
Grafiken mit ggplot2
Einleitung
Das Paket ggplot2 ist das umfangreichste und am weitesten verbreitete Paket zur Grafikerstellung in R. Seine Beliebtheit liegt vor allem an zwei Dingen: Es ist sehr eng mit der kommerziellen Seite von RStudio verwoben (Autor ist auch hier Hadley Wickham) und es folgt stringent einer “Grammatik der Grafikerstellung”. Aus dem zweiten Punkt leitet sich auch sein Name ab: das “gg” steht für “Grammar of Graphics” und geht auf das gleichnamige Buch von Leland Wilkinson zurück, in dem auf 700 kurzen Seiten eine grammatikalische Grundstruktur für das Erstellen von Grafiken zur Datendarstellung hergeleitet und detailliert erklärt wird.
Weil ggplot2 so beliebt ist, gibt es online tausende von Quellen mit Tutorials, Beispielen und innovativen Ansätzen zur Datenvisualisierung. Vom Autor des Pakets selbst gibt es ein Überblickswerk über Data-Science als e-Book, in dem sich auch ein Kapitel mit ggplot2 befasst.
Beispieldaten
Wir benutzen für unsere Interaktion mit ggplot2 öffentlich zugängliche Daten aus verschiedenen Quellen, die dankenswerterweise von Gapminder zusammengetragen werden. Für diesen Abschnitt gucken wir uns dafür mal an, wie viele verschiedene Länder in die Bildung investieren - diese Daten stammen ursprünglich von der Weltbank.
Alle, die daran interessiert sind, wie diese Daten von Gapminder bezogen und für die Weiterverwendung aufbereitet werden, können das Ganze im kurzen Beitrag zur Datenaufbereitung noch genauer nachlesen. Für alle, die das überspringen und einfach Bilder machen wollen, gibt es auch schon den fertigen Datensatz zum Download. Auch den kann man aber direkt in R laden, ohne erst die Datei herunterladen und speichern zu müssen:
load(url('https://pandar.netlify.com/post/edu_exp.rda'))Eine kurze Erläuterung der Variablenbedeutungen:
geo: Länderkürzel, das zur Identifikation der Länder über verschiedene Datenquellen hinweg genutzt wirdCountry: der Ländername im EnglischenWealth: Wohlstandseinschätzung des Landes, unterteilt in fünf GruppenRegion: Einteilung der Länder in die vier groben Regionenafrica,americas,asiaundeuropeYear: JahreszahlPopulation: BevölkerungExpectancy: Lebenserwartung eines Neugeborenen, sollten die Lebensumstände stabil bleiben.Income: Stetiger Wohlstandsindikator für das Land (GDP pro Person)Primary: Staatliche Ausgaben pro Schüler:in in der primären Bildung als Prozent desincome(GDP pro Person)Secondary: Staatliche Ausgaben pro Schüler:in in der sekundären Bildung als Prozent desincome(GDP pro Person)Tertiary: Staatliche Ausgaben pro Schüler:in oder Student:in in der tertiären Bildung als Prozent desincome(GDP pro Person)Index: Education Index des United Nations Development Programme
Eine Ausprägung von 100 auf der Variable Primary in Deutschland hieße also zum Beispiel, dass pro Schüler:in in der Grundschule das Äquivalent der Wirtschaftsleistung einer/eines Deutschen ausgegeben würde. 50 hieße dementsprechend, dass es die Hälfte dieser Wirtschaftsleistung in diese spezifische Schulausbildung investiert wird.
Der Datensatz, mit dem wir arbeiten, sieht also so aus:
head(edu_exp)## geo Country Wealth Region Year Population Expectancy Income Primary
## 1 afg Afghanistan low_income asia 1997 19357126 53.74 865 NA
## 2 afg Afghanistan low_income asia 1998 19737770 52.80 800 NA
## 3 afg Afghanistan low_income asia 1999 20170847 54.43 735 NA
## 4 afg Afghanistan low_income asia 2000 20779957 54.63 687 NA
## 5 afg Afghanistan low_income asia 2001 21606992 54.76 646 NA
## 6 afg Afghanistan low_income asia 2002 22600774 55.65 1016 NA
## Secondary Tertiary Index
## 1 NA NA 13.33333
## 2 NA NA 13.33333
## 3 NA NA 14.00000
## 4 NA NA 14.66667
## 5 NA NA 14.66667
## 6 NA NA 15.33333ggplot2 Grundprinzipien
In ggplot2 werden immer Daten aus einem data.frame dargestellt. Das heißt, dass wir nicht, wie bei plot oder hist aus R selbst Vektoren oder Matrizen nutzen können. Daten müssen immer so aufbereitet sein, dass der grundlegende Datensatz sinnvoll benannte Variablen enthält und in dem Format vorliegt, in welchem wir die Daten visualisieren wollen. Das hat zwar den Nachteil, dass wir Datensätze umbauen müssen, wenn wir Dinge anders darstellen wollen, aber hat auch den Vorteil, dass wir alle Kenntnisse über Datenmanagement im Allgemeinen auf den Umgang mit ggplot2 übertragen können.
Bevor wir loslegen können, muss natürlich ggplot2 installiert sein und geladen werden:
library(ggplot2)Im Kern bestehen Abbildungen in der Grammatik von ggplot2 immer aus drei Komponenten:
- Daten, die angezeigt werden sollen
- Geometrie, die vorgibt welche Arten von Grafiken (Säulendiagramme, Punktediagramme, usw.) genutzt werden
- Ästhetik, die vorgibt, wie die Geometrie und Daten aufbereitet werden (z.B. Farben)
In den folgenden Abschnitten werden wir versuchen, diese drei Komponenten so zu nutzen, dass wir informative und eventuell auch ansehnliche Abbildungen generieren.
Schichten
In ggplot2 werden Grafiken nicht auf einmal mit einem Befehl erstellt, sondern bestehen aus verschiedenen Schichten. Diese Schichten werden meistens mit unterschiedlichen Befehlen erzeugt und dann so übereinandergelegt, dass sich am Ende eine Abbildung ergibt.
Die Grundschicht sind die Daten. Dafür haben wir im vorherigen Abschnitt edu_exp als Datensatz geladen. Benutzen wir zunächst nur die Daten für das Jahr 2013, um nicht direkt tausende von Datenpunkten auf einmal zu sehen. Die Wahl ist hierbei spezifisch auf 2013 gefallen, weil die Daten für dieses Jahr für besonders viele Länder vorliegen.
edu_2013 <- subset(edu_exp, Year == 2013)Um diese Daten in eine Schicht der Grafik zu überführen, können wir sie einfach direkt als einziges Argument an den ggplot-Befehl übergeben:
ggplot(edu_2013)
Was entsteht ist eine leere Fläche. Wie bereits beschrieben, besteht eine Abbildung in ggplot2 immer aus den drei Komponenten Daten, Geometrie und Ästhetik. Bisher haben wir nur eine festgelegt. Als erste Ästhetik sollten wir festlegen, welche Variablen auf x- und y-Achse dargestellt werden sollen. Nehmen wir einen einfachen Scatterplot, in dem wir den Zusammenhang zwischen Ausgaben für die Grundschulbildung (Primary) und dem tatsächlich erreichten Education Index (Index) darstellen.
ggplot(edu_2013, aes(x = Primary, y = Index))![]()
Ästhetik wird in ggplot2 über den aes-Befehl erzeugt. Jetzt fehlt uns noch die geometrische Form, mit der die Daten abgebildet werden sollen. Für die Geometrie-Komponente stehen in ggplot2 sehr viele Funktionen zur Verfügung, die allesamt mit geom_ beginnen. Eine Übersicht über die Möglichkeiten findet sich z.B. hier. Naheliegenderweise nehmen wir für einen Scatterplot Punkte als die geometrische Form (geom_point), die wir darstellen wollen. Neue Schichten werden in ihrer eigenen Funktion erzeugt und mit dem einfachen + zu einem bestehenden Plot hinzugefügt. Für ein Punktdiagramme sieht das Ganze also einfach so aus:
ggplot(edu_2013, aes(x = Primary, y = Index)) +
geom_point()## Warning: Removed 101 rows containing missing values (`geom_point()`).
Der immense Vorteil des Schichtens besteht darin, dass wir gleichzeitig mehrere Visualisierungsformen nutzen können. Das Prinzip bleibt das gleiche wie vorher: wir fügen Schichten mit dem + hinzu. Wir können also z.B. für Zeitverläufe einfach Punkte und Linien direkt miteinander kombinieren.
In der Abbildung sieht es zunächst ganz danach aus, als gebe es zwischen den Ausgaben für die Grundschulbildung und dem erreichten Bildungsindex einen positiven Zusammenhang. Rein numerisch können wir uns das Ganze z.B. mit einer Korrelation angucken:
cor.test(edu_2013$Index, edu_2013$Primary)##
## Pearson's product-moment correlation
##
## data: edu_2013$Index and edu_2013$Primary
## t = 6.9835, df = 94, p-value = 4.057e-10
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.4349433 0.7026192
## sample estimates:
## cor
## 0.584464Mehr zu Korrelation findet sich in diesem Beitrag zu Statistik I.
Plots als Objekte
Einer der Vorteile, die sich durch das Schichten der Abbildungen ergibt ist, dass wir Teile der Abbildung als Objekte definieren können und sie in verschiedenen Varianten wieder benutzen können. Das hilft besonders dann, wenn wir unterschiedliche Geometrie in einer gemeinsamen Abbildung darstellen wollen oder z.B. erst einmal eine Abbildung definieren wollen, bevor wir Feinheiten adjustieren.
basic <- ggplot(edu_2013, aes(x = Primary, y = Index))In basic wird jetzt die Anleitung für die Erstellung der Grafik gespeichert. Erstellt wird die Grafik aber erst, wenn wir das Objekt aufrufen. Dabei können wir das Objekt auch mit beliebigen anderen Komponenten über + kombinieren:
basic + geom_point()## Warning: Removed 101 rows containing missing values (`geom_point()`).
Damit die Beispiele im weiteren Verlauf auch selbstständig funktionieren, wird unten immer der gesamte Plot aufgeschrieben. Aber für Ihre eigenen Übungen oder Notizen ist es durchaus praktischer mit dieser Objekt Funktionalität zu arbeiten, um so zu umgehen, dass man immer wieder die gleichen Abschnitte aufschreiben muss.
Farben und Ästhetik
Oben wurde erwähnt, dass Ästhetik die dritte Komponente ist und als Beispiel wird die Farbe genannt. Das stimmt nicht immer: die Farbe der Darstellung muss nicht zwingend eine Ästhetik sein. Gucken wir uns zunächst an, wie es aussieht, wenn wir die Farbe der Darstellung ändern wollen:
ggplot(edu_2013, aes(x = Primary, y = Index)) +
geom_point(color = 'blue')## Warning: Removed 101 rows containing missing values (`geom_point()`).
Alle Punkte haben die Farbe geändert. Eine Ästhetik im Sinne der ggplot-Grammatik ist immer abhängig von den Daten. Die globale Vergabe von Farbe ist also keine Ästhetik. Sie ist es nur, wenn wir sie von Ausprägungen der Daten abhängig machen. Das funktioniert z.B. so:
ggplot(edu_2013, aes(x = Primary, y = Index)) +
geom_point(aes(color = Primary))## Warning: Removed 101 rows containing missing values (`geom_point()`).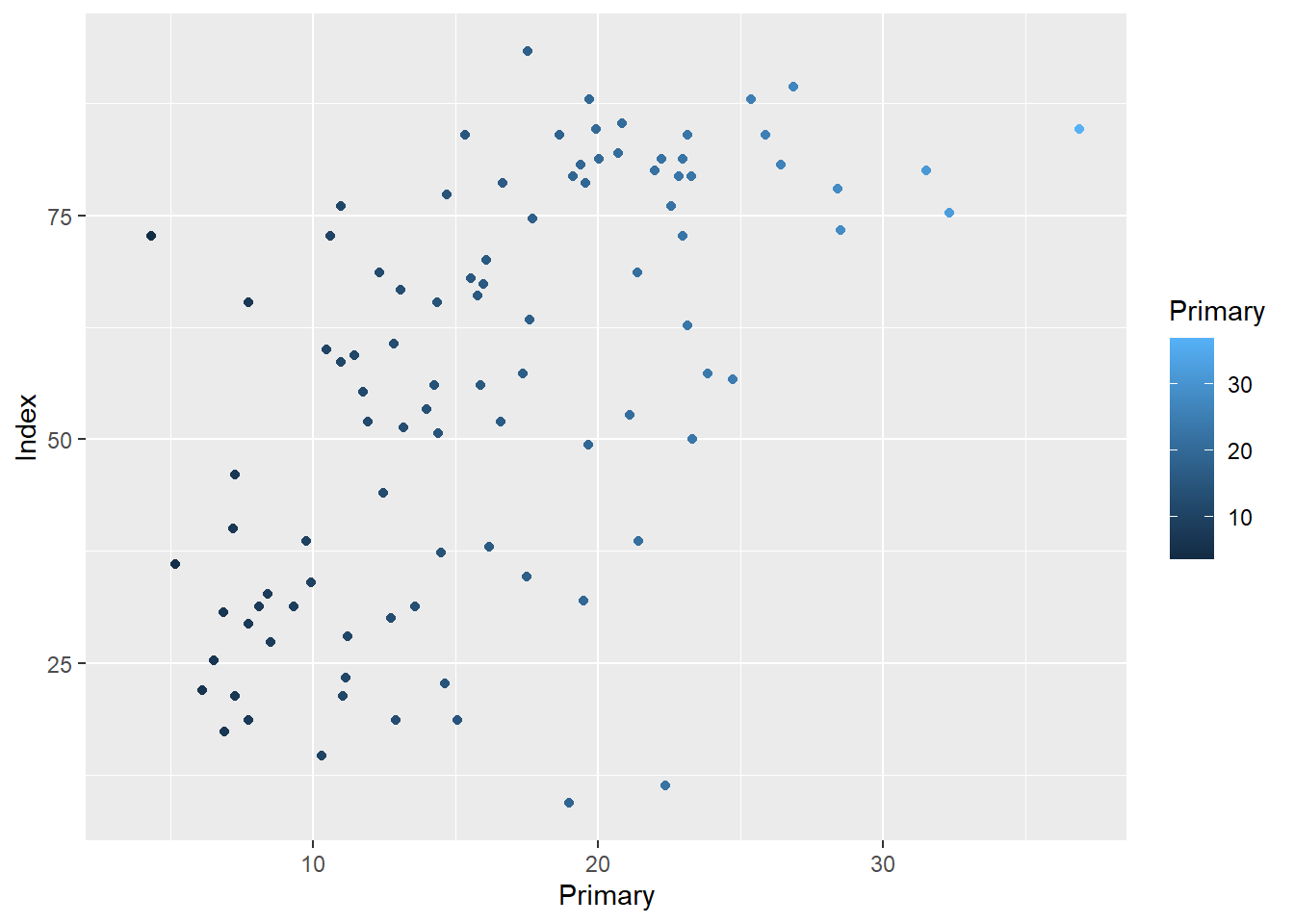
Über den Befehl aes definieren wir eine Ästhetik und sagen ggplot, dass die Farbe der Punkte von der Ausprägung auf der Variable Primary abhängen soll. Die Farbe kann aber natürlich auch von jeder anderen Variable im Datensatz abhängen. Wie das aussehen kann, gucken wir uns im kommenden Abschnitt an.
Gruppierte Abbildungen
Jeder einzelne Punkt in unserer Abbildung stellt ein Land im Jahr 2013 dar. Der einfache Scatterplot aus dem letzten Abschnitt erlaubt uns zwar einen groben Überblick über den Zusammenhang zwischen Ausgaben für Primärbildung und den Bildungsindex zu erhalten, aber gerade über die Länder wissen wir einiges mehr, das wir eventuell bei dieser Betrachtung berücksichtigen wollen. Z.B. lassen sich Länder rein geographisch anhand der Kontinente meist ganz gut gruppieren. Im Datensatz gibt es dafür die Variable Region:
table(edu_2013$Region)##
## africa americas asia europe
## 54 35 59 49Wie wir sehen, sind die beiden Amerikas zusammengefasst, aber im Wesentlichen haben wir eine relativ gleichmäßige Aufteilung der Länder in diese vier großen Regionen. Um diese Regionen auch in der Abbildung erkenntlich zu machen, können wir die Punkte entsprechend einfärben:
ggplot(edu_2013, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region))## Warning: Removed 101 rows containing missing values (`geom_point()`).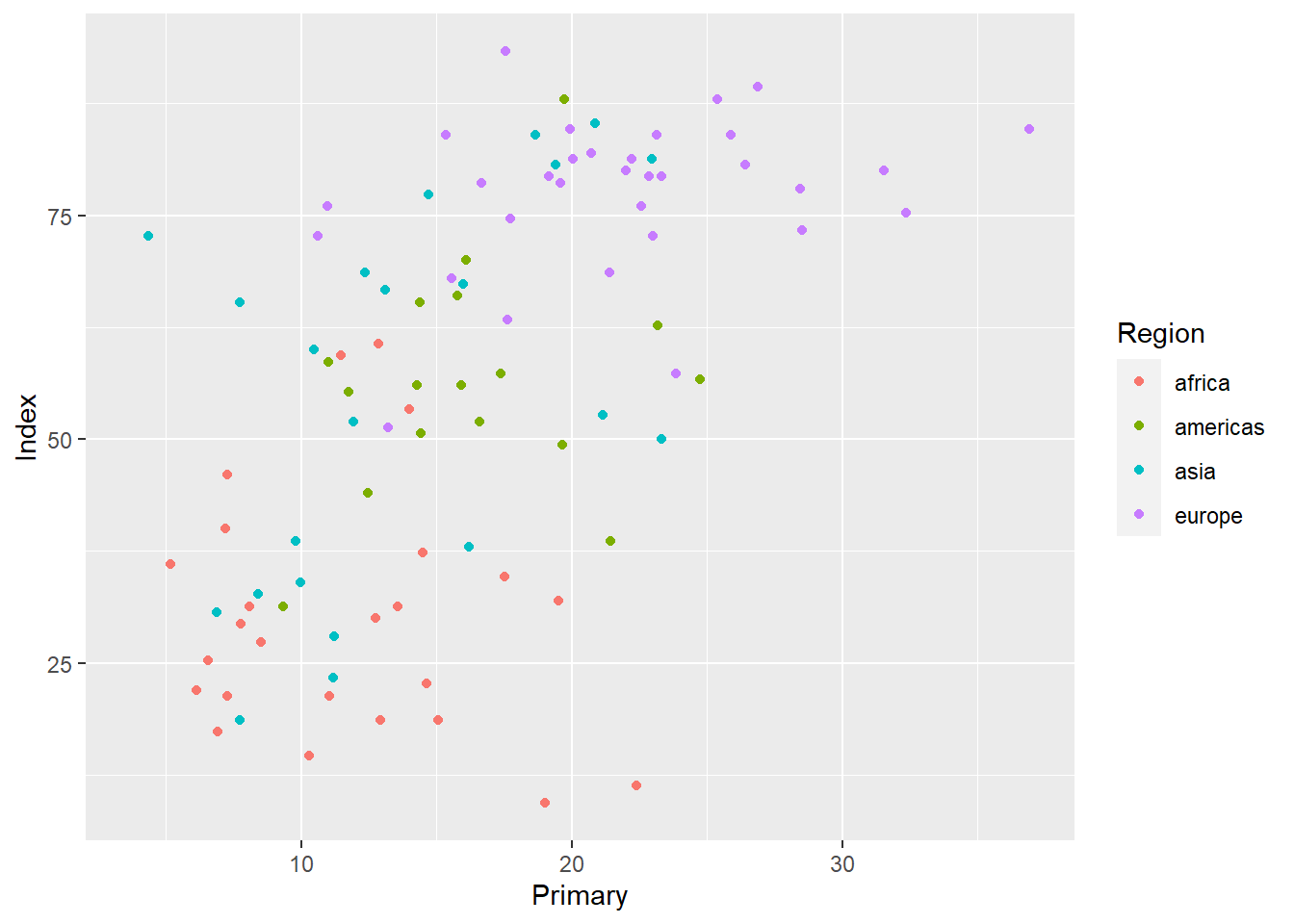
Wie Sie sehen ergibt sich automatisch eine Legende auf der rechten Seite, die jeder Region eine Farbe zuweist.
Das Problem ist bei diesem Vorgehen, dass wir die Ästhetik für jede Geometrie wiederholen müssten, wenn wir z.B. Punkte und Linien zusammen in einer Abbildung zeichnen wollen. Stattdessen können wir in ggplot auch allgemein eine Gruppierung vornehmen, die für alle Geometrien übernommen wird, um so das Erscheinungsbild zu vereinheitlichen:
ggplot(edu_2013, aes(x = Primary, y = Index, color = Region)) +
geom_point()Faceting
Sehr viele Datenpunkte in der gleichen Abbildung darzustellen, kann mitunter sehr unübersichtlich werden. Z.B. könnten wir neben unserer Abbildung für 2013 auch noch Informationen über andere Jahre darstellen wollen. Dafür erstellen wir uns zunächst einen Datensatz mit Informationen aus 1998, 2003, 2008 und 2013, um die Entwicklung der Ausgaben und Bildungsindizes in 5-Jahres-Abständen betrachten zu können.
edu_sel <- subset(edu_exp, Year %in% c(1998, 2003, 2008, 2013))
edu_sel$Year <- as.factor(edu_sel$Year)Beim Versuch, das alles in einer Abbildung darzustellen, wird es etwas chaotisch, selbst wenn wir über die Ästhetik der Punkt-Form (pch für Pointcharacter) versuchen, verschiedene Jahre kenntlich zu machen:
ggplot(edu_sel, aes(x = Primary, y = Index,
color = Region, pch = Year)) +
geom_point()## Warning: Removed 505 rows containing missing values (`geom_point()`).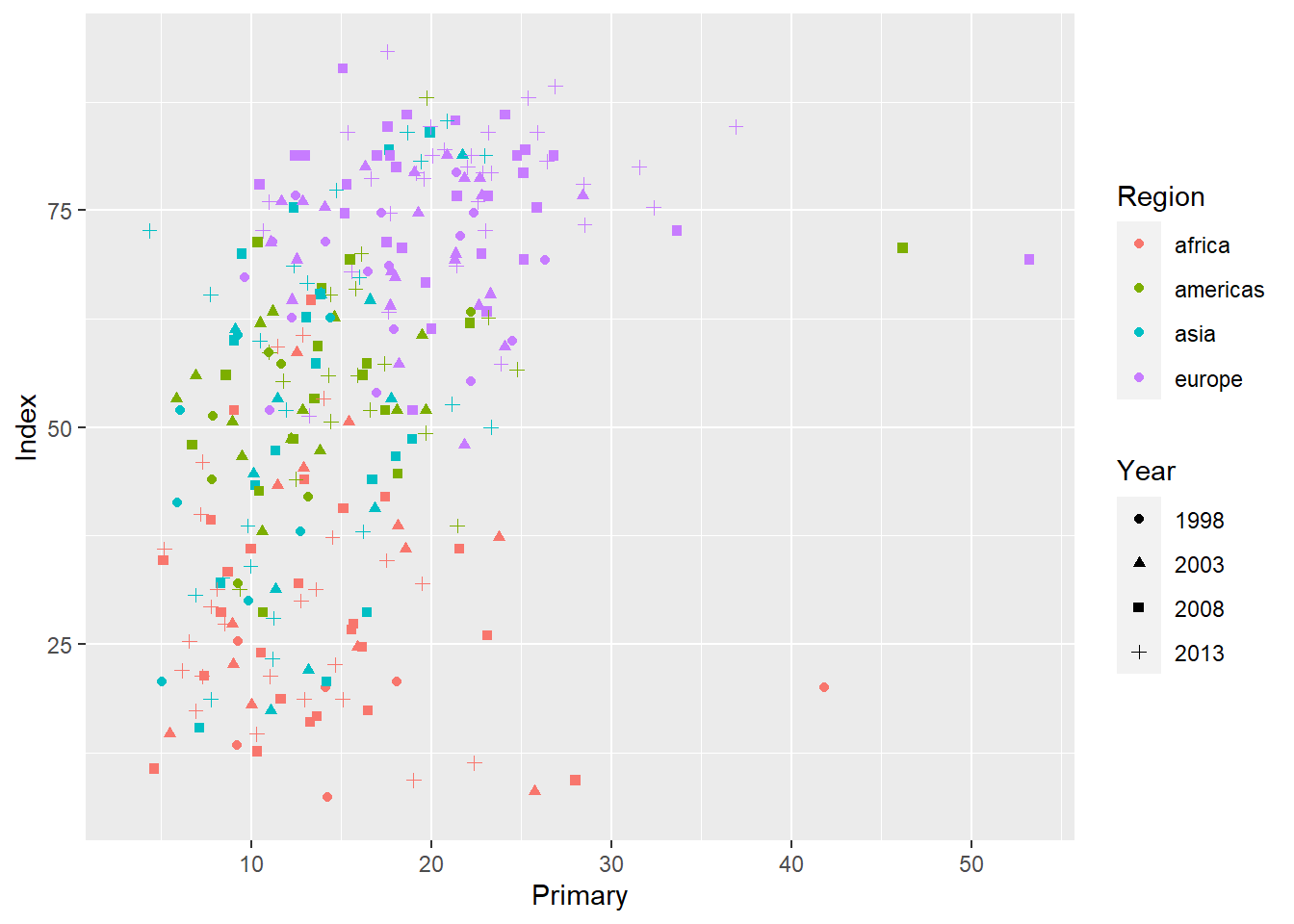
Eine Möglichkeit, in diesem Fall Übersichtlichkeit zu bewahren, ist das sogenannte Faceting. Dabei wird eine Abbildung anhand von Ausprägungen auf einer oder mehr Variablen in verschiedene Abbildungen unterteilt.
ggplot(edu_sel, aes(x = Primary, y = Index,
color = Region)) +
geom_point() +
facet_wrap(~ Year)## Warning: Removed 505 rows containing missing values (`geom_point()`).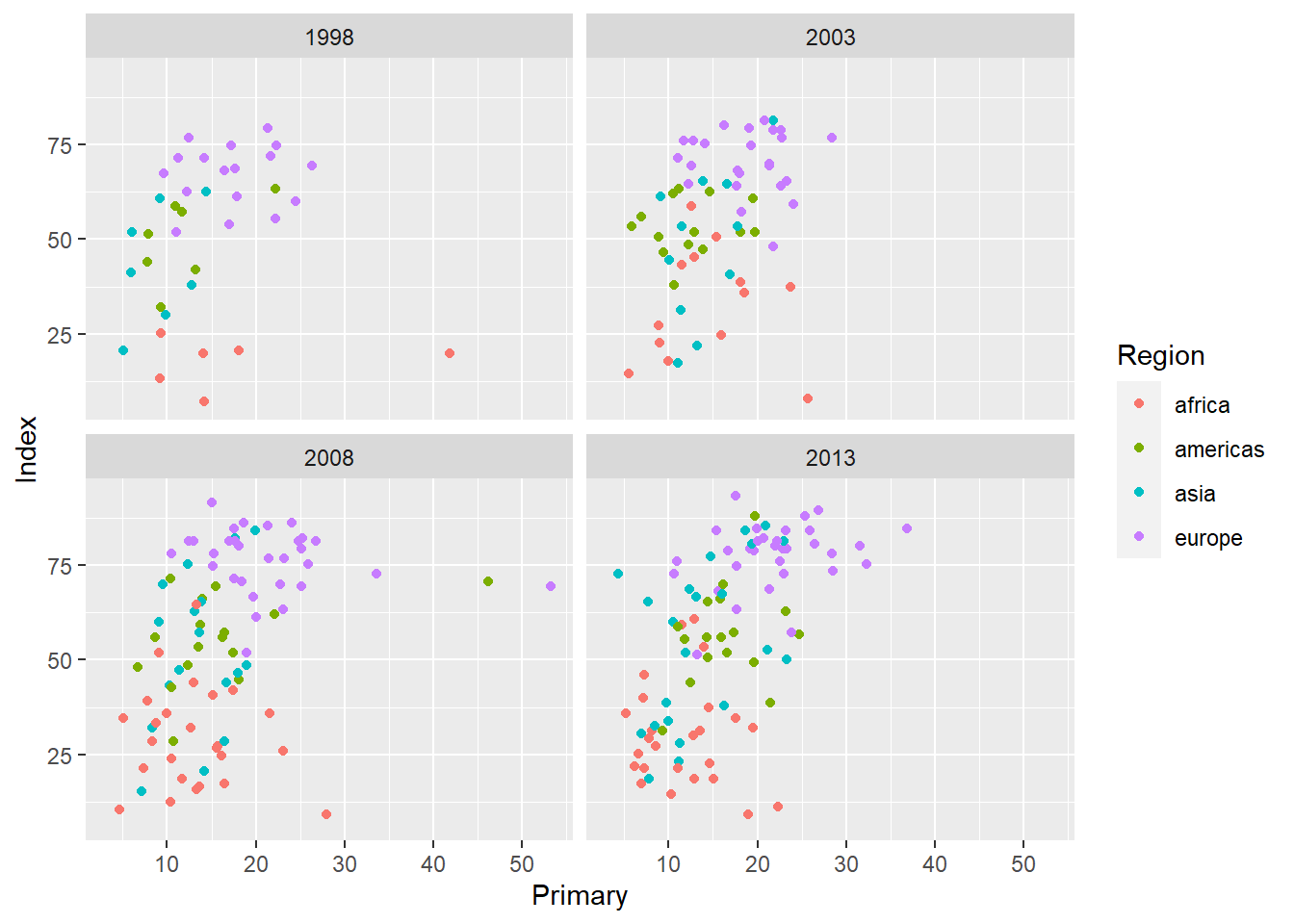
In facet_wrap wird wieder mit der R-Gleichungsnotation gearbeitet: hier wird der Plot anhand der unabhängigen Variablen hinter der Tilde in Gruppen eingeteilt. Das gibt auch wieder die Möglichkeit mit + mehrere Variablen zu definieren, die zum Faceting benutzt werden sollen. Wenn Sie Gruppen anhand von zwei Variablen bilden, bietet es sich außerdem an, facet_grid zu benutzen.
Per Voreinstellung wird beim Faceting eine gemeinsame Skalierung der x- und y-Achsen für alle Teilabbildungen festgelegt. Das kann mit dem Argument scales in der facet_wrap-Funktion umgangen werden. Bei ?facet_wrap finden Sie dafür genauere Informationen.
Abbildungen anpassen
Die Abbildungen, die wir bisher erstellt haben, nutzen alle das in ggplot2 voreingestellte Design. Auch wenn es sicherlich einen theoretisch sehr gut fundierten Grund gibt, dass der Hintergrund der Abbildung in einem demotivierenden Grauton gehalten sein sollte, gibt es Designs, die man schöner finden kann. Im folgenden gucken wir uns an, wie man seine Abbildungen nach seinen eigenen Vorlieben anpassen kann.
Themes
In ggplot2 werden die Grundeigenschaften von Abbildungen in “Themes” zusammengefasst. Mit ?theme_test erhält man eine Auflistung aller Themes, die von ggplot2 direkt zur Verfügung gestellt werden. Diese 10 Themes sind erst einmal sehr konservative Einstellungen für die Eigenschaften von Grafiken. Sehen wir uns meinen persönlichen Favoriten, das sehr dezente theme_minimal() an. Dazu legen wir die Grundanleitung der Abbildung für 2013 zunächst in einem Objekt ab (das ist nicht notwendig, soll nur im Folgenden den Fokus auf die Themes legen):
scatter <- ggplot(edu_2013, aes(x = Primary, y = Index, color = Region)) +
geom_point()Um das Theme einer Abbildung zu verändern, können Sie es - wie Geometrie - mit dem + hinzufügen.
scatter + theme_minimal()## Warning: Removed 101 rows containing missing values (`geom_point()`).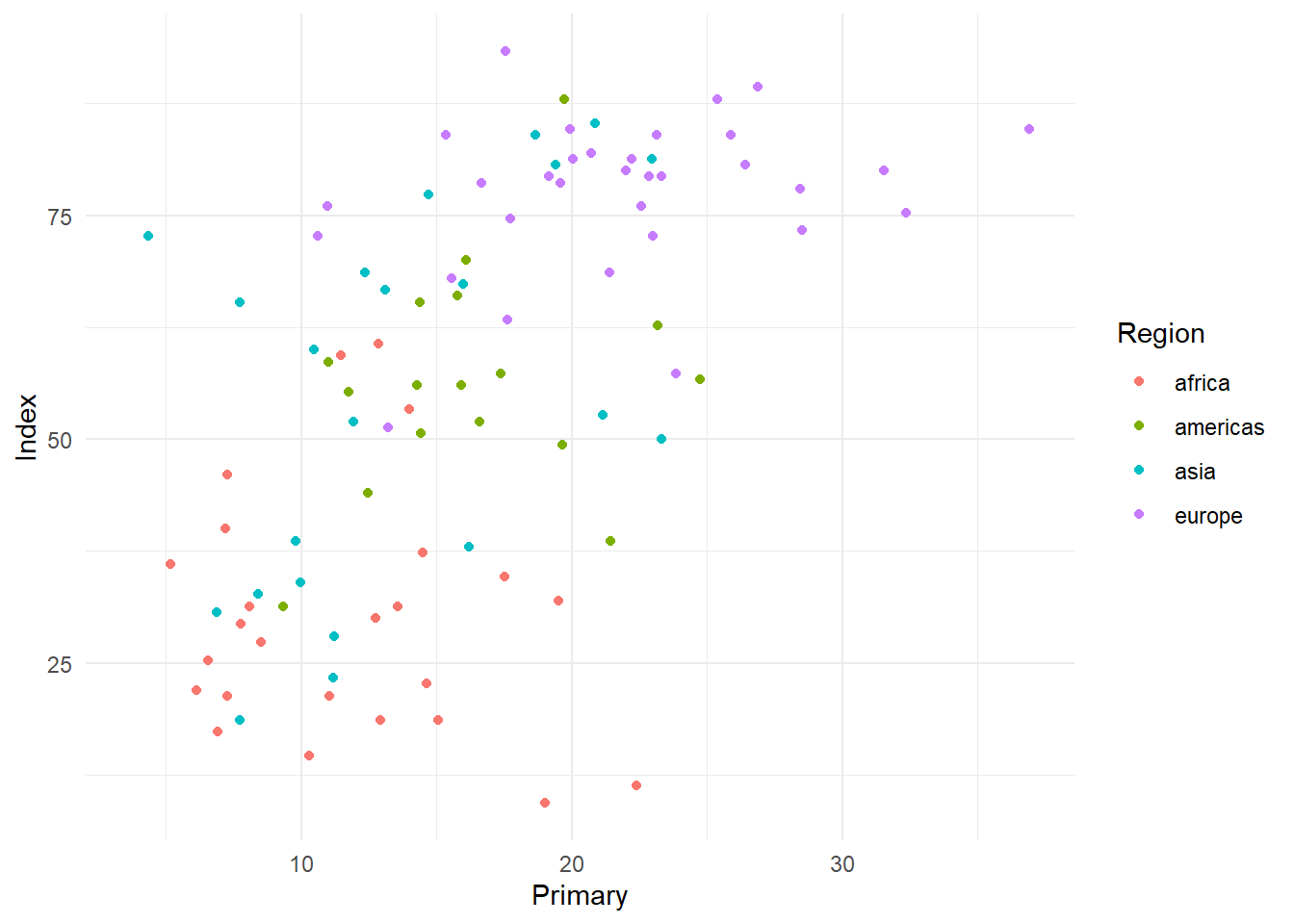
Gegenüber der Voreinstellung (theme_grey) verändert sich hier, dass der Hintergrund jetzt nicht mehr grau ist und das Raster stattdessen in Hellgrau gehalten ist. An diesem Punkt wird erneut der Vorteil des Schichtsystems von ggplot deutlich: wir definieren Daten, Ästhetik und Geometrie und können dann optische Anpassungen über das Theme vornehmen, die von den diesen drei Komponenten unabhängig verändert werden können. Diese Art und Weise, wie von ggplot Abbildungen definiert werden, hat den Vorteil, dass alles was wir hier besprechen auch auf jeden anderen Abbildungstyp anwendbar ist (eine größere Auswahl verschiedener Plots haben wir im ggplotpourri zusammengestellt), weil wir einfach die geom_-Funktionen austauschen können. Die Eigenschaften der Abbildung hinsichtlich des Aussehens von Hintergrund usw. bleiben davon aber unberührt.
Über die von ggplot2 direkt mitgelieferten Themes hinaus gibt es beinahe unzählige weitere Pakete, in denen vordefinierte Themes enthalten sind. Eine der beliebtesten Sammlungen findet sich im Paket ggthemes:
install.packages('ggthemes')
library(ggthemes)## Warning: Paket 'ggthemes' wurde unter R Version 4.2.3 erstelltDieses Paket liefert (neben anderen optischen Erweiterungen) über 20 neue Themes, die häufig den Visualisierungen in kommerzieller Software oder in bestimmten Publikationen nachempfunden sind. In Anlehnung an weit verbreitete Grundprinzipien zur Grafikgestaltung nutzen wir als allererstes natürlich das nach Tuftes “maximal Data, minimal Ink”-Prinzip erstellte Theme:
scatter + theme_tufte()## Warning: Removed 101 rows containing missing values (`geom_point()`).
Aber es gibt natürlich auch etwas komplexer aussehende Themes, wie diesen Nachbau der Grundprinzipien von Abbildungen auf Nate Silvers Website fivethirtyeight:
scatter + theme_fivethirtyeight()## Warning: Removed 101 rows containing missing values (`geom_point()`).
Wenn uns ein Theme so gefällt, dass wir dieses für alle Plots benutzen wollen, können wir es mit theme_set() als neue Voreinstellung definieren. Wie gesagt, mag ich den minimalistischen Stil von theme_minimal(), weil er wenig von den Daten ablenkt:
theme_set(theme_minimal())Dieser Befehl sollte allerdings mit Vorsicht genossen werden, weil er globale Einstellungen in R verändert, ohne davor zu warnen, dass eventuell vorherige Einstellungen verloren gehen. Zur Sicherheit können wir mit
theme_set(theme_grey())jederzeit zurück in die ursprünglichen Voreinstellungen.
Beschriftung
Eine der wichtigsten Komponenten jeder Abbildung ist die Beschriftung. Nur wenn ausreichend gut gekennzeichnet ist, was wir darstellen, können wir darauf hoffen, dass die Information vermittelt wird, die wir vermitteln wollen. Zunächst ist es sinnvoll, die Achsen ordentlich zu beschriften. Per Voreinstellung werden hierzu die Namen der Variablen genutzt. Wir können also eine nützliche Beschriftung auch dadurch erzwingen, dass wir die Variablen im Datensatz ordentlich benennen. Besonders wenn die Achsen aber Zusatzinformationen (wie z.B. “(in %)”) enthalten sollen, ist es aber unumgänglich die Benennung hinterher zu ergänzen. Darüber hinaus kann es sinnvoll sein, einer Grafik Titel und Untertitel zu geben.
Für unsere Abbildung wäre es sinnvoll, neben einem Titel auch eine aussagekräftigere Beschriftung der Achsen und der Legende vorzunehmen.
ggplot(edu_2013, aes(x = Primary, y = Index, color = Region)) +
geom_point() +
labs(x = 'Spending on Primary Eduction',
y = 'UNDP Education Index',
color = 'World Region') +
ggtitle('Impact of Primary Education Investments', '(Data for 2013)')## Warning: Removed 101 rows containing missing values (`geom_point()`).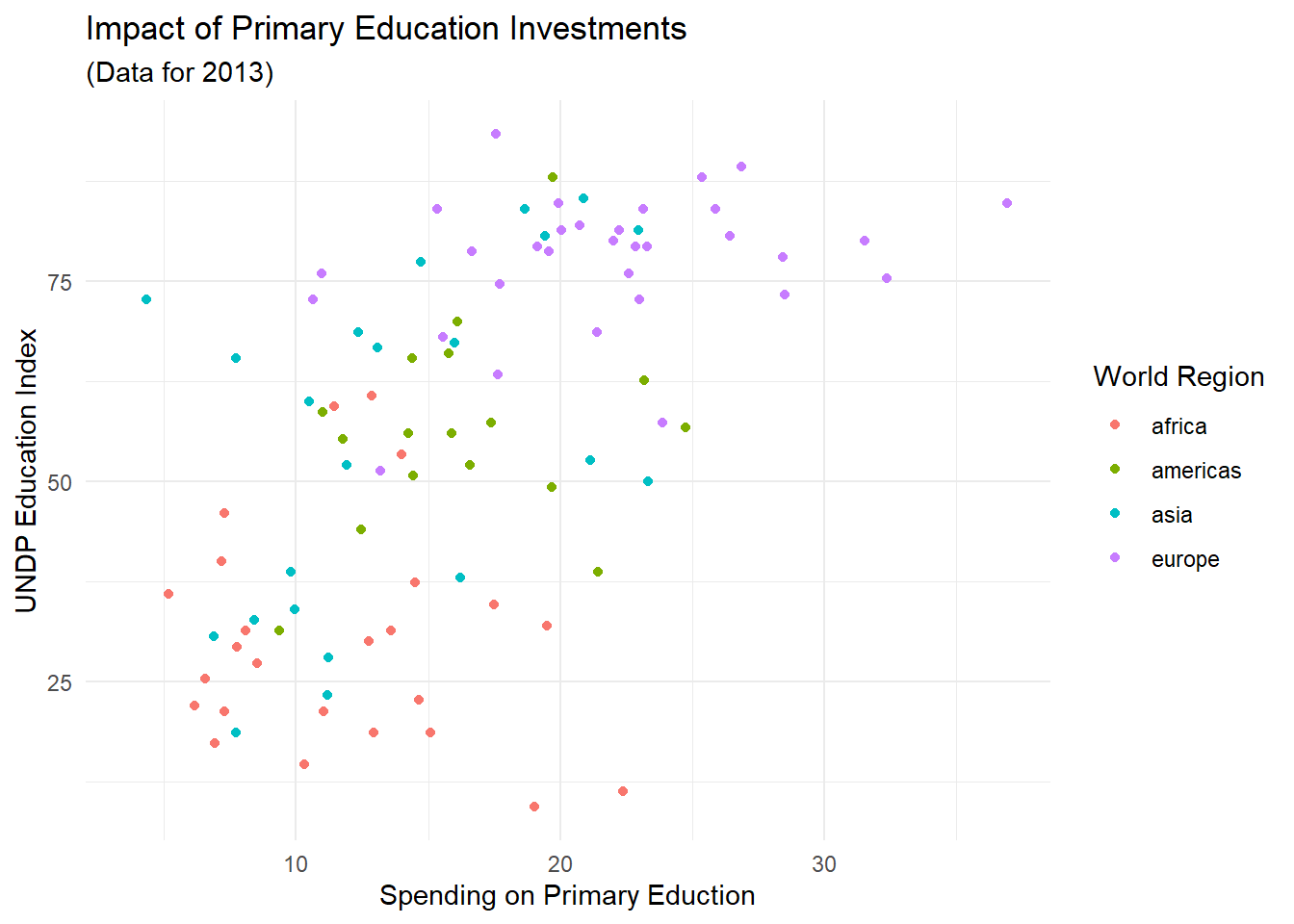
Die labs-Funktion ermöglicht uns das Vergeben von Labels für die Variablen, die wir als Ästhetiken in aes() festgehalten haben. x ersetzt also den Variablennamen von Primary, der per Voreinstellung zur Beschriftung herangezogen wird. Das Gleiche gilt dann auch für y und color ersetzt den Titel der Legende. Die ggtitle-Funktion nimmt zwei Argumente entgegen: den Titel und einen Untertitel.
Die einzige Beschriftung, die jetzt noch ein wenig unschön ist, sind die einzelnen Ausprägungen der Regionen, weil diese nicht mit Großbuchstaben anfangen. Diese kommen direkt aus unseren Daten und stellen die einzigartigen Ausprägungen des Faktors Region in unserem Datensatz dar. Um hier bessere Kontrolle über die Variable zu haben, bietet es sich an, diese Variable in einen Faktor umzuwandeln (wie wir es z.B. schon ganz zu Beginn des ersten Semesters gemacht hatten):
edu_2013$Region <- factor(edu_2013$Region, levels = c('africa', 'americas', 'asia', 'europe'),
labels = c('Africa', 'Americas', 'Asia', 'Europe'))Mit diesem neu angelegten Faktor, sollte sich auch die Legende in unserer Abbildung entsprechend ändern:
scatter <- ggplot(edu_2013, aes(x = Primary, y = Index, color = Region)) +
geom_point() +
labs(x = 'Spending on Primary Eduction',
y = 'UNDP Education Index',
color = 'World Region') +
ggtitle('Impact of Primary Education Investments', '(Data for 2013)')
scatter## Warning: Removed 101 rows containing missing values (`geom_point()`).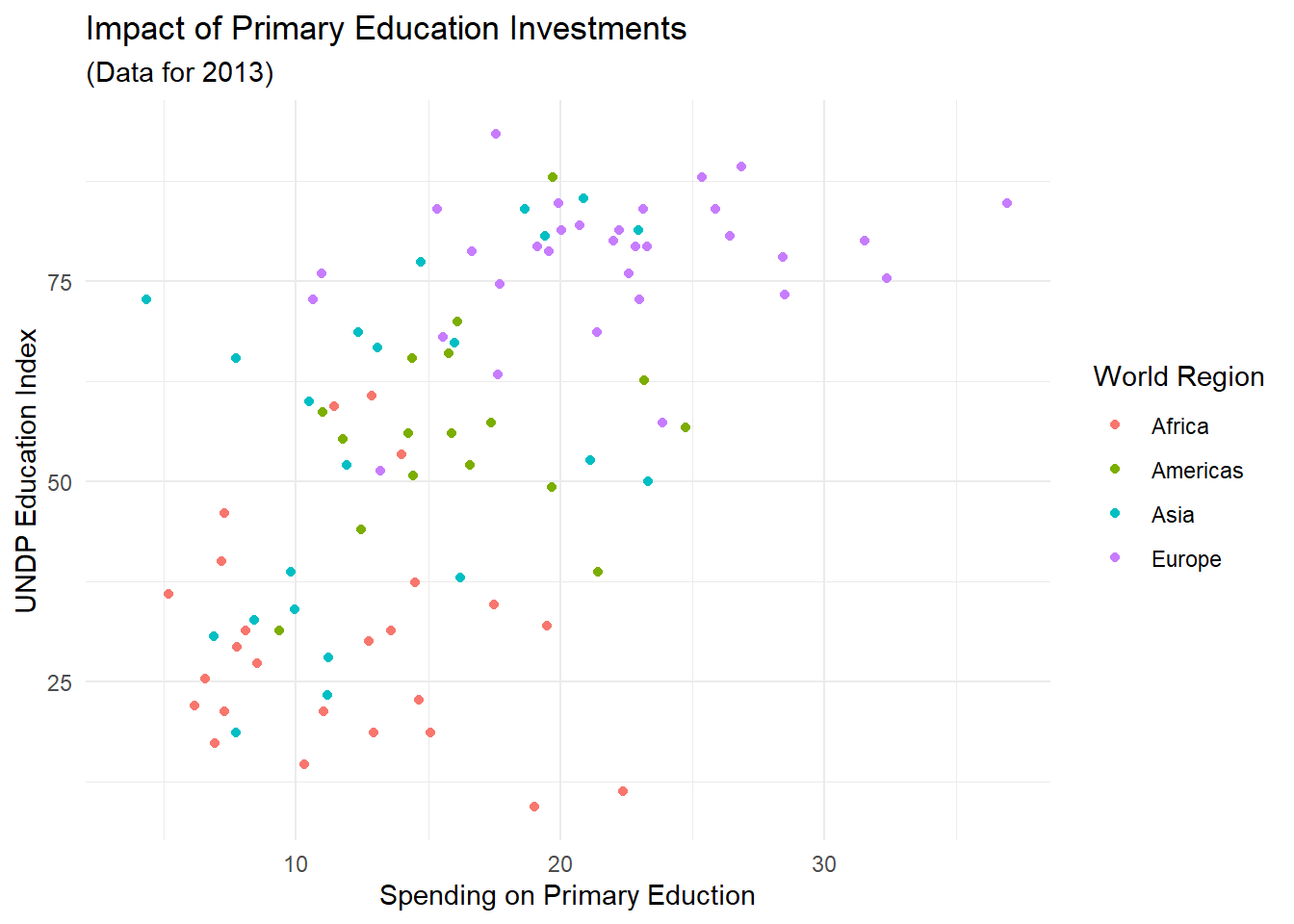
Damit wir unsere Grafik in späteren Abschnitten wiederverwenden können, haben wir sie hier wieder erst in einem Objekt abgelegt, anstatt sie direkt ausgeben zu lassen.
Farbpaletten
Bisher haben wir gesehen, wie die “Rahmenbedingungen” der Grafik mit unserem Theme angepasst werden können - also wie Titel und Hintergrund geändert werden oder wir festlegen, welche Achsen wie beschriftet werden. Was dabei bisher konstant war, war die Farbgebung, die aufgrund der Gruppierungsvariable Region zustande kommt. Damit ist jetzt Schluss.
In ggplot2 wird die Vergabe von Farben in der Ästhetik anhand von zwei Dingen unterschieden: der Geometrie und dem Skalenniveau der Variable, die die Färbung vorgibt. Kontinuierliche Variablen (Variablen, die in R als numeric definiert sind) werden anhand eines Blau-Farbverlaufs dargestellt, diskrete Variablen (Variablen, die in R als factor definiert sind) anhand eines vordefinierten Schemas unterschiedlicher Farben. Dieses Schema ist das Brewer Farbschema, welches ursprünglich für Kartendarstellungen entwickelt wurde.
Nehmen wir an, dass wir unsere Abbildung irgendwo drucken möchten - Farbdruck ist wahnsinnig teuer. Um mit Grautönen zu arbeiten, können wir z.B. scale_color_grey benutzen:
scatter + scale_color_grey()## Warning: Removed 101 rows containing missing values (`geom_point()`).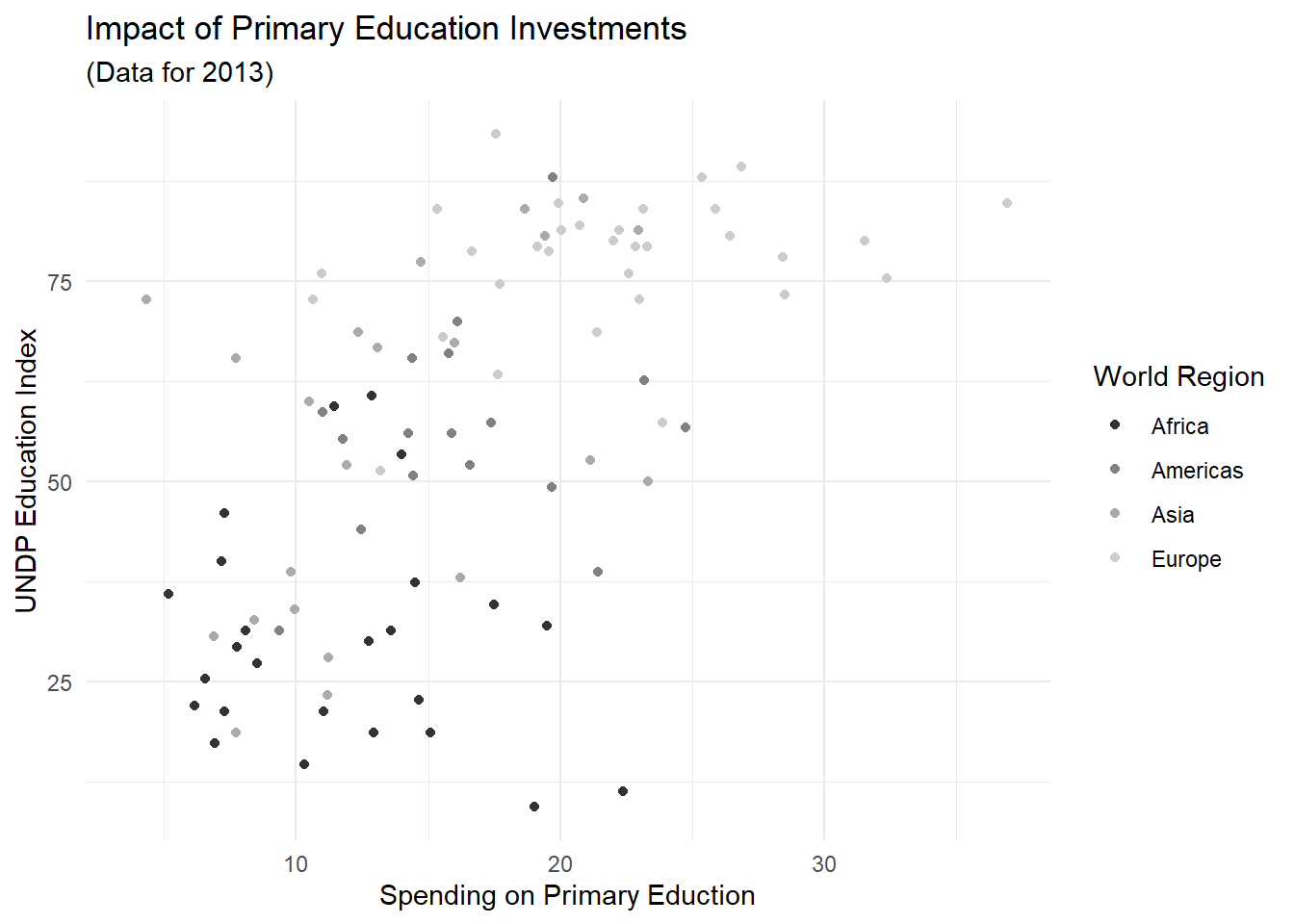
Das bei den Themes erwähnte Paket ggthemes enthält auch weitere Farbpaletten, die Sie nutzen können, um Ihren Plot nach Ihren Vorlieben zu gestalten. Wichtig ist beispielsweise, dass es eine Palette namens colorblind hat, die Farben so auswählt, dass sie auch von Personen mit Farbblindheit differenziert werden können. In Fällen mit 6 oder weniger Gruppen bietet sich darüber hinaus in solchen Fällen an, mit der Ästhetik pch (für plot-character) zu arbeiten. Darüber hinaus gibt es für Fans der Filme von Wes Anderson z.B. das Paket wesanderson, welches für jeden seiner Filme die Farbpalette parat hat. Darüber hinaus können wir aber natürlich auch unsere ganz eigene Farbpalette definieren - z.B. die offizielle Farbpalette des Corporate Designs der Goethe Universität, die Sie auf den Folien von PsyBSc 1 und 2 im letzten Semester kennen (und lieben!) gelernt haben.
Für diese Palette können wir zunächst in einem Objekt die Farben festhalten, die wir benötigen. In ggplot2 ist es dabei am gängigsten, Farben entweder über Worte auszuwählen oder via hexadezimaler Farbdefinition zu bestimmen. Für die fünf Farben, die von der Corporate Design Abteilung der Goethe Uni definiert werdenm ergibt sich folgendes Objekt:
gu_colors <- c('#00618f', '#e3ba0f', '#ad3b76', '#737c45', '#c96215')Dieses Objekt können wir dann nutzen, um mit scale_color_manual selbstständig Farben zuzuweisen:
scatter + scale_color_manual(values = gu_colors)## Warning: Removed 101 rows containing missing values (`geom_point()`).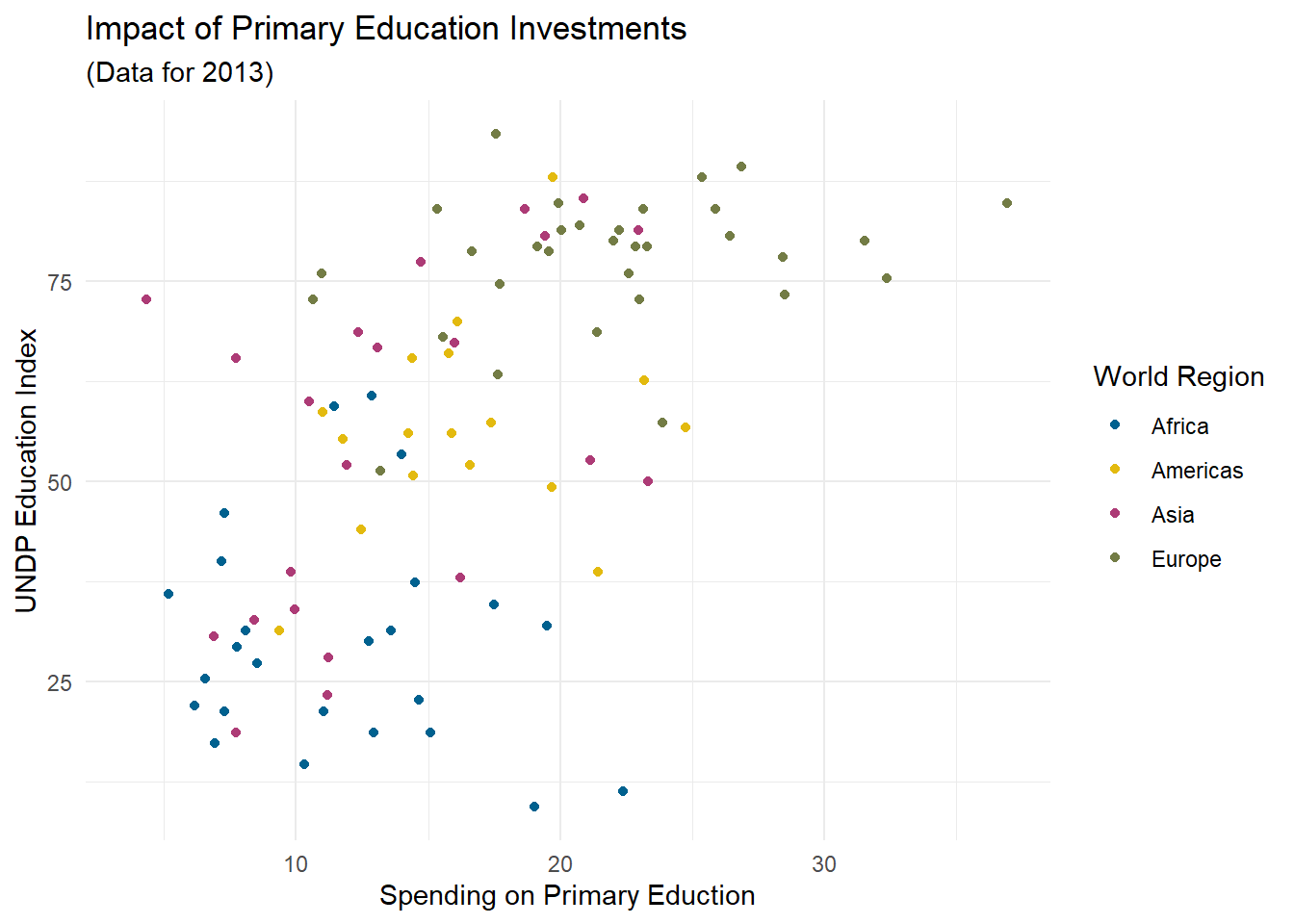
Die Zuordnung der Farben erfolgt anhand der Reihenfolge in gu_colors und der Reihenfolge der Ausprägungen von Region. Letztere ist - wie sie bestimmt festgestellt haben - alphabetisch. Wie häufig in ggplot2 können Sie die Daten ändern (also mit relevel die Reihenfolge der Ausprägungen ändern) um Veränderungen in der Darstellung zu bewirken.
Verschiedene Plots
Bisher haben wir ausschließlich Streupunktdiagramme (Scatterplots) benutzt, um die Daten darzustellen. Im letzten Semester haben Sie darüber hinaus noch einige Arten von Diagrammen kennengelernt, die in der psychologischen Forschung extrem verbreitet sind. Im ggplotpourri haben wir ein paar dieser Abbildung zusammengetragen, sodass Sie diese bei Interesse dort noch näher betrachten können!
Eine wichtige Art, Abbildungen zu ergänzen, die wir hier noch direkt besprechen möchten, ist mit statistischen Ergebnissen. Dazu gucken wir uns im Folgenden Plots mit Trendlinien an.
In den Abschnitten ggplot2 Grundprinzipien und Abbildungen anpassen haben wir uns mit dem sehr verbreiteten Scatterplot befasst. In diesen Plots werden zwei Variablen zueinander ins Verhältnis gestellt. Typischerweise wollen wir aus solchen Plots auch einen Trend erkennen können. Z.B. hatten wir schon mit dem cor.test()-Befehl gesehen, dass es einen positiven linearen Zusammehang zwischen Ausgaben für die Grundschulbildung und den Bildungsindex eines Landes zu geben scheint. Mit geom_smooth können wir uns eine “Glättung” der Datenlagen anschauen, die den generellen Trend verdeutlicht. Per Voreinstellung wird hierzu die sogenannte LOESS-Glättung genutzt.
scatter + geom_smooth()## `geom_smooth()` using method = 'loess' and formula = 'y ~ x'## Warning: Removed 101 rows containing non-finite values (`stat_smooth()`).## Warning: Removed 101 rows containing missing values (`geom_point()`).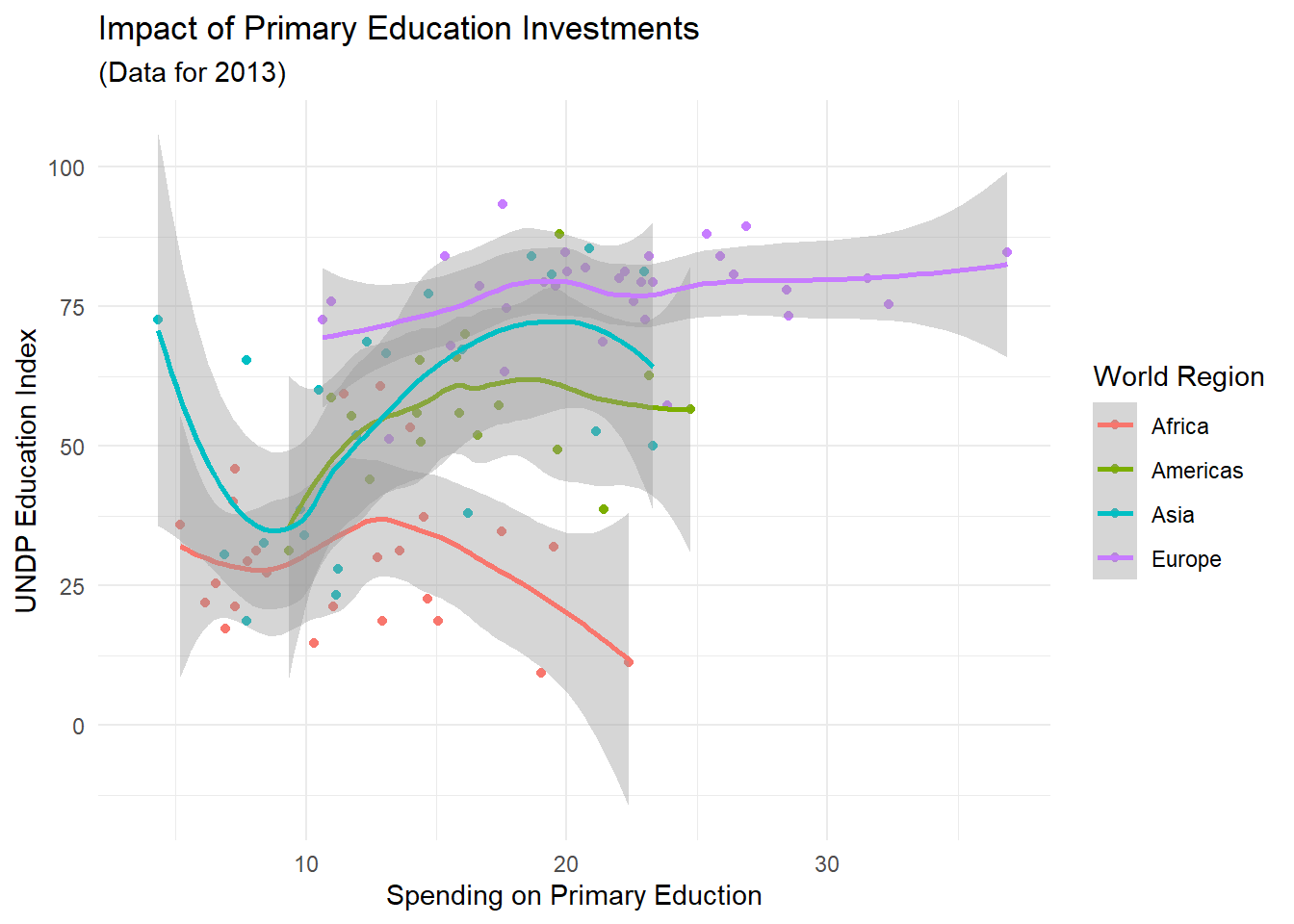
Was eingezeichnet wird, sind die spezifischen Trendlinien unserer vier Welt-Regionen. Die schattierten Flächen um diese Linie herum stellen den Standardschätzfehler dieser Kurve dar. Um uns die globale Trendlinie anzeigen zu lassen, müssen wir die Gruppierung der Beobachtung wieder geometriespezifisch machen:
ggplot(edu_2013, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region)) +
geom_smooth() +
labs(x = 'Spending on Primary Eduction',
y = 'UNDP Education Index',
color = 'World Region') +
ggtitle('Impact of Primary Education Investments', '(Data for 2013)')## `geom_smooth()` using method = 'loess' and formula = 'y ~ x'## Warning: Removed 101 rows containing non-finite values (`stat_smooth()`).## Warning: Removed 101 rows containing missing values (`geom_point()`).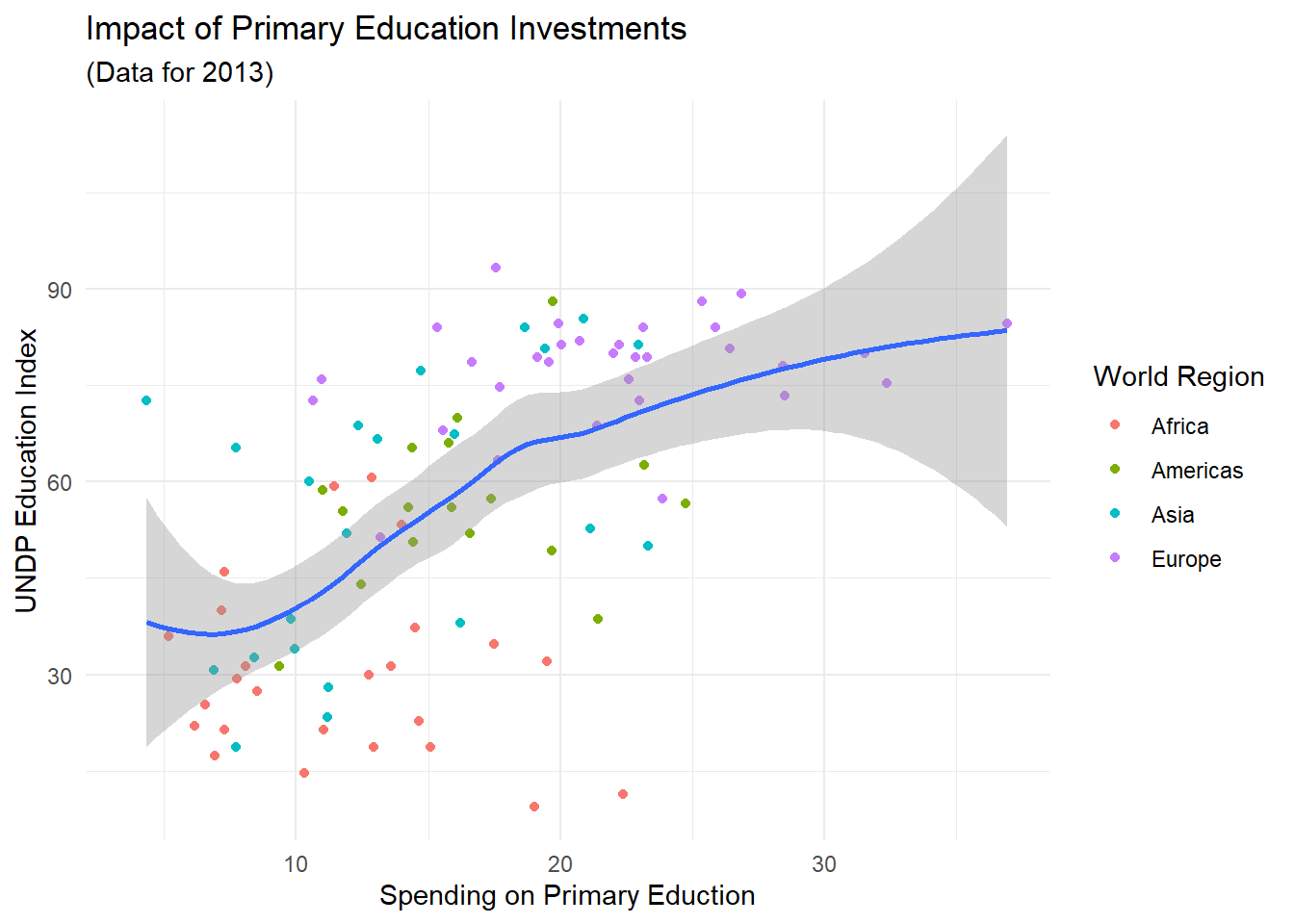 Wir können in diese Abbildung auch statt LOWESS-Linien die Ergebnisse von Regressionen einzeichnen lassen. Statt diese Regression separat über
Wir können in diese Abbildung auch statt LOWESS-Linien die Ergebnisse von Regressionen einzeichnen lassen. Statt diese Regression separat über lm() erstellen zu müssen, wird uns dieser Schritt von ggplot2 abgenommen, wenn wir das Argument method in geom_smooth nutzen. So können wir uns z.B. die Regionen-spezifischen Regressionen in die Abbildung einpflegen lassen. Um die Standardfehler zu unterdrücken und nur die Regressionen zu erhalten, können wir außerdem mit se = FALSE die grauen Flächen unterdrücken.
scatter + geom_smooth(method = 'lm', se = FALSE)## `geom_smooth()` using formula = 'y ~ x'## Warning: Removed 101 rows containing non-finite values (`stat_smooth()`).## Warning: Removed 101 rows containing missing values (`geom_point()`).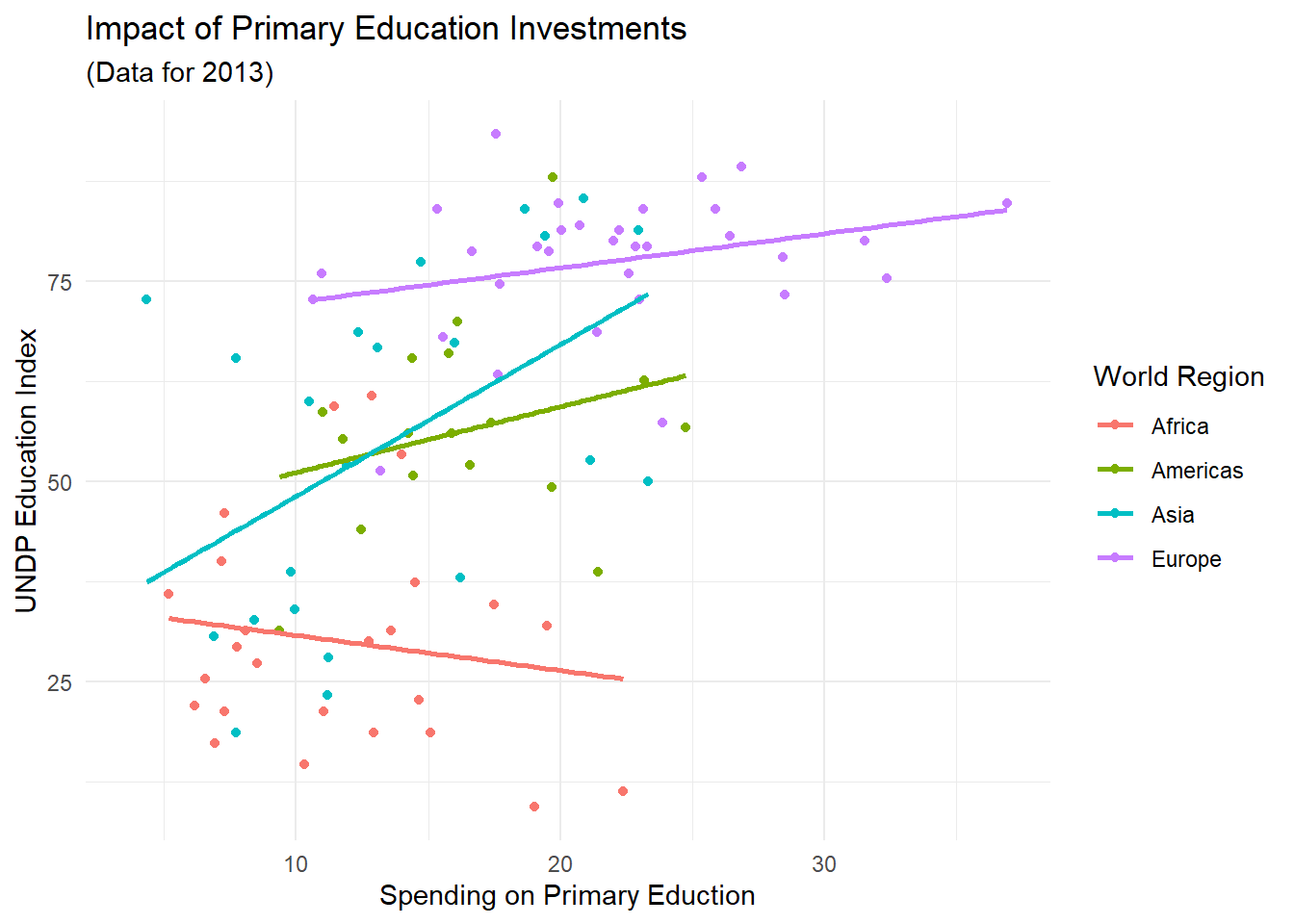
Für eine Vertiefung der Grafiken mit ggplot2 (z.B. Animationen, interaktive Grafiken und individuelle Themes) haben wir im Extras Abschnitt die Materialien aus einem Workshop der digiGEBF bereitgestellt.