
Lösungen
Vorwarnung
Achtung! Im Folgenden werden die Lösungen für das dritte Projekt präsentiert. Falls du das Projekt noch nicht vollständig bearbeitet hast, nutze zunächst die Tipps. Sofern dir die Tipps für einen Teil nicht geholfen haben, kannst du die Lösungen benutzen, um einen Schritt weiterzukommen und beim nächsten Abschnitt weiterzumachen.
Datensammlung
Abschnitt anzeigen
Zunächst muss der Chat, wie in der Vorbereitung eingelesen werden.
setwd('...')
install.packages('rwhatsapp')library(rwhatsapp)## Warning: package 'rwhatsapp' was built under R version 3.6.3whatsapp <- rwa_read('MeineGruppe.txt')Wenn du dir nun den Datensatz anschaust (z.B. über View) sollten die ersten sechs Zeilen so aussehen:
## # A tibble: 6 x 6
## time author text source emoji emoji_name
## <dttm> <fct> <chr> <chr> <lis> <list>
## 1 2019-06-23 18:21:21 <NA> "Du hast die Gruppe \"M~ MeineGru~ <NUL~ <NULL>
## 2 2019-06-26 11:49:21 Frank "Wer hat Lust so gegen ~ MeineGru~ <NUL~ <NULL>
## 3 2019-06-26 12:05:21 Marie "Bin raus:/" MeineGru~ <NUL~ <NULL>
## 4 2019-06-26 12:05:21 Hans " Ich bin jetzt schon e~ MeineGru~ <NUL~ <NULL>
## 5 2019-06-26 12:06:21 Georg " Yess, am Cafe dann?" MeineGru~ <NUL~ <NULL>
## 6 2019-06-26 12:09:21 Petra "Ich esse Zuhause" MeineGru~ <NUL~ <NULL>Wenn es bei dir einige Zeilen gibt, die keinen Absender und keine Uhrzeit haben, liegt das daran, dass jemand einen Absatz in seiner Nachricht hatte. Mit which werden hier zunächst alle Zeilen identifiziert, die keine Zeit und keinen Absender haben. Im zweiten Schritt wird die Zeit und der Absender aus der oberen Zeile genommen und in die leeren ersten zwei Spalten eingefügt. Damit wurde eine einzige Nachricht über zwei Zeilen verteilt, was wir für später im Hinterkopf behalten müssen. Wenn das bei dir nicht vorkommt, kannst du diesen Schritt einfach weglassen.
linebreaks <- which(is.na(whatsapp$time) & is.na(whatsapp$author))
for (i in linebreaks) whatsapp[i, 1:2] <- whatsapp[i - 1, 1:2] Der erste der zwei Sonderfälle, sind Nachrichten vom System (wenn jemand der Gruppe beigetreten ist oder sie verlassen hat). Hierfür überschreiben wir unseren Datensatz mit dem gleichen Chat unter Ausschluss der autorenlosen Zeilen. Daher ist es wichtig, dass wir im Schritt vorher die Absätze in den Nachrichten bereinigt haben, um diese richtigen Nachrichten nicht zu löschen.
whatsapp <- whatsapp[!is.na(whatsapp$author),]Der zweite Sonderfall sind die Medien, die wir beim Exportieren aus Whatsapp ausgeschlossen haben. Mit grep können wir die Nachrichten heraussuchen und durch NA ersetzen. Hier muss nicht die ganze Nachricht angegeben werden, da jede dieser Nachrichten gleich aufgebaut ist.
whatsapp$text[grep('<Medien ausgeschlossen', whatsapp$text)] <- NADeskriptives
Abschnitt anzeigen
Falls du ggplot2 noch nicht geladen hast, solltest du es jetzt tun. Falls du dich noch nicht damit beschäftigt hast, wie man mit diesem Paket Grafiken erzeugt, kannst du das z.B. in unserem Minitatur-Crashkurs nachholen.
library('ggplot2')## Warning: package 'ggplot2' was built under R version 3.6.3Unser erstes Diagramm ist ein Kreisdiagramm zur Nachrichtenhäufigkeit der einzelnen Personen. Du brauchst hier den Befehl table damit du die Häufigkeiten der Personen bekommst. Weil der Autor von ggplot2 sich wehement weigert, diese Art von Diagramm direkt zu implementieren, können wir hier den R-eigenen Befehl pie benutzen. Dieser benötigt jedoch als Input eine Häufigkeitstabelle:
tab <- table(whatsapp$author)
tab##
## Anna Anne-Lisa Frank Georg Hans Marie Petra
## 196 33 91 105 95 108 137pie(tab, col = c("red", "yellow", "green", "violet", "orange", "blue", "pink", "cyan") )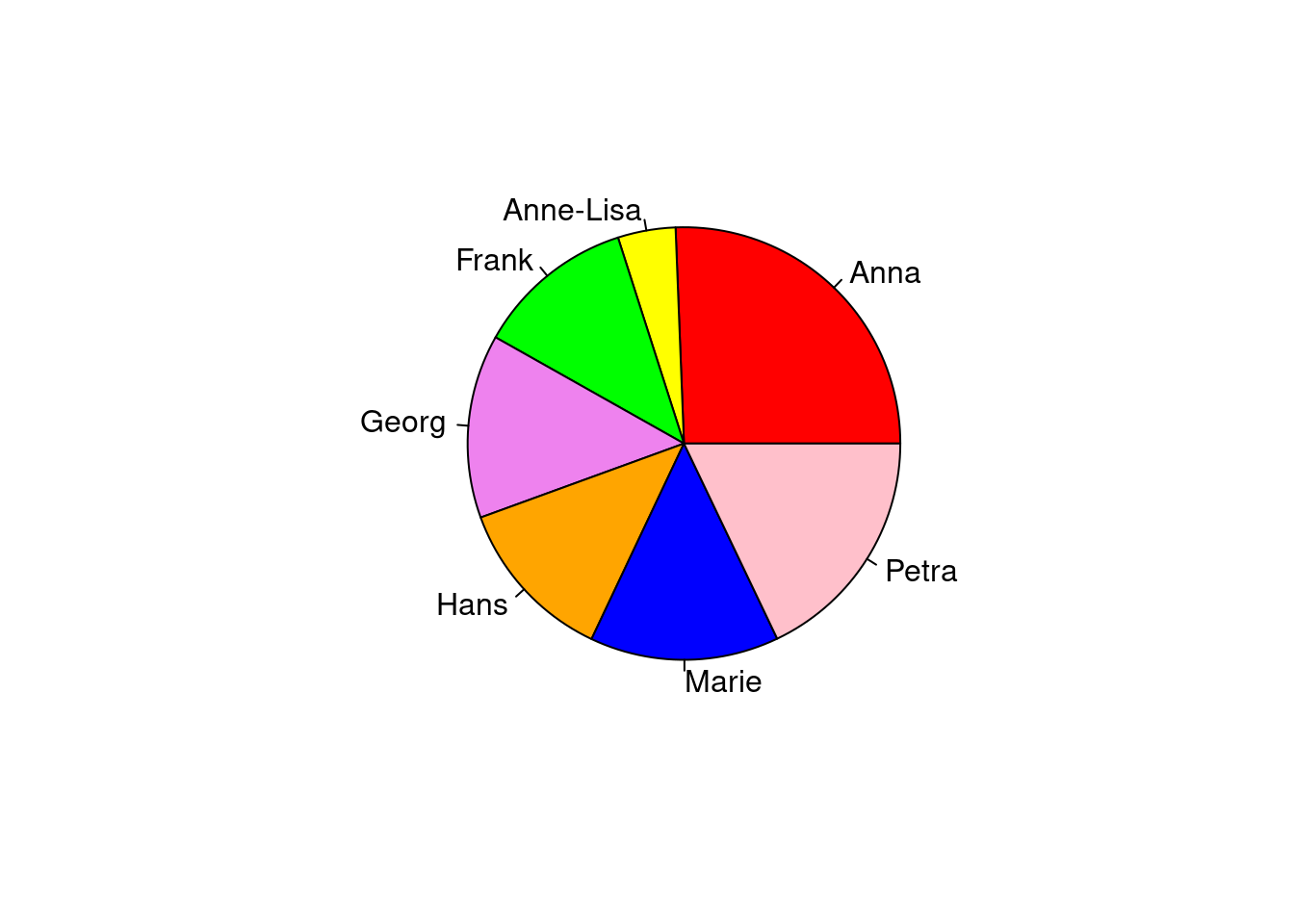
Wenn wir das gleiche mit ggplot machen wollen, müssen wir ein Balkendiagramm benutzten.
ggplot(whatsapp, aes(x = author)) +
geom_bar(width = 1 , aes(fill = author))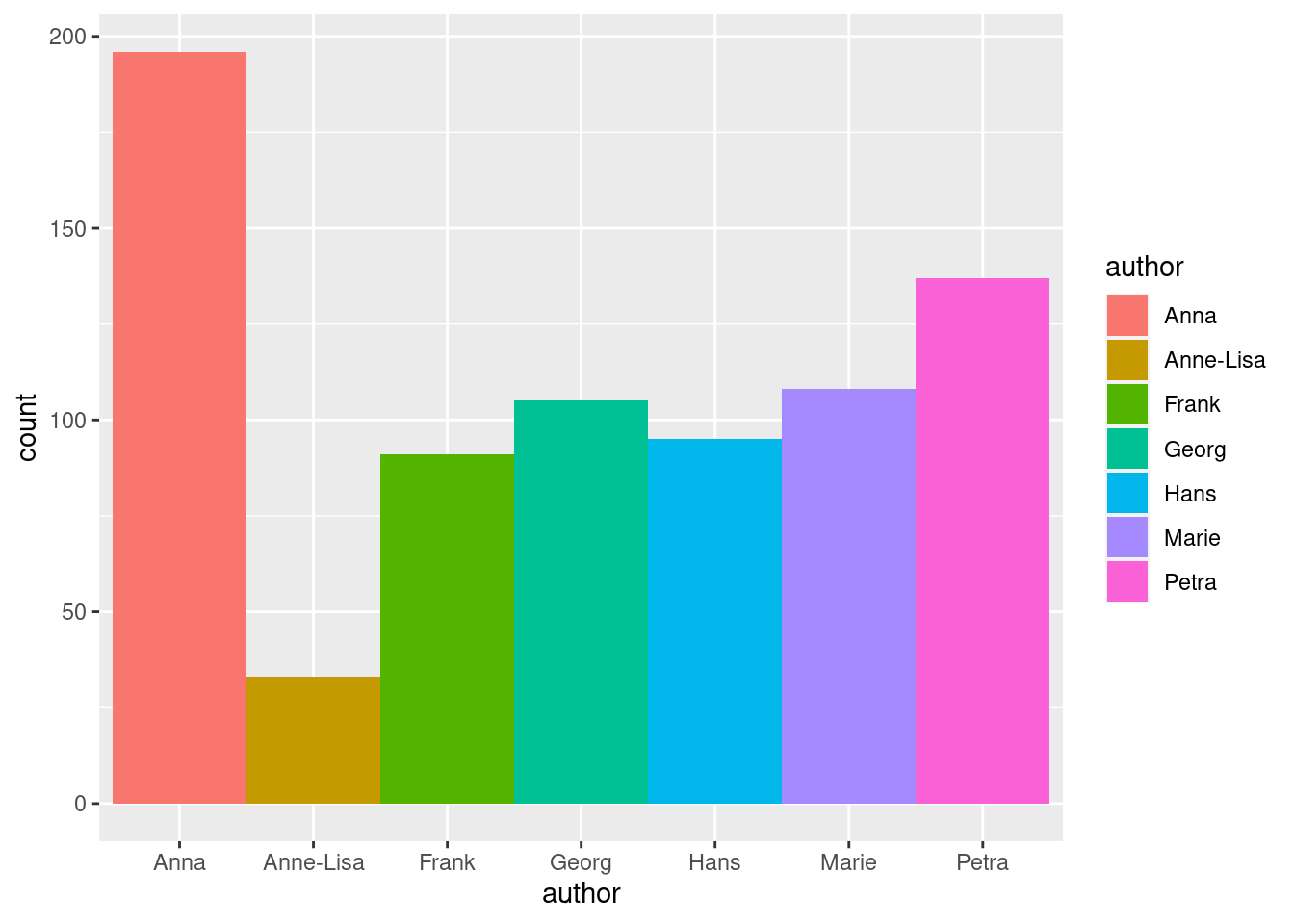
Für ein Histogramm über die gesamte Zeit kannst du es entweder mit der Basicfunktion hist machen oder wieder mit ggplot. Setzte die Balkenbreite so, wie es für dich Sinn macht.
hist(whatsapp$time, breaks = 20, freq = TRUE)## Warning in breaks[-1L] + breaks[-nB]: NAs produced by integer overflow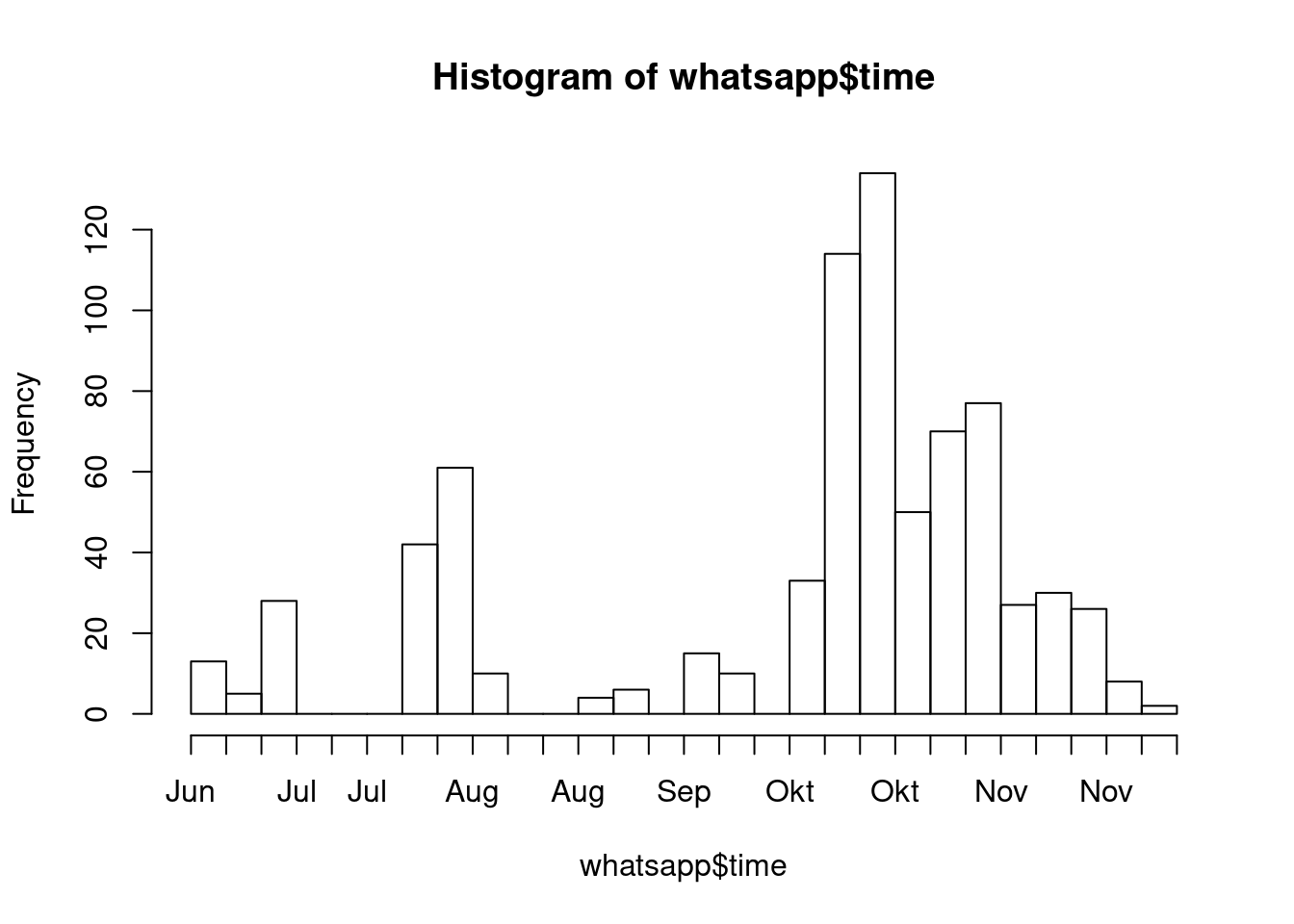
ggplot(whatsapp, aes(x = whatsapp$time))+ geom_histogram()## Warning: Use of `whatsapp$time` is discouraged. Use `time` instead.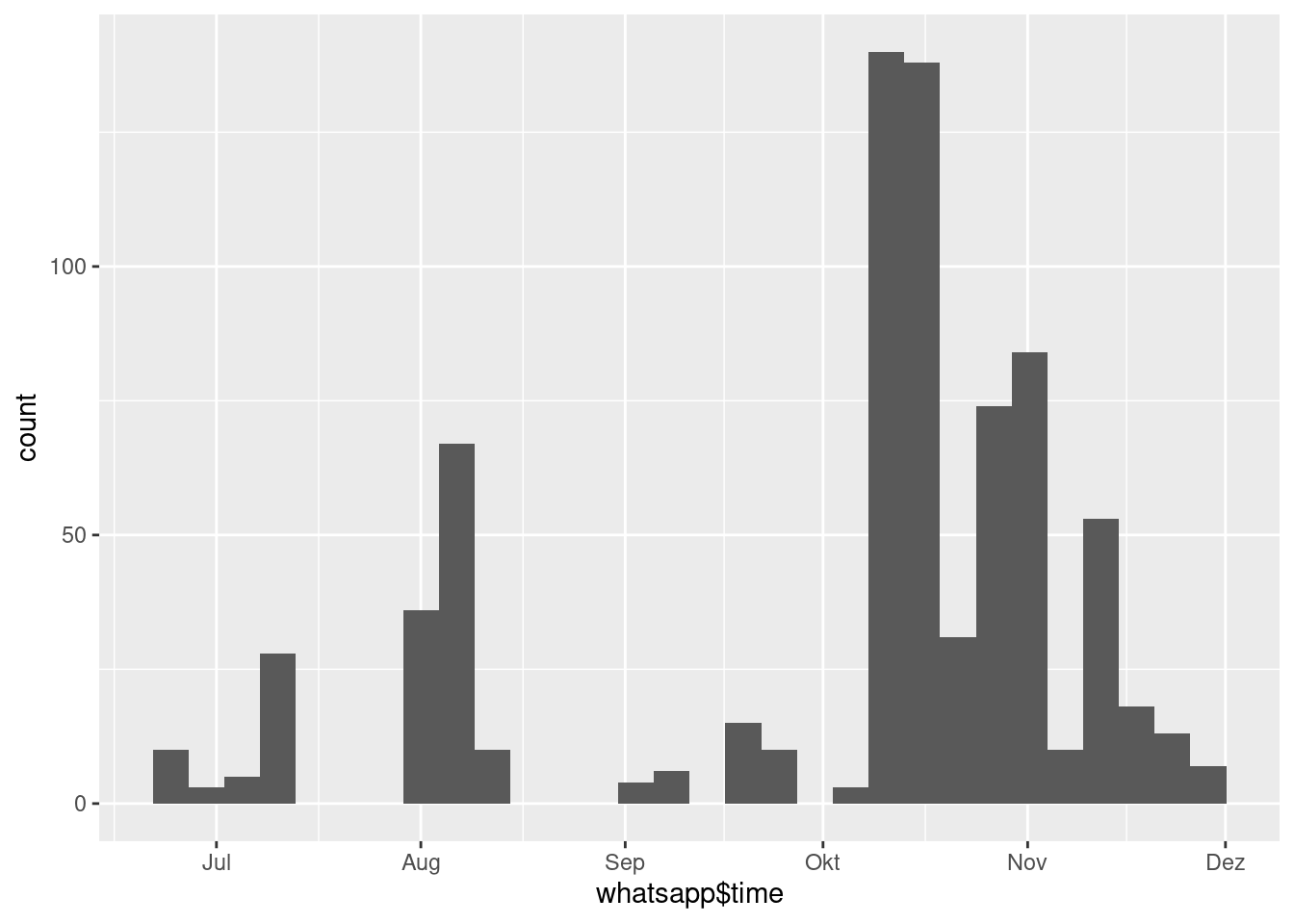
Für die Wochentage gibt es in R den gesonderten Befehl weekdays. Da es wenig Sinn macht, die Wochentage alphabetisch zu sortieren, musst du noch einen Faktor erstellen, in dem du die richtigen Levels zuweist. Da Wochentage nicht intervallskaliert sind, nutzen wir hier ein Balkendiagramm.
whatsapp$Wochentage <- weekdays(whatsapp$time)
whatsapp$Wochentage <- factor(whatsapp$Wochentage, levels = c('Montag','Dienstag', 'Mittwoch', 'Donnerstag', 'Freitag', 'Samstag', 'Sonntag'))ggplot(whatsapp, aes(x = Wochentage)) + geom_bar()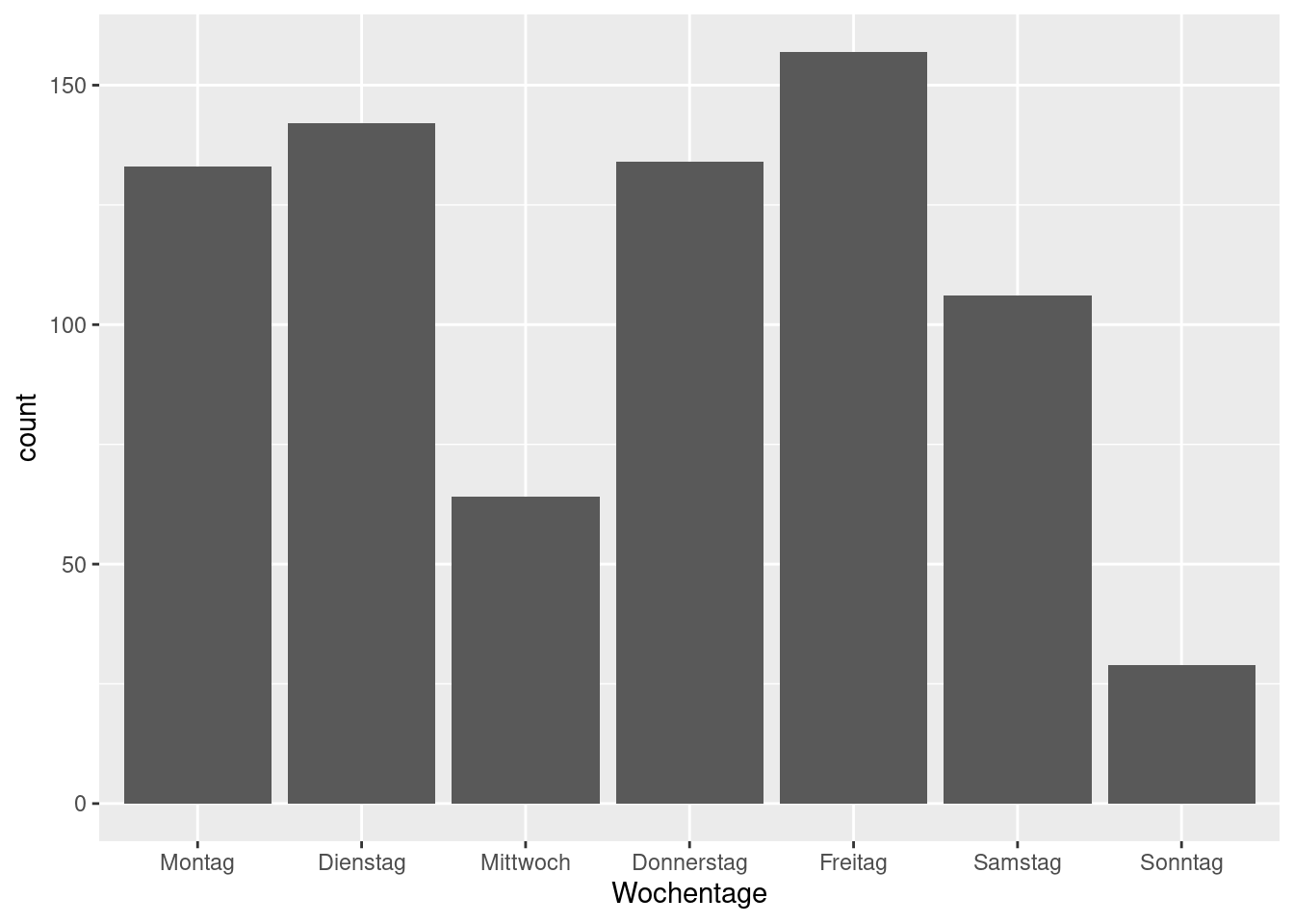
Für die Uhrzeit erstellen wir erst eine neue Zeitvariable ohne das Datum. Leider speichert R die neue Zeitvariable wieder als Character ab, sodass du sie nochmal in POSIXct umformen musst. Zur Visualisierung benutzen wir hier ein Histogramm.
whatsapp$uhrzeit <- strftime(whatsapp$time, format = '%H:%M')
whatsapp$uhrzeit <- as.POSIXct(whatsapp$uhrzeit, format = '%H:%M')
ggplot(whatsapp, aes(x = whatsapp$uhrzeit))+ geom_histogram(bins = 10, color = 'white') +
xlab('Zeit')+ ylab('Nachrichten') + geom_freqpoly(bins = 10) + scale_x_datetime(date_labels = '%H:%M')## Warning: Use of `whatsapp$uhrzeit` is discouraged. Use `uhrzeit` instead.
## Warning: Use of `whatsapp$uhrzeit` is discouraged. Use `uhrzeit` instead.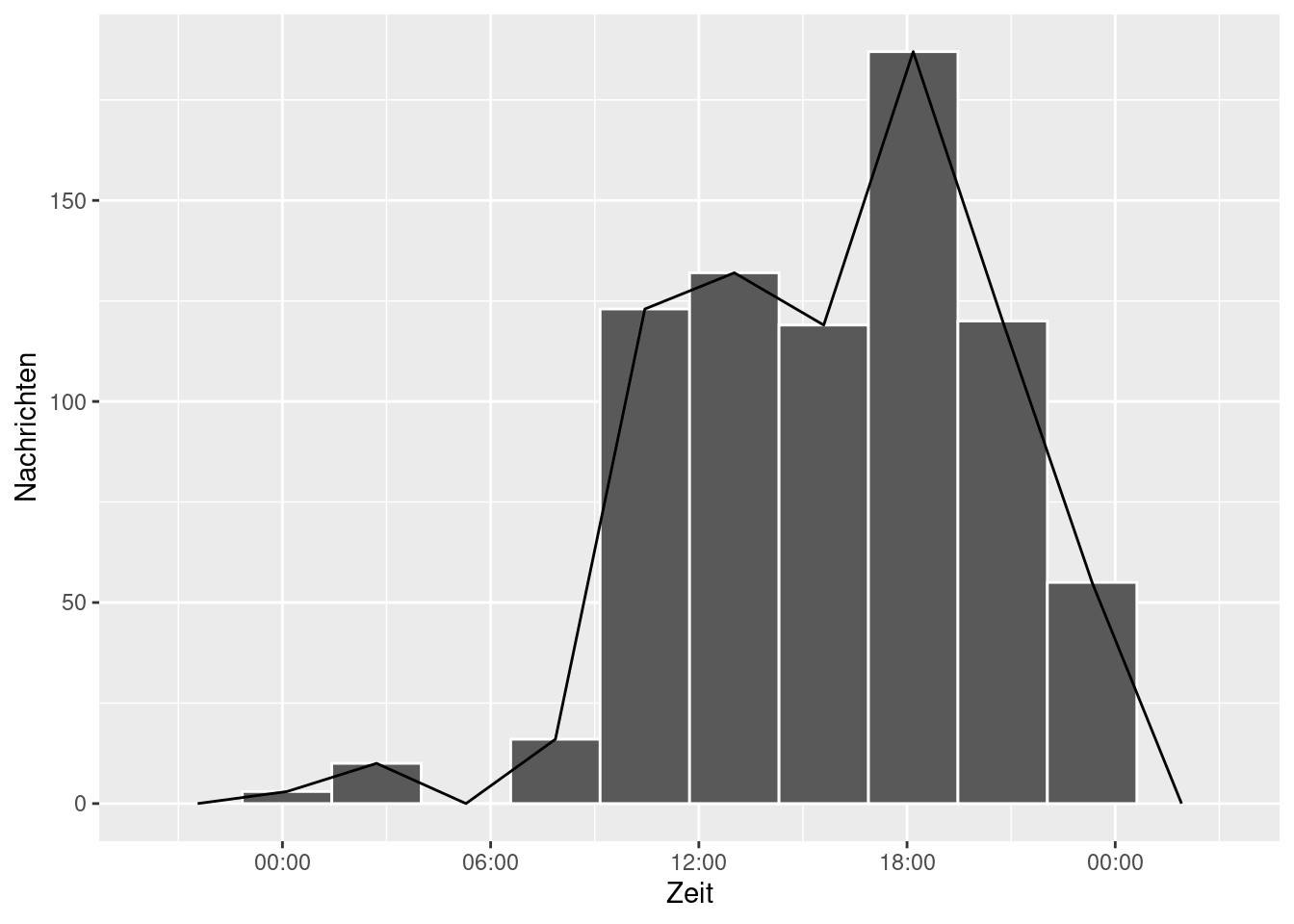
Zeitanalyse
Abschnitt anzeigen
Wir haben uns hier einen zweiten Datensatz erstellt, damit wir zur Not einen weiteren formatierten Datensatz zur Verfügung haben. Damit vermeiden wir, dass wir von Anfang an alles neu einlesen müssen, wenn das Verändern des Datensatzes schief läuft. Das ist generell auch für die Zukunft immer eine gute Idee, wenn du etwas an deinem Datensatz verändern willst, dir aber nicht ganz sicher bist, wie es geht.
whatsapp_new <- whatsappWir wollen nun schauen, wer im Chat am schnellsten antwortet. Am einfachsten ist es, etwas zu analysieren, was in der gleichen Zeile steht. Daher erstellen wir eine neue Spalte und fügen jeweils die Zeit aus der darunter stehenden Zeile ein.
whatsapp_new$response <- NA
whatsapp_new$response <-c(whatsapp_new$time[2:nrow(whatsapp_new)], NA)Im zweiten Schritt können wir dann beide Zeiten voneinander subtrahieren und haben unsere Antwortzeit.
whatsapp_new$antwortzeit <- whatsapp_new$response - whatsapp_new$timeDas gleiche machen wir auch mit dem Absender der Antwortnachricht, da wir sonst nicht zuordnen können, wer hier wie schnell geantwortet hat. Dabei ist wichtig, dass wir den Absender als Faktor vorliegen haben müssen.
whatsapp_new$antworter <- NA
whatsapp_new$antworter <-c(as.character(whatsapp_new$author[2:nrow(whatsapp_new)]), NA)
whatsapp_new$antworter <- as.factor(whatsapp_new$antworter)Wie du dir hoffentlich gemerkt hast, gibt es mehrere Zeilen hintereinander, die eigentlich zur gleichen Nachricht gehören und es gibt auch Personen, die ihre Antwort generell in zwei Nachrichten und nicht in einer verfassen. Daher müssen wir die ausschließen, die “sich selbst antworten”. Dafür identifizieren wir zunächst jene Zeilen, die den gleichen Absender und Beantworter haben. Danach können wir die zwei Spalten antwortzeit und antworter durch NA ersetzen.
gleich <- which(whatsapp_new$antworter == whatsapp_new$author)
for (i in gleich) {
whatsapp_new[i,]$antwortzeit <- NA
whatsapp_new[i,]$antworter <- NA
}Nun musst du dir überlegen, welches das sinnvollste Maß der zentralen Lage in diesem Fall ist. Bei Betrachtung des Datensatzes sieht man, dass manche Antwortzeiten extrem hoch sind. Das kann daran liegen, dass erst am nächsten Tag geantwortet wurde, oder dass das Gespräch beendet und erst nach 2 Tagen ein neues angefangen wurde. Daher ist es am sinnvollsten, den Median zu nutzen, da dieser am robustesten gegenüber Ausreißern ist. Mit tapply kannst du ein bestimmtes Maß auf die ganze Tabelle anwenden.
zeit <- tapply(whatsapp_new$antwortzeit, whatsapp_new$antworter, median)Um am Ende ein Ergebnis zu bekommen, wer nun wirklich die beste Freundin/der beste Freund ist, brauchen wir ein Punkte-System. Hierfür erstellen wir eine Tabelle mit den Namen aller Chatmitglieder und fügen die Zeit ein. Im zweiten Schritt erhält jeder Punkte, je nachdem auf welchem Platz er sich befindet. Dafür gibt es den Befehl rank, der die Punktevergabe automatisch durchführt.
tab <- data.frame(levels(whatsapp$author), zeit)
tab$Punkte <- rank(tab$zeit)## levels.whatsapp.author. zeit Punkte
## Anna Anna 480 5
## Anne-Lisa Anne-Lisa 1680 7
## Frank Frank 840 6
## Georg Georg 390 4
## Hans Hans 210 2
## Marie Marie 360 3
## Petra Petra 180 1Stimmungsanalyse
Abschnitt anzeigen
Falls du es noch nicht getan hast solltest du spätestens hier das Packet Udpipe installiert haben und laden.
#install.packages("udpipe")
library(udpipe)## Warning: package 'udpipe' was built under R version 3.6.3Das Folgende wurde alles bereits in der Übersicht erklärt, der Vollständigkeit halber steht es hier aber nochmals. Um udpipe benutzen zu können, musst du das Modell in der richtigen Sprache herunterladen und in die aktuelle Sitzung laden.
# model <- udpipe_download_model(language = 'german')
germodel <- udpipe_load_model(file = dir(pattern = 'udpipe'))Nun müssen die verschiedenen Listen eingelesen werden. Wir haben die Tabellen mit den richtigen Namen versehen, damit es einfacher und ordentlicher ist. Das ist zwar kein muss, aber umbedingt zu empfehlen.
emo <- read.csv('EmotionLookupTable.txt', sep = '\t', header = FALSE, stringsAsFactors = FALSE)
names(emo) <- c('Wort', 'Senti', 'Englisch', 'Quelle', 'Entstehung')
boost <- read.table('BoosterWordList.txt', stringsAsFactors = FALSE)
names(boost) <- c('Wort', 'Boost')
negate <- read.table('NegatingWordList.txt', stringsAsFactors = FALSE)
negate <- negate[, 1]Für die Textanalyse brauchen wir eine Tabelle, in der alle Wörter nach ihrer Stärke der Bedeutung sortiert sind.
polar <- data.frame(term = emo$Wort, polarity = emo$Senti, stringsAsFactors = FALSE)Die Boostliste wird hier unterteilt in Verstärker und Abschwächer.
ampli <- boost[boost$Boost > 0, 'Wort']
deamp <- boost[boost$Boost < 0, 'Wort']Zuerst versuchen wir die Analyse mit Hans. Dafür suchen wir mit grep alle Nachrichten raus, die Hans geschrieben hat.
hans <- whatsapp$text[grep('Hans', whatsapp$author)]
hans <- paste(hans, collapse = ' ')Im zweiten Schritt müssen wir die Nachrichten in Tokens zerlegen. Wenn du nicht mehr weißt, was damit gemeint ist, schau dir unter der Problemstellung nochmal die genauere Erklärung an.
hans <- udpipe(hans, germodel)Für die Analyse hast du nun vier Komponenten:
polarity_termssind die Wörter an sich, welche positiv oder negativ sind.polarity_negatorssind die Begriffe, die die Bedeutung umkehren können.polarity_amplifierssind die Verstärker.polarity_deamplifierssind die Abschwächer.
senti_hans <- txt_sentiment(hans,
polarity_terms = polar,
polarity_negators = negate,
polarity_amplifiers = ampli,
polarity_deamplifiers = deamp)In der Spalte overall sind alle Endergebnisse gespeichert.
senti_hans$overall## doc_id sentiment_polarity sentences terms terms_positive terms_negative
## 1: doc1 -3 21 525 gern, gut, ok, okay leider, sorry
## terms_negation terms_amplification
## 1: kein, nicht vollWenn wir das Ganze nun mit allen aus dem Chat machen wollen, müssen wir ein Dataframe mit allen Personen erstellen und die Nachrichten hinzufügen.
chat <- data.frame(author = levels(whatsapp$author), what = '', stringsAsFactors = FALSE)
for (i in levels(whatsapp$author)) {
chat$what[chat$author == i] <- paste(whatsapp$text[whatsapp$author == i], collapse = ' ')
}Auch hier zerlegen wir die Nachricht in Tokens und analysieren den Chat auf die gleiche Art und Weise wie oben.
chat <- udpipe(chat$what, germodel)
senti_all <- txt_sentiment(chat,
polarity_terms = polar,
polarity_negators = negate,
polarity_amplifiers = ampli,
polarity_deamplifiers = deamp)
senti_all$overall## doc_id sentiment_polarity sentences terms
## 1: doc1 32.6 23 1176
## 2: doc2 2.0 17 284
## 3: doc3 26.6 41 666
## 4: doc4 15.6 24 700
## 5: doc5 -3.0 21 525
## 6: doc6 11.6 42 870
## 7: doc7 -1.0 30 1130
## terms_positive terms_negative
## 1: danke, gern, gut, ok, super, zufrieden leider, sorry
## 2: gern, gratis, gut leider
## 3: danke, gern, gut, inspirieren, okay, super leider
## 4: gut, hoffentlich, mag, okay leider, sorry
## 5: gern, gut, ok, okay leider, sorry
## 6: gern, gut, super kriegen, leider, sorry
## 7: gern, gut, ok, okay leider, schade, vermissen
## terms_negation terms_amplification
## 1: kein, nicht echt, sehr, voll
## 2: nicht echt, komplett, sehr
## 3: kein, nicht bestimmt, definitiv, echt, sehr, wenig, wirklich
## 4: kein, nicht, nie echt, sehr, voll
## 5: kein, nicht voll
## 6: nicht echt, voll
## 7: kein, nicht echt, unglaublich, voll, wirklichNun kann man jedoch nicht erkennen, welche Daten zu welcher Person gehören, da der overall Befehl nur Nummern und keine Namen anzeigt. Das Problem können wir aber lösen, indem wir die Autorennamen in einem weiteren Schritt zuweisen.
senti <- senti_all$overall
senti$doc_id <- levels(whatsapp$author)Nun kannst du dir die Werte absteigend anschauen. Der höchste Wert ist die positivste Person in deinem Chat.
senti[order(senti$sentiment_polarity, decreasing = TRUE), ]## doc_id sentiment_polarity sentences terms
## 1: Anna 32.6 23 1176
## 2: Frank 26.6 41 666
## 3: Georg 15.6 24 700
## 4: Marie 11.6 42 870
## 5: Anne-Lisa 2.0 17 284
## 6: Petra -1.0 30 1130
## 7: Hans -3.0 21 525
## terms_positive terms_negative
## 1: danke, gern, gut, ok, super, zufrieden leider, sorry
## 2: danke, gern, gut, inspirieren, okay, super leider
## 3: gut, hoffentlich, mag, okay leider, sorry
## 4: gern, gut, super kriegen, leider, sorry
## 5: gern, gratis, gut leider
## 6: gern, gut, ok, okay leider, schade, vermissen
## 7: gern, gut, ok, okay leider, sorry
## terms_negation terms_amplification
## 1: kein, nicht echt, sehr, voll
## 2: kein, nicht bestimmt, definitiv, echt, sehr, wenig, wirklich
## 3: kein, nicht, nie echt, sehr, voll
## 4: nicht echt, voll
## 5: nicht echt, komplett, sehr
## 6: kein, nicht echt, unglaublich, voll, wirklich
## 7: kein, nicht vollFür unseren Test müssen wir nun wieder Punkte verteilen. Dafür solltest du erst den ‘Positivitätswert’ in der Tabelle speichern und dann wie bei der Zeitanalyse Punkte vergeben. Hier muss du aber ein Minus vorschreiben, weil die höchste Zahl hier am besten ist, und nicht die niedrigste.
tab$senti <- senti$sentiment_polarity
tab$Punkte2 <- rank(-senti$sentiment_polarity)Für das Ergebnis des Tests rechnest du einfach beide Punkte zusammen und lässt dir das Minimum ausgeben.
tab$final <- tab$Punkte + tab$Punkte2
tab$levels.whatsapp.author.[which.min(tab$final)]## [1] Anna
## Levels: Anna Anne-Lisa Frank Georg Hans Marie PetraWie du siehst, scheint hier Anna deine beste Freundin zu sein. Falls du noch die Ergebnisse der anderen vergleichen möchtest, hier die Gesamtübersicht der Werte und Punkte:
tab## levels.whatsapp.author. zeit Punkte senti Punkte2 final
## Anna Anna 480 5 32.6 1 6
## Anne-Lisa Anne-Lisa 1680 7 2.0 5 12
## Frank Frank 840 6 26.6 2 8
## Georg Georg 390 4 15.6 3 7
## Hans Hans 210 2 -3.0 7 9
## Marie Marie 360 3 11.6 4 7
## Petra Petra 180 1 -1.0 6 7