen haben. Um die Reihenfolge der Buttons zu ändern, muss die Zahl, die unter den Buttons steht, einfach nach oben oder nach unten geregelt werden. Vermutlich hat euer Fragebogen hier die Zahl 10 stehen, es genügt also, wenn wir dem Skip-Button die Zahl 11 geben, damit er an zweiter Stelle steht. Wichtig ist, die Änderung der Reihenfolge mit einem Klick auf den blauen Reorder-Button über der ersten Survey, zu speichern. Beim Skip-Button fügen wir nun ein, dass unter der Bedingung, dass im Fragebogen Einwilligung gegeben wurde, ein Sprung zur VPM-Abfrage stattfinden soll, die an der Position 20 steht. Wenn euer Fragebogen also beispielsweise den Namen “fb22” hat, dann steht hier folgende Bedingung:
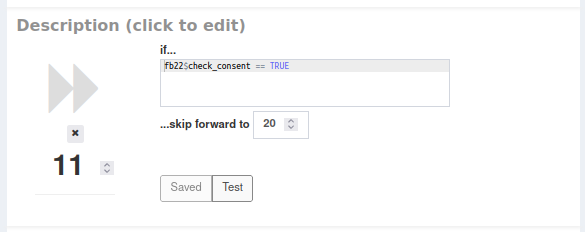
Die Teilnehmenden die der Datenschutzerklärung also zugestimmt und den Fragebogen ausgefüllt haben, werden zur VPM-Abfrage geschickt. Für die, die nicht zugestimmt haben, soll die Umfrage jetzt schon enden. Wir fügen also noch einen Stop-Button ein und ordnen ihn hinter dem Jump-Button (und natürlich vor der VPM-Abfrage) ein, indem wir ihm beispielsweise den Rang 12 zuordnen. Auch bei diesem Stop-Button können wir noch ein paar verabschiedende Worte in das Textfeld schreiben und eventuell erklären, warum keine VPM vergeben werden können.
Insgesamt könnte unser Run jetzt also so aussehen:
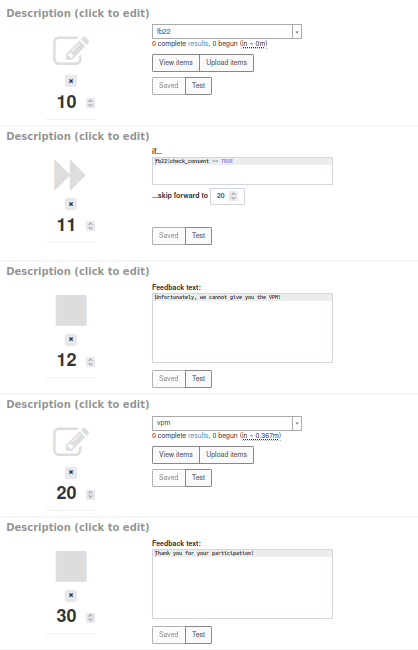
Nach der Implementierung dieser Lösung sollte dringend nochmal die Funktionstüchtigkeit in einem Test-Run überprüft werden. Am besten gehen wir dabei beide Optionen durch: Was passiert, wenn die Consent-Checkbox nicht angeklickt wurde? Kann der Fragebogen dennoch fortgesetzt werden? Landen wir bei fehlendem Consent direkt bei der Verabschiedungsseite und werden bei vorhandenem Consent die VPM noch abgefragt? Damit bei einer solchen Überprüfung des Fragebogens keine Daten gespeichert werden, nutzen wir die “Test Run”-Funktion, die auf der linken Seite zur Verfügung gestellt wird.
Nachdem ihr euren Run kreiert habt, muss noch eine Kleinigkeit erledigt werden: Auf der linken Seite finden wir unter Configuration die Settings. Hier befindet sich unter Footer text ein Textfeld, in das ihr die Fußzeile eurer Umfrage schreiben könnt. Den vorgeschriebenen Text könnt ihr auch einfach übernehmen, allerdings müsst ihr die Beispiel-Email-Adresse (email@example.com) noch durch die Email-Adresse einer Person aus eurer Gruppe ersetzen und die Instruktion (“Remember to add your contact info here!”) herauslöschen. Anschließend müssen die Änderungen noch gespeichert werden.
7. Schritt Studie veröffentlichen
Um die Umfrage zu verschicken, müssen wir sie zunächst öffentlich machen, indem wir oben rechts bei publicness auf “öffentlich” stellen. Den Link findet man oben links direkt neben der Überschrift. Mit diesem Link gelangen Proband*innen direkt zur Umfrage.

8. Schritt Daten herunterladen
Um die Ergebnisse unserer Umfrage herunterzuladen, können wir nicht die Daten unseres Runs auf einen Schlag herunterladen, stattdessen müssen die Daten der Surveys, aus denen unser Run besteht, einzeln heruntergeladen werden.
In unserer Ansicht navigieren wir also zunächst zum interessierenden Survey.
formr bietet zwei Möglichkeiten Ergebnisse aus Surveys herunterzuladen.
Für die erste finden wir unter dem Seitenreiter “Testing & Management” den Menüpunkt “Export Results”.
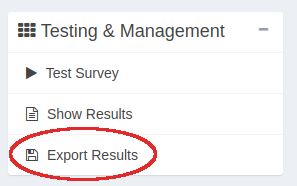
Dieser erlaubt uns die Ergebnisse in verschiedenen Formaten herunterzuladen - unter anderem im verbreiteten .csv Format. Wie Daten aus diesem Format importiert werden können, hatten wir bereits in der Einführungssitzung gesehen.
Der Nachteil dieses Vorgehens ist, dass wir uns auf eine statische Fassung der Daten einlassen müssen. Besonders wenn Sie bereits während der Erhebung damit beginnen wollen, Auswertungsskripte zu verfassen kann es aber besser sein, die Daten direkt von formr in R herunterzuladen. Der Prozess, der hier beschrieben wird, wird z.B. auch in der Statistikvorlesung für die Folien, die Beispiele enthalten, die direkt während der Sitzung erhoben werden, genutzt. Es muss allerdings beachtet werden, dass die Installation nicht simpel ist und einige Fehler auftreten können.
formr bietet für verschiedene Bonusfunktionalitäten das R-Paket formr an. Ein paar einführende Worte dazu finden Sie in der offiziellen Dokumentation. Leider wird das Paket derzeit (noch) nicht über CRAN vertrieben, sodass wir es nicht direkt mit install.packages installieren können, sondern die aktuelle beta-Version von GitHub nutzen müssen. Dafür sind auf Windows Rechnern einige vorbereitende Schritte nötig:
# installr-Paket für einfaches installieren
install.packages('installr')
# Rtools installieren
installr::install.Rtools()
# devtools installieren
install.packages('devtools')Wer ein MacBook oder irgendeinen anderen Rechner mit UNIX-basiertem Betriebssystem nutzt, kann die ersten beiden Schritte umgehen und einfach direkt mit install.packages('devtools') beginnen.
Mit dieser Voraussetzung können wir dann das formr-Paket installieren und laden:
# Von GitHub installieren
devtools::install_github('rubenarslan/formr')# Paket laden
library(formr)## Error in library(formr): es gibt kein Paket namens 'formr'Das Paket enthält die formr_connect() Funktion, mit der wir R mit unserem formr Account verbinden können:
formr_connect()
Enter your email:
Enter your password:Zu diesem Zweck müssen wir einfach der Aufforderung von R folgen und E-Mail-Adresse sowie Passwort unseres formr-Accounts angeben.
Wenn wir die Verbindung hergestellt haben, können wir formr_raw_results() nutzen, um Daten direkt herunterzuladen. Dafür benötigt die Funktion lediglich den Namen unseres Surveys in Anführungszeichen als Argument (im Beispiel ist der Name des surveys fb22).
formr_raw_results('fb22')Die Daten aus dem Gruppenprojekt brauchen wir für den Bericht; diese müssen natürlich noch ausgewertet werden. Mit den Daten aus der VPM Umfrage, die wir ebenfalls als Survey in unseren Run integriert hatten, müssen wir nicht mehr allzu viel machen. Nach dem Abschluss der Umfrage speichern wir den Datensatz der VPM Umfrage - wie oben beschrieben über “Export Results” - unter einem geeigneten Namen ab (Name_der_Studie_Dozentin_des_Praktikums.csv z.B Extraversion_Bildschirmzeit_Schultze.csv). Dann senden wir den Datensatz per Mail an Hasti Rouchi. Auch dieser Schritt ist wichtig für die Erfüllung der Studienleistung.
FAQ
In diesem FAQ (“frequently asked questions”) finden Sie die Antworten auf weitere Fragen im Umgang mit formr. Die Fragen stammen in dieser oder in ähnlicher Form von Studierenden und wurden im Wintersemester 2021/2022 gesammelt. Sie sind aber für die einfache Erstellung einer Umfrage nicht essentiell.
Dieses FAQ wird regelmäßig um neue Fragen ergänzt.
Ich erhalte eine unspezifische Fehlermeldung. Woran kann das liegen?
Dies kann zahlreiche Gründe haben. Prüfen Sie bitte die folgenden Gegebenheiten:
- Leerzeichen in den Variablennamen in der Spalte
namesind unzulässig. Eine Variable “college entrance credentials” führt entsprechend zu einem Import-Fehler. Benennen Sie die Variable z. B. um zu “college_entrance_credentials”. R erlaubt ebenfalls keine Leerzeichen in Variablennamen. - Umlaute, Interpunktion und sonstige Sonderzeichen sind ebenfalls unzulässig. Der Variablenname “Einführung” führt wegen des Umlautes zu einer Fehlermeldung beim Import.
- Ihre Variablennamen bzw. Elementnamen in der Spalte
namemüssen eindeutig sein (im Fachjargon spricht man auch von diskret oder eineindeutig). Haben Sie bereits eine Variable “extraversion”, so können Sie kein zweites Element mit diesem Namen versehen. Normalerweise werden die Variablennamen für einzelne Items zu einem Konstrukt deshalb nach dem Schema “extra1”, “extra2” etc. benannt. - Haben Sie in Ihrem Fragen gleich viele
choice-Optionen vergeben, wie Sie Antwortmöglichkeiten haben. Sollten Sie bspw. eine Sieben-Punkte-Likert-Skala haben, allerdings nurchoice1bischoice6als Spaltennamen in der Tabelle haben, führt dies zu einem Fehler beim Import. Umgekehrt ist es nicht schlimm, wenn die Spaltechoice6existiert, obwohl Sie eine Fünf-Punkt-Likert-Skala verwenden. - Kontrollieren Sie, ob Ihre Tabelle weitere Tabs (unten links) hat. Standardmäßig sollten sich dort nur zwei Tabs
surveyundchoicesfinden (siehe auch “Was ist einechoices_listund wofür nutze ich diese?”). - Speichern Sie Ihre Tabelle in einem zeitgemäßen Dateiformat. Das XLS-Format ist veraltet. Ich empfehle Ihnen, die Datei als Excel-Arbeitsmappe im XLSX-Format zu speichern. Dafür gehen Sie bitte auf “Datei” und dann auf “Speichern unter”. (Auf Windows ist das entsprechende Tastenkürzel F12.) Wählen Sie anschließend im Speichern-Dialog unter “Dateiformat” die Option “Excel-Arbeitsmappe (.xlsx). Geben Sie Ihrer Datei einen Namen ohne Leer- und Sonderzeichen, z. B.”survey.xlsx”. Alternativ können Sie Ihre Tabelle über Google Spreadsheet erstellen und von dort über die URL in formr importieren; dies hat zahlreiche Vorteile.
- Für die Spalte
typemuss ein Leerzeichen zwischen dem Typ-Namen und etwaigen Argumenten, z. B.number 1,130,1(bedeutet: Auswahl eine ganzzahlige Nummer im Bereich zwischen 1 und 130). Die Eingabenumber1,130,1ohne Leerzeichen kann zu einem Fehler beim Import führen. - Die zu importierende Datei darf in Ihrem Namen ebenfalls keine Leerzeichen haben. Ein Dateiname wie “tabelle 1.xlsx” kann zu einem Fehler beim Import führen. Verwenden Sie anstelle von Leerzeichen Unterstriche, z. B. “tabelle_1.xlsx”.
Was ist eine choices_list und wofür nutze ich diese?
Das Argument choice_list für den Typ mc gibt den Namen eines weiteren Spreadsheets bzw. in den Haupt-Spreadsheet integrierten Tabs an, in dem Antwortmöglichkeiten gebündelt werden können. Auf diese Weise müssen nur einmal die Antwortmöglichkeiten definiert werden. Anschließend können Sie auf die gleiche Liste mit Antwortmöglichkeiten mehrfach zurückgreifen.
In dem Beispiel-Spreadsheet finden Sie unten links den entsprechenden Tab:
choices ist der Default-Name des Tabs, in dem sich die Antwortmöglichkeiten findet. Dieser wiederum sieht so aus:
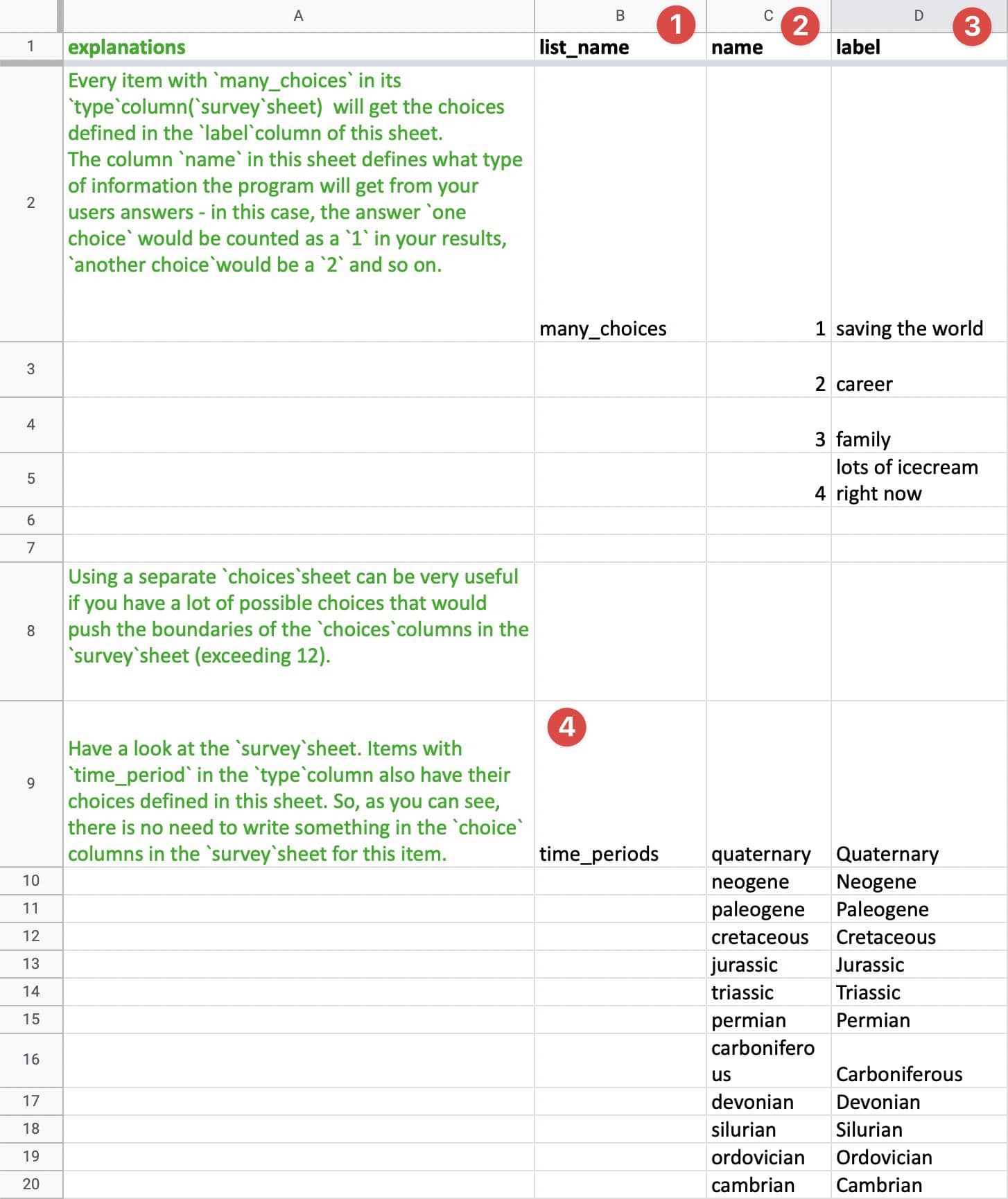
Bei (1) geben Sie den Namen Ihrer Liste an (in Ihrem Fall “many_choices” und darunter “time-periods”). Für die Spalte name unter Punkt (2) folgen die Variablen, die in den Datensatz geschrieben werden sollen. In die Spalte label unter Punkt (3) kommt die Bezeichnung, die den Proband*innen im Fragebogen angezeigt wird. Ab Zeile 9 beginnt bei Punkt (4) eine zweite Liste mit Antwortmöglichkeiten, die den list_name “time_periods” trägt.
Im Fragebogen finden sich folglich für die Liste “many_choices” vier kategorische Antwortmöglichkeiten mit den Namen “saving the world”, “career”, “family” und “lots of icecream right now”, die jeweils durch die Zahlen 1, 2, 3, und 4 kodiert sind. Gibt jemand bspw. im Fragebogen “family” an, wird in den Datensatz eine 3 geschrieben. In diesem Sinne ist diese Liste mit Antwortmöglichkeiten wie ein Variablenschlüssel. Für die Liste “time_periods” wiederum, werden ganze Strings wie “quaternary” in den Datensatz geschrieben. Als Strings werden in der Informatik Buchstabenabfolgen bezeichnet. So sind bspw. a, b und c isoliert betrachtet Character. Zusammengeführt als abc ergeben sie allerdings einen String. Etwas missverständlich ist, dass in R Strings häufig den Datentyp character annehmen. R unterscheidet nicht zwischen einem Character und einem String.
Wie ist mit invertierten Items umzugehen?
Invertierte Items haben eine andere Polung als nicht-invertierte Items. Sie können Sie sich dies dadurch verbildlichen, dass die Skala wie ein Zahlenstreifen an der y-Achse gespiegelt wird:

Invertierte Items müssen in der Auswertung wieder in die ursprüngliche Polung revertiert werden. Dies kann mittels linearer Transformation geschehen:
Bei der Erhebung invertierter Items wird empfohlen, die Invertierung in die Anmerkungen in der Spalte explanation zu schreiben, damit diese nicht bei der Auswertung übersehen werden. Alternativ können die Variablennamen mit einem Suffix wie “invers” versehen; dies verlängert allerdings die Variablennamen und erhöht damit die Wahrscheinlichkeit, sich bei der Eingabe dieser zu verschreiben.
Mein Datensatz sieht nicht aus, wie ich es erwartet habe. Was tun?
Dieses Problem hat meist damit zu tun, dass Ihr Datensatz im Long-Format vorliegt. Im Long-Format sind Ihre Variablen alle in einer Spalte gesammelt und jede Versuchsperson nimmt so viele Zeilen ein, wie der Datensatz über Variablen verfügt.
Long-Format:
| VP | Variable | Answer |
|---|---|---|
| VP1 | Extra1 | 3 |
| VP1 | Extra2 | 4 |
| VP1 | Extra3 | 3 |
| VP1 | Vertr1 | 5 |
| VP1 | Vertr2 | 4 |
| … | … | … |
Im Wide-Format hingegen wird jede Versuchsperson durch eine Zeile repräsentiert und die Variablen sind spaltenweise angeordnet. Dieses Format ist üblicher und vor allem übersichtlicher. Dennoch wird hin und wieder das Long-Format benötigt (z. B. für die ezANOVA()-Funktion, mit der Sie sich im Rahmen von Statistik II vertraut machen).
Wide-Format:
| VP | Extra1 | Extra2 | Extra3 | Vertr1 | Vertr2 | … |
|---|---|---|---|---|---|---|
| VP1 | 3 | 4 | 3 | 5 | 4 | … |
| … | … | … | … | … | … | … |
Damit Sie wie gewohnt mit dem Datensatz umgehen können, müssen Sie ihn ins Wide-Format transponieren. Zur Veranschaulichung nutzen wir einen Beispieldatensatz, den R uns bereitstellt:
data(sleep)
sleep## extra group ID
## 1 0.7 1 1
## 2 -1.6 1 2
## 3 -0.2 1 3
## 4 -1.2 1 4
## 5 -0.1 1 5
## 6 3.4 1 6
## 7 3.7 1 7
## 8 0.8 1 8
## 9 0.0 1 9
## 10 2.0 1 10
## 11 1.9 2 1
## 12 0.8 2 2
## 13 1.1 2 3
## 14 0.1 2 4
## 15 -0.1 2 5
## 16 4.4 2 6
## 17 5.5 2 7
## 18 1.6 2 8
## 19 4.6 2 9
## 20 3.4 2 10Mit ?sleep bekommen wir Zusatzinformationen über die Daten und sehen dort, dass es sich hier um Daten aus einem Experiment handelt, bei dem die Veränderung in den Schlafstunden (extra) von Personen (ID) mit und ohne Schlafmittel (group) festgehalten ist. Dieser Datensatz liegt also im Long-Format vor.
Um den Datensatz aus dem Long- ins Wide-Format zu überführen können wir den Befehl reshape benutzen. Wie man Daten aus dem Wide- ins Long-Format umwandeln kann ist im Beitrag zur Plot-Erstellung in BSc7 dargestellt. Dort haben wir die Argumente des reshape Befehls näher erläutert. Hier die Zusammenfassung:
data: Der Datensatzvarying: Die Variablen die wiederholt gemessen wurdenv.names: Der Name unter dem die Variablen zusammengefasst werden sollentimevar: Die Variable, die Wiederholungen kennzeichnetidvar: Die Variablen, die sich über Wiederholungen nicht änderndirection: Das Zielformat des neuen Datensatzes
Für unseren Fall benötigen wir also:
wide <- reshape(data = sleep,
v.names = 'extra',
timevar = 'group',
idvar = 'ID',
direction = 'wide')und schon haben wir einen Datensatz im Wide-Format:
wide## ID extra.1 extra.2
## 1 1 0.7 1.9
## 2 2 -1.6 0.8
## 3 3 -0.2 1.1
## 4 4 -1.2 0.1
## 5 5 -0.1 -0.1
## 6 6 3.4 4.4
## 7 7 3.7 5.5
## 8 8 0.8 1.6
## 9 9 0.0 4.6
## 10 10 2.0 3.4Ich habe ein Bild in meinen Header eingefügt. Wie bekomme ich dieses kleiner?
Wenn Sie im “Run” unter “Settings” im Tab “CSS” folgenden Code einfügen, wird das Logo klein in die rechte Ecke gelegt:
@media {
img {float: right;
margin: 0px 0px 10px 10px;
height: 7%;
max-height: 100px
}
}Weitere Ressourcen
Für eine globale Übersicht über die Funktionalität von formr empfehlen wir einen Blick auf die offizielle Dokumentation von formr. Eine Möglichkeit, diese Funktionen mal an einem anderen Beispiel auszuprobieren, bietet außerdem unser formr-Projekt.