Lösungen
Vorwarnung
Achtung! Im Folgenden werden die Lösungen für das erste Projekt präsentiert. Falls du das Projekt noch nicht vollständig bearbeitet hast, nutze zunächst die Tipps. Sofern dir die Tipps für einen Teil nicht geholfen haben, kannst du die Lösungen dafür benutzen, um einen Schritt weiterzukommen und beim nächsten Abschnitt weiterzumachen.
Datensammlung
Abschnitt anzeigen
Um 9 Parteien gleichzeitig abbilden zu können, ist es notwendig zwei separate Anfragen bei Google Trends zu starten. In beiden sollte die Alternative für Deutschland als Referenzpartei enthalten sein, weil die Suchanfragen bezüglich der AfD um die Bundestagswahl 2017 herum das Maximum bilden und demzufolge den Referenzwert 100 setzen, an dem alle anderen Suchanfragen skaliert werden müssen. Mit dem Button erhältst du dann eine Datei mit dem Namen multiTimeline.csv. Wenn du beide Suchanfragen hintereinander durchführst, sollte die zweite Datei dann multiTimeline(1).csv heißen. Du kannst aber auch beiden Dateien beim Download beliebige Namen geben.
Bevor du die beiden Dateien in R einliest, kannst du ein bisschen Schreibarbeit sparen, wenn du erst den Arbeitsordner (working directory) festlegst. Idealerweise solltest du einen Ordner anlegen, in dem du alle relevanten Dateien für dieses Projekt speicherst.
setwd('...') # statt '...' einen Ordner-Pfad festlegenDie beiden Datensätze können dann mit
a <- read.table('multiTimeline.csv', header = TRUE, sep= ',')
b <- read.table('multiTimeline(1).csv', header = TRUE, sep = ',')eingelesen werden. Neben dem Dateinamen müssen hier das Argument header (der Datensatz enthält in der 1. Zeile die Variablennamen) und sep - das Trennzeichen zwischen Variablen - festgelegt werden.
Die ersten Zeilen der beiden Datensätze sollten dann so aussehen:
head(a)## Monat Alternative.fÃ.r.Deutschland...Deutschland.
## 1 2004-01 <1
## 2 2004-02 <1
## 3 2004-03 <1
## 4 2004-04 <1
## 5 2004-05 <1
## 6 2004-06 <1
## Sozialdemokratische.Partei.Deutschlands...Deutschland.
## 1 10
## 2 13
## 3 13
## 4 11
## 5 12
## 6 16
## Freie.Demokratische.Partei...Deutschland.
## 1 4
## 2 4
## 3 4
## 4 3
## 5 5
## 6 7
## BÃ.ndnis.90.Die.GrÃ.nen...Deutschland. Die.Linke...Deutschland.
## 1 4 <1
## 2 4 <1
## 3 4 1
## 4 3 <1
## 5 4 <1
## 6 8 <1head(b)## Monat Alternative.fÃ.r.Deutschland...Deutschland.
## 1 2004-01 <1
## 2 2004-02 <1
## 3 2004-03 <1
## 4 2004-04 <1
## 5 2004-05 <1
## 6 2004-06 <1
## Partei.Mensch.Umwelt.Tierschutz...Deutschland.
## 1 0
## 2 0
## 3 <1
## 4 <1
## 5 <1
## 6 1
## Christlich.Demokratische.Union.Deutschlands...Deutschland.
## 1 8
## 2 10
## 3 9
## 4 9
## 5 11
## 6 14
## Marxistisch.Leninistische.Partei.Deutschlands...Deutschland.
## 1 <1
## 2 <1
## 3 <1
## 4 <1
## 5 <1
## 6 <1
## Nationaldemokratische.Partei.Deutschlands...Deutschland.
## 1 2
## 2 2
## 3 2
## 4 2
## 5 3
## 6 4Datenaufbereitung
Abschnitt anzeigen
Bevor die beiden Datensätze zusammengeführt werden können, sollten zunächst doppelt vorkommende Spalten umbenannt werden, damit sie hinterher weniger Probleme machen. Um zu sehen, welche Namen in beiden auftauchen, können wir names benutzen:
names(a)## [1] "Monat"
## [2] "Alternative.fÃ.r.Deutschland...Deutschland."
## [3] "Sozialdemokratische.Partei.Deutschlands...Deutschland."
## [4] "Freie.Demokratische.Partei...Deutschland."
## [5] "BÃ.ndnis.90.Die.GrÃ.nen...Deutschland."
## [6] "Die.Linke...Deutschland."names(b)## [1] "Monat"
## [2] "Alternative.fÃ.r.Deutschland...Deutschland."
## [3] "Partei.Mensch.Umwelt.Tierschutz...Deutschland."
## [4] "Christlich.Demokratische.Union.Deutschlands...Deutschland."
## [5] "Marxistisch.Leninistische.Partei.Deutschlands...Deutschland."
## [6] "Nationaldemokratische.Partei.Deutschlands...Deutschland."Hier sind also die ersten beiden Spalten doppelt. Wir können diese beiden einfach aus b entfernen:
b <- b[, -c(1, 2)]
names(b)## [1] "Partei.Mensch.Umwelt.Tierschutz...Deutschland."
## [2] "Christlich.Demokratische.Union.Deutschlands...Deutschland."
## [3] "Marxistisch.Leninistische.Partei.Deutschlands...Deutschland."
## [4] "Nationaldemokratische.Partei.Deutschlands...Deutschland."Um beide zusammenzufügen dann:
c <- cbind(a, b)Das Problem dieses kombinierten Datensatzes ist, dass nicht alle Variablen numerisch sind. Das bewirkt, dass die Variablen nur sehr schwer in einer gemeinsamen Abbildung dargestellt werden können:
str(c)## 'data.frame': 190 obs. of 10 variables:
## $ Monat : chr "2004-01" "2004-02" "2004-03" "2004-04" ...
## $ Alternative.fÃ.r.Deutschland...Deutschland. : chr "<1" "<1" "<1" "<1" ...
## $ Sozialdemokratische.Partei.Deutschlands...Deutschland. : int 10 13 13 11 12 16 9 11 17 9 ...
## $ Freie.Demokratische.Partei...Deutschland. : int 4 4 4 3 5 7 3 3 8 4 ...
## $ BÃ.ndnis.90.Die.GrÃ.nen...Deutschland. : int 4 4 4 3 4 8 3 3 6 4 ...
## $ Die.Linke...Deutschland. : chr "<1" "<1" "1" "<1" ...
## $ Partei.Mensch.Umwelt.Tierschutz...Deutschland. : chr "0" "0" "<1" "<1" ...
## $ Christlich.Demokratische.Union.Deutschlands...Deutschland. : int 8 10 9 9 11 14 8 8 16 9 ...
## $ Marxistisch.Leninistische.Partei.Deutschlands...Deutschland.: chr "<1" "<1" "<1" "<1" ...
## $ Nationaldemokratische.Partei.Deutschlands...Deutschland. : int 2 2 2 2 3 4 2 3 15 7 ...Das kommt daher, dass der Wert <1 nicht als numerisch interpretiert wird, sondern als eine Beschriftung, sodass die Variable in R automatisch als factor erkannt und als nominalskaliert behandelt wird. Diese Werte müssen also alle ersetzt werden, um wieder mit numerischen Daten rechnen zu können.
Das ließe sich z.B. dadurch erreichen, dass wir in c alle Werte einzeln ersetzen. Dieses Vorgehen hat allerdings den Nachteil, dass es sehr viele einzelne Schritte benötigt, weswegen wir hier einen Trick anwenden: wir lesen die Daten als numerisch ein und tun dabei so, als wären <1 fehlende Werte. Das können wir durch das Argument na = im read.table-Befehl erreichen, den wir zum Einlesen der Daten genutzt haben:
# Daten einlesen
a <- read.table('multiTimeline.csv',header = T, sep= ',' , na = '<1')
b <- read.table('multiTimeline(1).csv', header = T , sep = ',' , na = '<1')
# Daten zusammenführen
b <- b[, -c(1, 2)]
c <- cbind(a, b)
# Struktur untersuchen
str(c)## 'data.frame': 190 obs. of 10 variables:
## $ Monat : chr "2004-01" "2004-02" "2004-03" "2004-04" ...
## $ Alternative.fÃ.r.Deutschland...Deutschland. : int NA NA NA NA NA NA NA NA NA NA ...
## $ Sozialdemokratische.Partei.Deutschlands...Deutschland. : int 10 13 13 11 12 16 9 11 17 9 ...
## $ Freie.Demokratische.Partei...Deutschland. : int 4 4 4 3 5 7 3 3 8 4 ...
## $ BÃ.ndnis.90.Die.GrÃ.nen...Deutschland. : int 4 4 4 3 4 8 3 3 6 4 ...
## $ Die.Linke...Deutschland. : int NA NA 1 NA NA NA NA NA NA NA ...
## $ Partei.Mensch.Umwelt.Tierschutz...Deutschland. : int 0 0 NA NA NA 1 NA 0 NA NA ...
## $ Christlich.Demokratische.Union.Deutschlands...Deutschland. : int 8 10 9 9 11 14 8 8 16 9 ...
## $ Marxistisch.Leninistische.Partei.Deutschlands...Deutschland.: int NA NA NA NA NA NA NA NA 1 NA ...
## $ Nationaldemokratische.Partei.Deutschlands...Deutschland. : int 2 2 2 2 3 4 2 3 15 7 ...Jetzt sind alle Variablen außer Monat als integer (also eine Sonderform numerischer Variablen) abgespeichert. Das heißt, wir müssen nun lediglich die mit NA als fehlend markierten Beobachtungen durch 0 ersetzen:
c[is.na(c)] <- 0Im letzten Schritt zur Datenaufbereitung vergeben wir noch etwas kürzere Namen für die Spalten:
names(c)## [1] "Monat"
## [2] "Alternative.fÃ.r.Deutschland...Deutschland."
## [3] "Sozialdemokratische.Partei.Deutschlands...Deutschland."
## [4] "Freie.Demokratische.Partei...Deutschland."
## [5] "BÃ.ndnis.90.Die.GrÃ.nen...Deutschland."
## [6] "Die.Linke...Deutschland."
## [7] "Partei.Mensch.Umwelt.Tierschutz...Deutschland."
## [8] "Christlich.Demokratische.Union.Deutschlands...Deutschland."
## [9] "Marxistisch.Leninistische.Partei.Deutschlands...Deutschland."
## [10] "Nationaldemokratische.Partei.Deutschlands...Deutschland."names(c) <- c('Monat', 'AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke', 'Tierschutzpartei', 'CDU', 'MLPD', 'NPD')Abbildung erstellen
Schritt 1 anzeigen
Zunächst müssen wir das Paket ggplot2 laden:
library(ggplot2)## Warning: Paket 'ggplot2' wurde unter R Version 4.1.2 erstelltWie bei den Tipps oder auch bei der Kurzeinführung in ggplot2 besprochen, erwartet der ggplot-Befehl einen Datensatz mit Variablen, die wir auf x- und y-Achse darstellen wollen und eventuell eine Gruppierungsvariable. Die x-Achse ist in unserem Fall sehr einfach: es ist die Zeit. Das Problem stellt die y-Achse dar: hierfür haben wir zur Zeit nicht 1 sondern 9 Variablen. Darüber hinaus sind diese 9 Variablen eine Mischung aus unserer y-Achse und der Gruppierungsvariable! Was wir benötigen, um eine klare Abbildung in ggplot2 zu erzeugen, ist ein Datensatz, der die drei “klassischen” Variablen enthält (x, y, Gruppe). Dafür können wir den reshape Befehl nutzen:
c_long <- reshape(c, # Ausgansdaten
varying = c('AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke', 'Tierschutzpartei', 'CDU', 'MLPD', 'NPD'),
# alle Variablen, die hinterher eine einzige Variable sein sollen
v.names = 'Prozent', # Name der neuen Variable
idvar = 'Monat', # Variable, die über alle Parteien gleich bleibt
timevar = 'Partei', # Name der Variable, die verschiedene Gruppen unterscheidet
times = c('AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke', 'Tierschutzpartei', 'CDU', 'MLPD', 'NPD'),
# Kodierung der Parteien auf dieser Gruppierungsvariable
direction = 'long') # Richtung der UmwandlungHier wird der Datensatz ins long-Format übertragen - er hat hinterher mehr Zeilen (ist also länger) als vorher. Das Gegenteil wäre das wide-Format, in dem ein Datensatz mehr Spalten bekommt (also breiter wird) als zuvor.
Mit diesem Datensatz können wir in ggplot2 direkt ein Liniendiagramm erzeugen:
ggplot(data = c_long, aes(x = Monat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') # Überschrift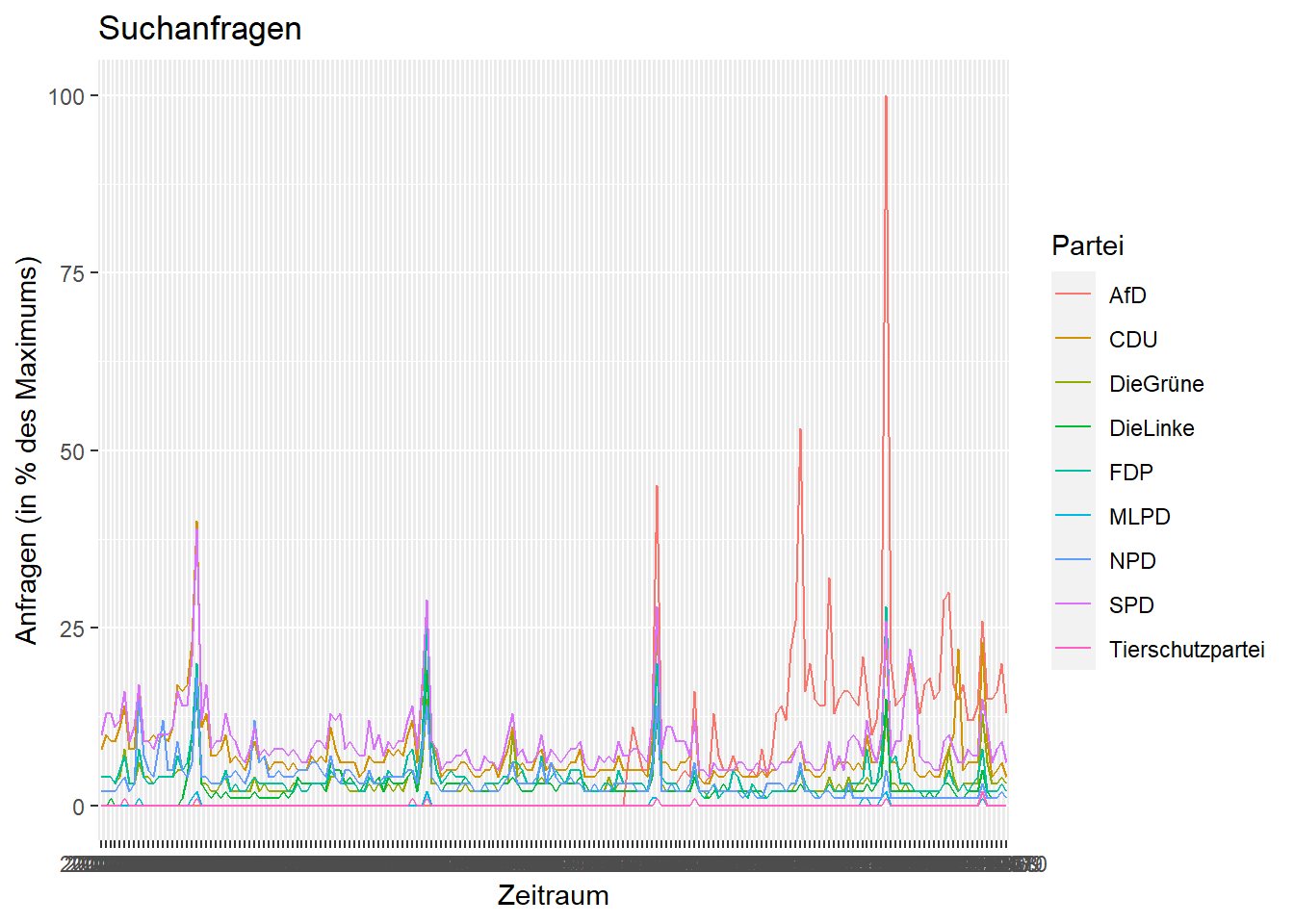
Schritt 2 anzeigen
Die Abbildung aus Schritt 1 ist noch nicht sonderlich schön. Das erste offensichtliche Manko ist, dass es unmöglich ist, die Zeit an der x-Achse abzulesen. Um diesen Zustand zu beheben, muss die Zeit in eine “echte” Zeitvariable im POSIXct-Format umgewandelt werden:
class(c_long$Monat)## [1] "character"Für die Umwandlung ins POSIXct-Format gibt es eine Funktion namens strptime. Diese funktioniert allerdings wesentlich besser, wenn die Ausgangsvariable eine character-Variable ist. Also müssen wir die Zeit erst in eine Text-Variable umwandeln (dafür erstellen wir vorsichtshalber eine neue Variable):
c_long$nMonat <- as.character(c_long$Monat)Aus der Hilfe zu strptime wird ersichtlich, dass immer mindestens Tag, Monat und Jahr in Zeitvariablen erwartet werden. Daher müssen wir der neuen Text-Variable noch einen Tag hinzufügen. Der genaue Tag macht dabei keinen Unterschied (weil unsere Daten ja nur monatlich sind) - wir nehmen einfach den 1. jeden Monats:
c_long$nMonat <- paste0(c_long$nMonat, '-01')
head(c_long$nMonat)## [1] "2004-01-01" "2004-02-01" "2004-03-01" "2004-04-01" "2004-05-01"
## [6] "2004-06-01"So hat die neue nMonat Variable ein typisches Zeitformat: Jahr-Monat-Tag. Dieses Format erkennt strptime leider nicht automatisch, also müssen wir via format-Argument ansagen, wie unsere Daten aussehen:
c_long$nMonat <- strptime(c_long$nMonat,
format="%Y-%m-%d") # Format des DatumsAus der Hilfe von strptime sehen wir, dass %Y Jahre (mit Jahrhunderten), %m Monate (in Zahlen) und %d Tage sind. Die Variable wird nur folgendermaßen klassifiziert.
class(c$nMonat)## [1] "NULL"Das ist zwar leider nicht die richtige Klasse, aber das Problem lässt sich schnell beheben:
c_long$nMonat <- as.POSIXct(c_long$nMonat)Wenn wir jetzt die Abbildung erneut erstellen, sieht die x-Achse schon viel besser aus:
ggplot(data = c_long, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') # Überschrift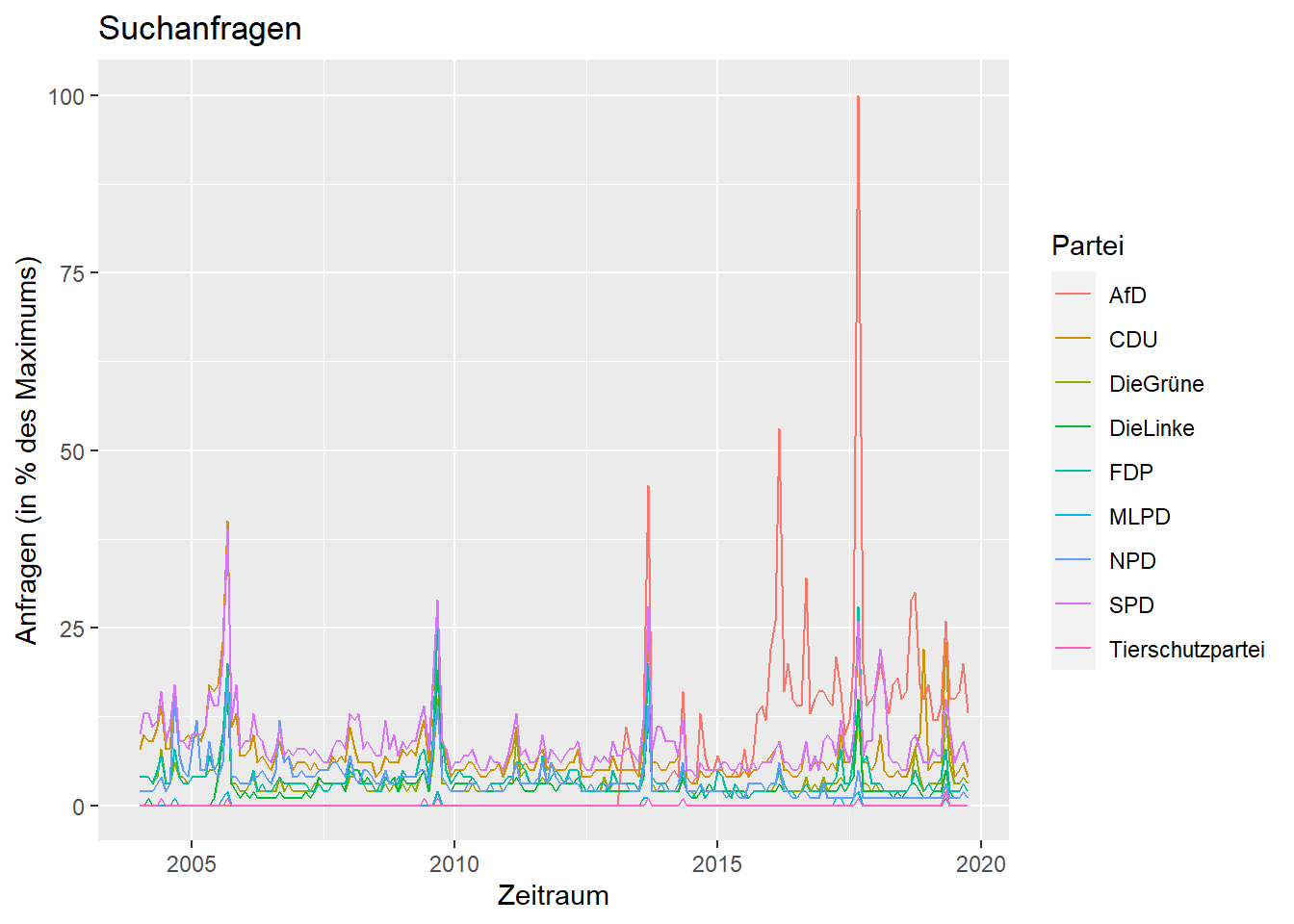
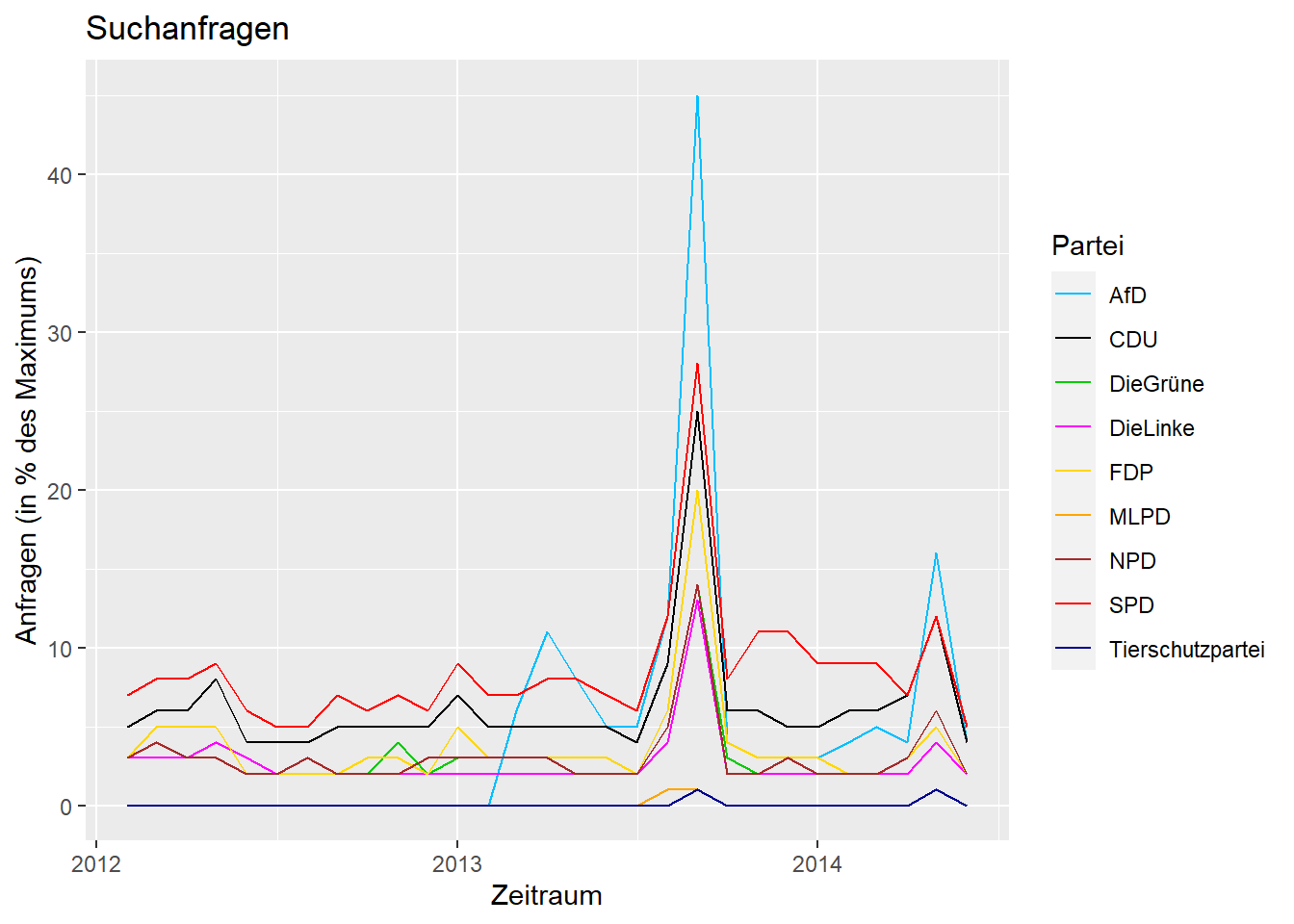
Um bestimmte Abschnitte näher unter die Lupe zu nehmen, können wir jetzt Anhand der Zeitvariable spezifische Auswahlen treffen. Wenn wir uns z.B. den Zeitraum um die Bundestagswahl von 2013 näher angucken möchten, können wir uns auf die Jahre zwischen 2012 und 2014 konzentrieren:
wahl_2013 <- subset(c_long, subset = (nMonat < '2014-07-01' & nMonat > '2012-01-01'))
ggplot(data = wahl_2013, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') # Überschrift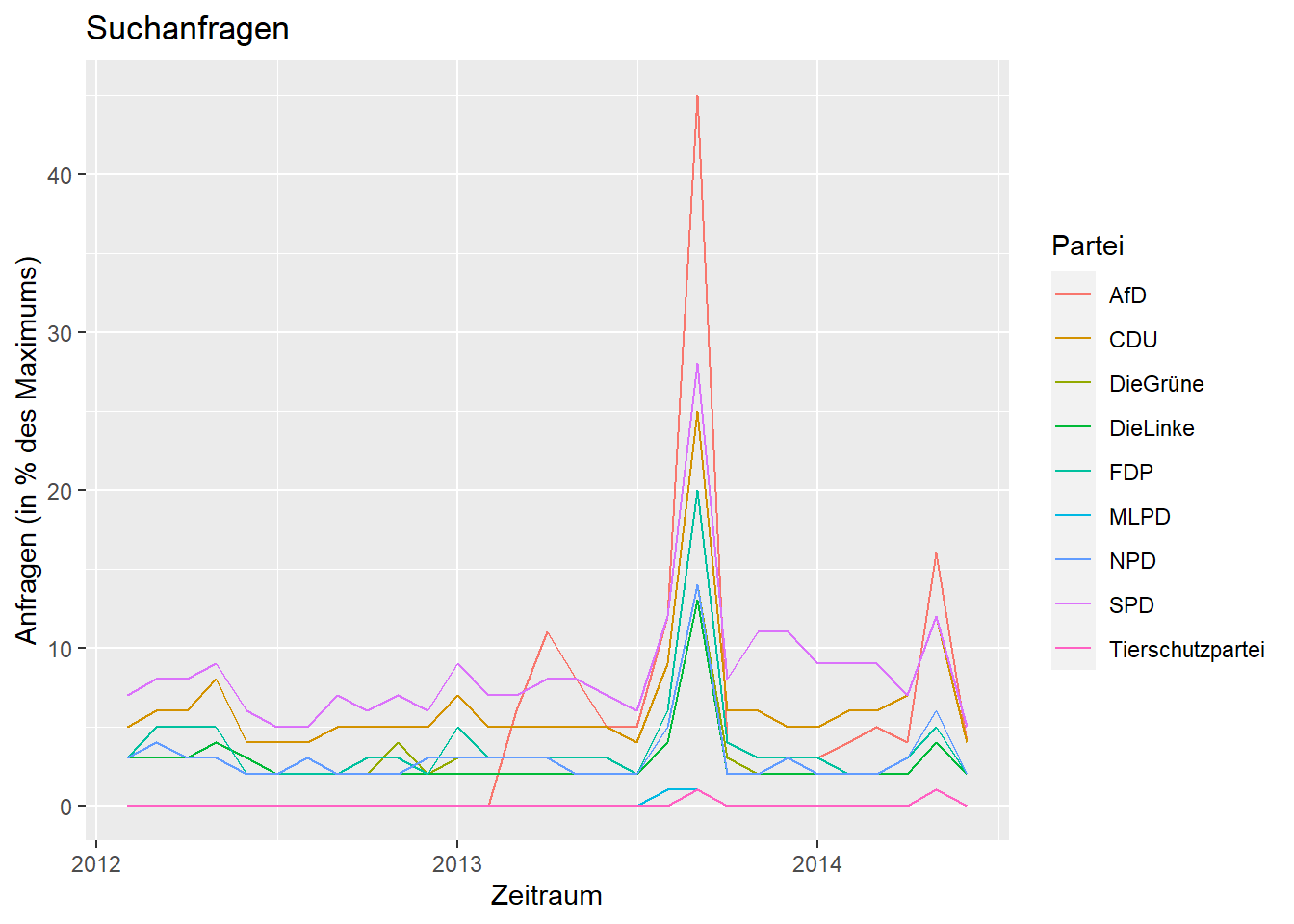
Ein weiteres Manko bei diesen Abbildungen sind die verwirrenden Farben. In Deutschland gibt es ein relativ konsistent genutzes Schema, nach dem die politische Parteien durch bestimmte Farben dargestellt werden. Wir können dieses Schema auch in unserer Abbildungen nutzen, wenn wir die Farben per Hand vergeben und dann mit scale_color_manual in unseren Plot aufnehmen:
farben <- c('AfD' = 'deepskyblue', 'CDU' = 'black', 'DieGrüne' = 'green3',
'DieLinke' = 'magenta', 'FDP' = 'gold', 'MLPD' = 'orange',
'NPD' = 'brown', 'SPD' = 'red', 'Tierschutzpartei' = 'darkblue')
ggplot(data = wahl_2013, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') + # Überschrift
scale_color_manual(values = farben)