
Lösungen
Vorwarnung
Achtung! Im Folgenden werden die Lösungen für das siebte Projekt präsentiert. Falls du das Projekt noch nicht vollständig bearbeitet hast, nutze zunächst die Tipps. Sofern dir die Tipps für einen Teil nicht geholfen haben, kannst du die Lösungen dafür benutzen, um einen Schritt weiterzukommen und beim nächsten Abschnitt weiterzumachen.
Lösungen zu Teil 1: Darstellung der Suchanfragen verschiedener Parteien
Hier sind die Lösungen zum ersten Abschnitt des Projekts “Darstellung der Suchanfragen”. Die Lösungen decken mitunter alle Vorgaben aus der Problemstellung ab, wobei die Style-Aspekte der App deutlich vertieft werden. Das heißt, hier in den Lösungen werden dir nicht nur die relevanten Schritte zum Endprodukt gezeigt, sondern auch einige Möglichkeiten, dein Endprodukt besonders gut aussehen zu lassen. Da sich die Lösung auf eine unübersichtliche Anzahl an Code-Zeilen beläuft, wird die Erklärung im Folgenden auf 4 Abschnitte aufgeteilt, die du bereits aus den Tipps kennen solltest.
Lösung 1 - Aufbereitung der Daten
Zuallererst müssen die Datensätze zur Benutzung in den Diagrammen aufbereitet werden. Dafür werden die beiden Datensätze p1_long und p1_wide aus dem ersten Projekt auf dieser Website verwendet. Damit du die nächsten Schritte nachvollziehen kannst, solltest du am selben Punkt starten und die beiden Datensätze hier und hier herunterladen und in den Ordner einfügen, in dem du bei diesem Projekt arbeiten willst (dein Working Directory).
Jetzt kannst du die beiden Datensätze mit dem Befehl readRDS laden:
p1_wide <- readRDS('p1_wide.rds')
p1_long <- readRDS('p1_long.rds')Falls du bereits Projekt 1 gemacht hast, sollte dir der nächste Schritt bereits bekannt sein. Im ersten Projekt hat sich ein Problem mit dem Datum ergeben, das eine ordnungsgemäße Beschriftung eines Diagramms mit Datum unmöglich gemacht hat. Das liegt daran, dass die Variable Monat in den Datensätzen als factor vorliegt und von R deshalb nicht als Datum erkannt werden kann. Damit das der Fall ist, müssen die Zeitangaben als POSIXct vorliegen. Nutze dafür einfach dein R-Script aus dem ersten Projekt. Falls du das erste Projekt noch nicht bearbeitet hast, kannst du die nötigen Schritte mit Erklärung im Folgenden nachlesen.
Umwandlung der Zeitangaben in POSIXct
Schau dir zunächst einmal die Struktur der Datumsvariable an.
str(p1_long$Monat)## Factor w/ 190 levels "2004-01","2004-02",..: 1 2 3 4 5 6 7 8 9 10 ...Wie bereits erwähnt, liegt das Datum als factor vor und kann deshalb von R nicht als Datum behandelt werden. R erkennt bei einem factor nur, dass es sich um eine Kette von Symbolen handelt, der ohne jeglichen Sinn existiert und als Kategoriename betrachtet werden kann. In anderen Worten: die Kategorie factor beschreibt Variablen mit vorgegebenen möglichen unsortierten Ausprägungen.
Der erste Schritt, um das zu verändern, ist die Umwandlung von factor in character. Dies sind Variablen, die aus freiem Text bestehen und dadurch unendlich viele mögliche Ausprägungen zulassen, was einer Datumsvariable zumindest näher kommt.
p1_long$nMonat <- as.character(p1_long$Monat)Um Fehler zu vermeiden, wird ab diesem Schritt eine neue Datums-Variable erstellt und im Folgenden für die Umwandlung in POSIXct verwendet.
Im nächsten Schritt muss die neu erstellte Variable nun um mehrere Zeichen erweitert werden. Dafür wählen wir die drei Zeichen -01, die mit dem paste0-Befehl an alle Daten angehängt werden kann, um einen Tag zu symbolisieren (Für uns ist irrelevant, welche Zahl verwendet wird, da der Datensatz sowieso nur aus monatlichen Daten besteht.).
p1_long$nMonat <- paste0(p1_long$nMonat, '-01')
head(p1_long$nMonat)## [1] "2004-01-01" "2004-02-01" "2004-03-01" "2004-04-01" "2004-05-01"
## [6] "2004-06-01"Warum muss man das zu diesem Zeitpunkt machen? Warum braucht man die Datumsvariable in diesem Format: JJJJ-MM-TT?
Der Grund dafür liegt im folgenden Befehl, der die Variable von einem charcter in eine Datumsvariable umwandeln soll. Dieser Befehl besitzt nur eingeschränkte, vorgegebene Formate für Daten, die er als solche erkennen und dementsprechend umwandeln kann. Das Format JJJJ-MM ist keines dieser Formate, weshalb die Datumsvariable nMonat um einen zufälligen Tag (ich habe den den ersten Tag des Monats genommen) erweitert werden muss.
Der Befehl, um den es geht, heißt strptime und arbeitet mit dem format-Argument, wobei das vorliegende Format der Daten für die Umwandlung spezifiziert werden muss.
p1_long$nMonat <- strptime(p1_long$nMonat, format="%Y-%m-%d")
str(p1_long$nMonat)## POSIXlt[1:1710], format: "2004-01-01" "2004-02-01" "2004-03-01" "2004-04-01" "2004-05-01" ...Das Datum liegt nun in der POSIXlt-Form vor. Damit erkennt R die Variable nMonat bereits als Datum, doch wir brauchen die Variable als POSIXct. Dafür kann man einfach den Befehl as.POSIXct benutzen.
p1_long$nMonat <- as.POSIXct(p1_long$nMonat)
str(p1_long$nMonat)## POSIXct[1:1710], format: "2004-01-01" "2004-02-01" "2004-03-01" "2004-04-01" "2004-05-01" ...Damit wurde die Datumsvariable erfolgreich von einem factor in ein POSIXct umgewandelt. Genau das Gleiche man mit dem zweiten Datensatz (p1_wide) und das Problem mit den Zeitangaben ist vollständig gelöst.
p1_wide$nMonat <- as.character(p1_wide$Monat)
p1_wide$nMonat <- paste0(p1_wide$nMonat, '-01')
p1_wide$nMonat <- strptime(p1_wide$nMonat, format="%Y-%m-%d")
p1_wide$nMonat <- as.POSIXct(p1_wide$nMonat)Wenn du die Datumsvariable erfolgreich umgewandelt hast, müssen nur noch zwei Sachen für eine vollständige Vorbereitung durchgeführt werden.
Zum Einen wird im Folgenden die Abbildung aus Projekt 1 benutzt. Diese Abbildung benutzt zur Zuweisung von Farben zu den politischen Parteien einen Vektor farben. Diesen kann man einfach aus Projekt 1 übernehmen.
farben <- c('AfD' = 'deepskyblue', 'CDU' = 'black', 'DieGrüne' = 'green3',
'DieLinke' = 'magenta', 'FDP' = 'gold', 'MLPD' = 'orange',
'NPD' = 'brown', 'SPD' = 'red', 'Tierschutzpartei' = 'darkblue')Außerdem ist in der Aufgabenstellung ein Liniendiagramm zur Darstellung der kumulativen Suchhäufigkeiten im zeitlichen Verlauf gefordert. An sich ist diese Grafik identisch zum Liniendiagramm aus Projekt 1 mit dem Unterschied, dass hier eine andere Variable auf der y-Achse abgebildet werden soll. Deshalb werden neue y-Werte benötigt, die man am besten im p1_long-Datensatz hinzufügt.
Für die Umsetzung dieser Anforderung muss man sich der Struktur des Datensatzes bewusst sein. Zu jeder Partei gibt es Daten für 190 Monate, die alle in der selben Spalte dargestellt werden (Variable Prozent). Eine solche Variable wird nun für die kumulierten Prozente benötigt. Dafür kann man jedoch nicht für jeden Eintrag einfach die Summe von Zeile 1 bis Zeile X bilden, da sich so die Prozente der verschiedenen Parteien vermischen würden.
Aus diesem Grund sind im Folgenden zwei Funktionen von großer Relevanz: cumsum und tapply.
cumsum berechnet kumulierte Summen und speichert diese in einer Liste ab. Damit hat man bereits die passende Rechenoperation für die Berechnung der Prozent_kumuliert-Variable. Doch mit dieser Funktion allein stößt man auf Probleme, da cumsum nicht zwischen den verschiedenen Parteien unterscheidet, sodass diese alle Prozentangaben aus p1_long$Prozent aufaddiert und nicht bei jeder Partei erneut bei Null beginnt. Um dieses Problem zu lösen, kann man die tapply-Funktion verwenden. Diese kann bestimmen, dass auf eine bestimmte Variable (p1_long$Prozent) in Abhängigkeit von einer anderen Variable (p1_long$Partei) eine definierte Funktion (cumsum) angewendet wird. Nun steht nur noch eine Problematik bevor: Die errechneten Daten liegen in Listen-Form vor und nicht als Vektor. Dafür muss man das Ganze in die unlist-Funktion packen, die die Liste in einen einfachen Vektor umwandelt.
p1_long$Prozent_kumuliert <- unlist(tapply(p1_long$Prozent, p1_long$Partei, cumsum))Führt man diesen Befehl nun ohne Weiteres aus, dann kommt es zu einem bestimmten Fehler. Schaut man sich die errechneten kumulierten Prozente an, dann stimmen diese größtenteils nicht mit den Veränderungen in p1_long$Prozent überein. Das liegt daran, dass tapply die kumulierten Summen nicht nur mit cumsum in Abhängigkeit von p1_long$Partei berechnet, sondern diese Daten auch nach der alphabetischen Reihenfolge der Parteien ordnet. Damit also die beiden Variablen Prozent und Prozent_kumuliert zusammenpassen, müssen die Zeilen in p1_long zunächst derart angeordnet werden, dass die Parteien in alphabetischer Reihenfolge vorliegen. Das erreicht man mithilfe des order-Befehls.
p1_long <- p1_long[order(p1_long$Partei), ] #Die Zeilen sollen nach der Variable "Partei" (alphabetisch) geordnet werden.
p1_long$Prozent_kumuliert <- unlist(tapply(p1_long$Prozent, p1_long$Partei, cumsum))Damit hat man nun erfolgreich eine Variable mit den kumulierten Prozentangaben für alle Parteien bestimmt.
Weitere Möglichkeit
Eine andere richtige, aber umständlichere Methode siehst du im folgenden R-Code:
for (i in 1:190) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[1:i])}
for (i in 191:380) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[191:i])}
for (i in 381:570) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[381:i])}
for (i in 571:760) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[571:i])}
for (i in 761:950) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[761:i])}
for (i in 951:1140) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[951:i])}
for (i in 1141:1330) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[1141:i])}
for (i in 1331:1520) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[1331:i])}
for (i in 1521:1710) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[1521:i])}for (i in 1:190) {p1_long$Prozent_kumuliert[i] <- sum(p1_long$Prozent[1:i])} aus, dann setzt diese Funktion für i alle Werte von 1 bis 190 ein. Dieses i beschreibt die Zeile, in der sich die Funktion zu einem gewissen Zeitpunkt befindet. Befindet sich die Funktion beispielsweise bei i = 40 (also in Zeile 40), dann wird in der neuen Variable Prozent_kumuliert in der i-ten Zeile (also Zeile 40) ein Wert eingesetzt. Dieser Wert berechnet sich durch die Funktion sum(p1_long$Prozent[1:i]). Diese Funktion besagt, dass eine Summe aus den Werten der Variable Prozent von Zeile 1 bis Zeile i (in diesem Beispiel also Zeile 1 bis 40) gebildet werden soll.Lösung 2 - Erstellen der Diagramme
Wie in der Problemstellung deutlich wurde, soll es in diesem Projekt darum gehen, mindestens 4 Diagramme in eine App einzubeziehen. Damit Probleme mit der Erstellung dieser Diagramme von vorn herein ausgeschlossen werden können, werden diese hier vor der Erstellung der Bestandteile der App besprochen.
Liniendiagramm
Diagramm 1 soll ein Liniendiagramm der prozentualen Häufigkeit im Zeitverlauf sein. Dieses wurde bereits in Projekt 1 mit dem Paket ggplot2 erstellt und kann hier deshalb einfach übernommen werden:
#install.packages('ggplot2') --> musst du nur ausführen, sofern du das Paket noch nie benutzt hast
library(ggplot2)
ggplot(data = p1_long, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Monats-Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen deutscher Parteien') + # Überschrift
scale_color_manual(values = farben) + # Zuweisung Farbe-Partei
theme_bw() # Formatierung des Achsensystems (bw für black and white)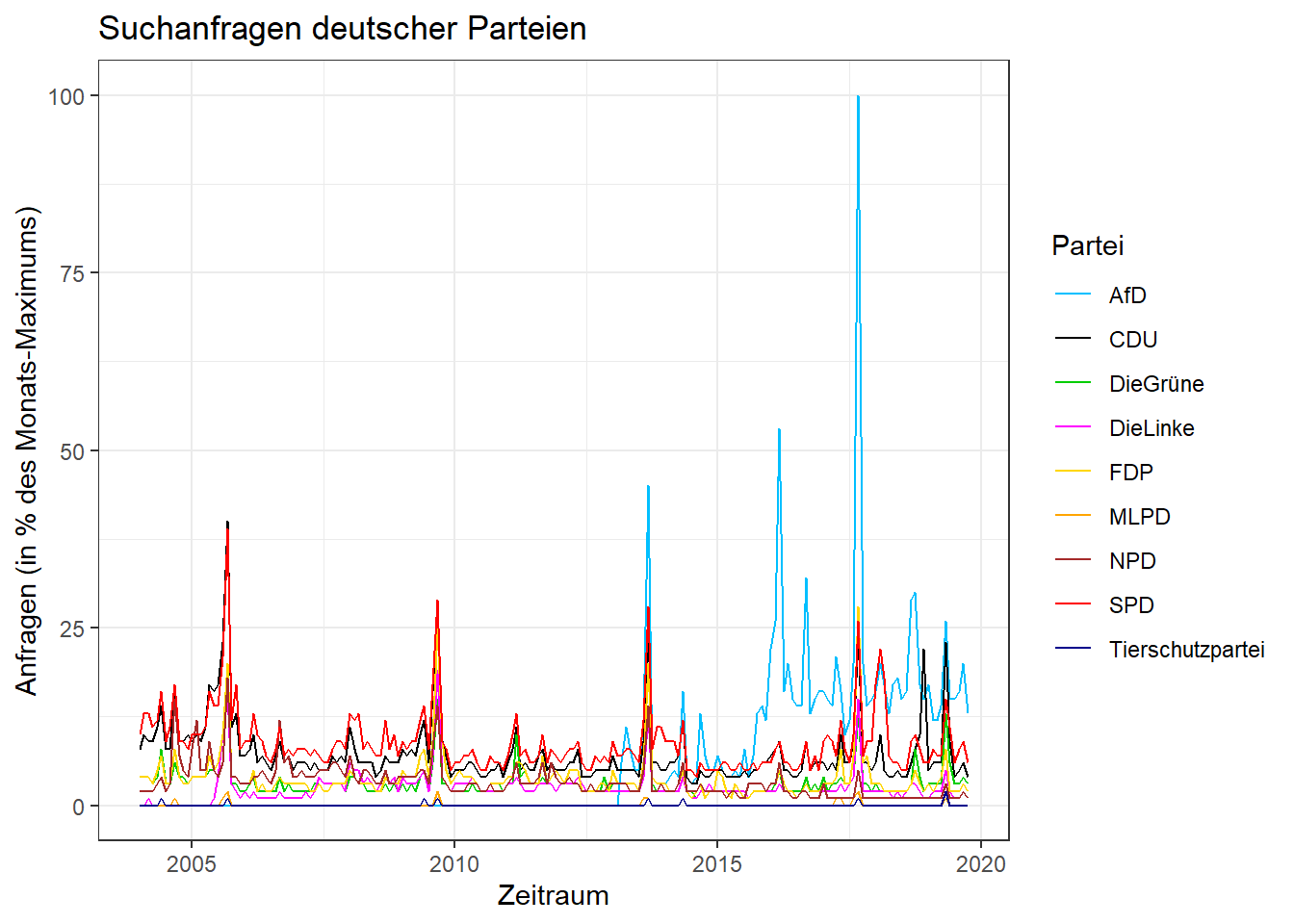
Liniendiagramm mit kumulierten Häufigkeiten
Diagramm 2 soll auch ein Liniendiagramm sein, nur dieses mal mit den kumulierten Häufigkeiten im Zeitverlauf. Im Prinzip ist das also genau das gleiche Diagramm mit Änderungen in Zeile 1 (bei aes muss ein anderes y angegeben werden) und in Zeile 4 (Bezeichnung der y-Achse sollte verändert werden). Dieses andere y wurde bereits in den Vorbereitungen erstellt und kann hier deshalb einfach verwendet werden.
ggplot(data = p1_long, aes(x = nMonat, y = Prozent_kumuliert, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Monats-Maximums/kumuliert)') + # Beschriftung y-Achse
ggtitle('Suchanfragen deutscher Parteien') + # Überschrift
scale_color_manual(values = farben) + # Zuweisung Farbe-Partei
theme_bw() # Formatierung des Achsensystems (bw für black and white)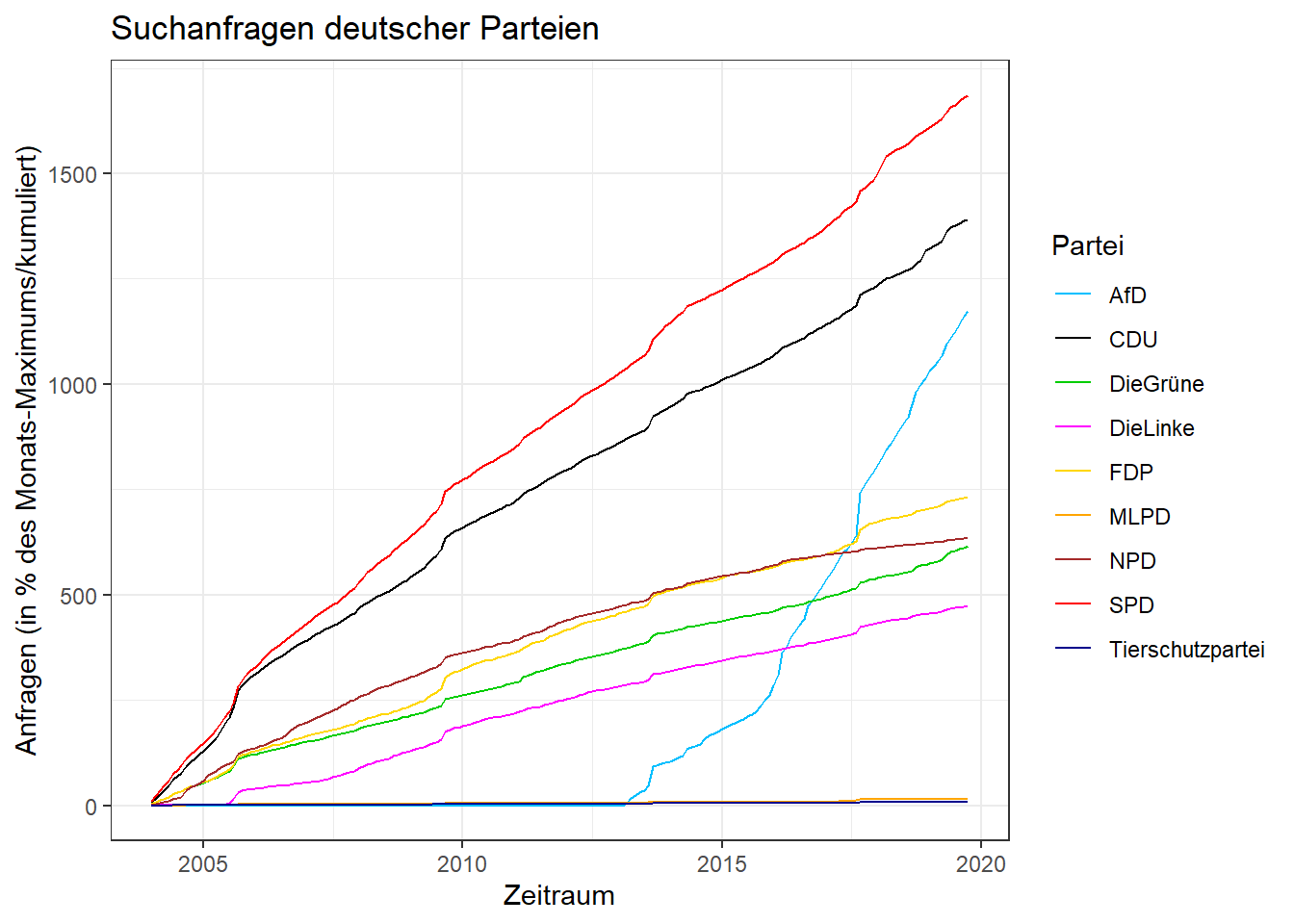
Balkendiagramm mit kumulierten Häufigkeiten
Diagramm 3 soll ein Balkendiagramm mit den kumulierten Häufigkeiten der Parteien sein. Dafür verwenden wir nun den p1_wide-Datensatz, da wir hier keine Zwischenwerte mehr brauchen: Die Balken sollen in diesem Fall lediglich die kumulierte Häufigkeit für einen bestimmten Zeitraum angeben. Das könnte man natürlich auch mit p1_long umsetzen, mit p1_wide ist es jedoch deutlich einfacher.
Für die Erstellung von Balkendiagrammen bietet R mehrere Möglichkeiten. Zum Einen kann man jenes mit der barplot-Funktion erstellen und zum Anderen kann man ggplot2 verwenden. Aufgrund der vielfältigeren Möglichkeiten von ggplot2 ist diese Variante jedoch dem barplot-Befehl vorzuziehen. Im Folgenden werden dir beide Möglichkeiten präsentiert, doch im späteren Verlauf verwenden wir die praktischere (aber kompliziertere) ggplot2-Version.
Damit man mit ggplot2 ein Balkendiagramm erstellen kann, muss man zunächst einen neuen Datensatz aus p1_wide erstellen. Das macht hier Sinn, da ggplot2 für ein Balkendiagramm nur einen Datensatz als Input annimmt, der in einer Zeile die “Benennung” der Balken und in einer anderen die Höhe der Balken beinhaltet. Einen solchen Datensatz erhält man, indem man die Namen der Spalten 2 bis 10 von p1_wide und die Summen der Prozentangaben der Spalten 2 bis 10 zu einem Datensatz zusammenfügt (Spalte 2 bis 10, da man die Datumsvariablen nicht für das Diagramm benötigt). Um in jenem Datensatz die Variablen besser auswählen zu können, sollte man dann noch die Variablennamen ändern.
p1_new <- data.frame(names(p1_wide[, 2:10]), colSums(p1_wide[, 2:10]))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")Mit diesem Datensatz kann man nun das Balkendiagramm erstellen:
ggplot(p1_new, aes(x = Partei, y = Prozent_kumuliert, fill = Partei)) + #X- und Y-Variable festlegen; "fill" bestimmt, wie/wonach die Balken gefüllt werden sollen
scale_fill_manual(values = farben) + #baut auf "fill"-Befehl auf und übermittelt die Farbkodierung
geom_col(color = "black") + #erstellt ein Balkendiagramm anhand der oben festgelegten Daten; "color" bestimmt die Farbe der Umrandung der Balken
theme_bw() + #bestimmt die grundlegende Formatierung von Achsen und Hintergrund (bw = black and white)
xlab("Partei") + #Beschriftung X-Achse
ylab("kumulierte Suchhäufigkeiten") + #Beschriftung Y-Achse
ggtitle("Balkendiagramm") #Titel des Diagramms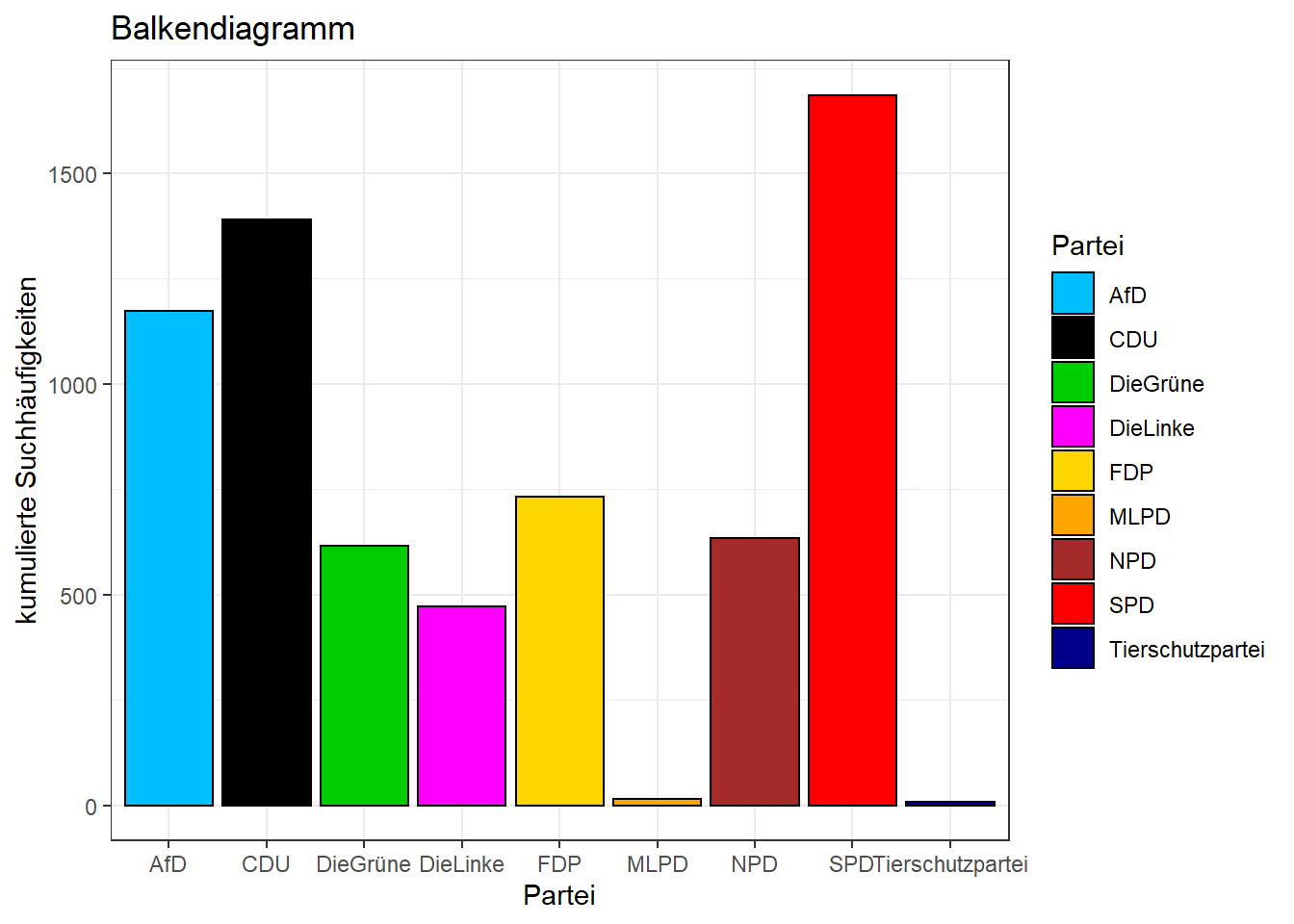
Falls du mit ggplot2 nicht zurechtkommst, kannst du das Balkendiagramm auch mit barplot erstellen. Neben eingeschränkten Möglichkeiten der Formatierung ist dort unter anderem keine Farbkodierung möglich. Falls du diesen Weg jedoch gewählt hast, kannst du dir diese Möglichkeit hier trotzdem anschauen.
Balkendiagramm mit barplot
Bei dem Befehl barplot fordert R als erstes Argument einen Vektor mit den Höhen der Balken (height). Mithilfe von p1_wide erhält man diese Höhen, indem man die Summen der Spalten mit colSums bilden lässt. Mit weiteren Argumenten zur Formatierung sieht das Balkendiagramm dann folgendermaßen aus:
barplot(height = colSums(p1_wide[,2:10]),
beside = FALSE, ylim = c(0, 2000),
col = c('deepskyblue', 'red', 'gold', 'green3', 'magenta',
'darkblue', 'black', 'orange', 'brown'),
main = "Balkendiagramm der kumulierten Häufigkeiten")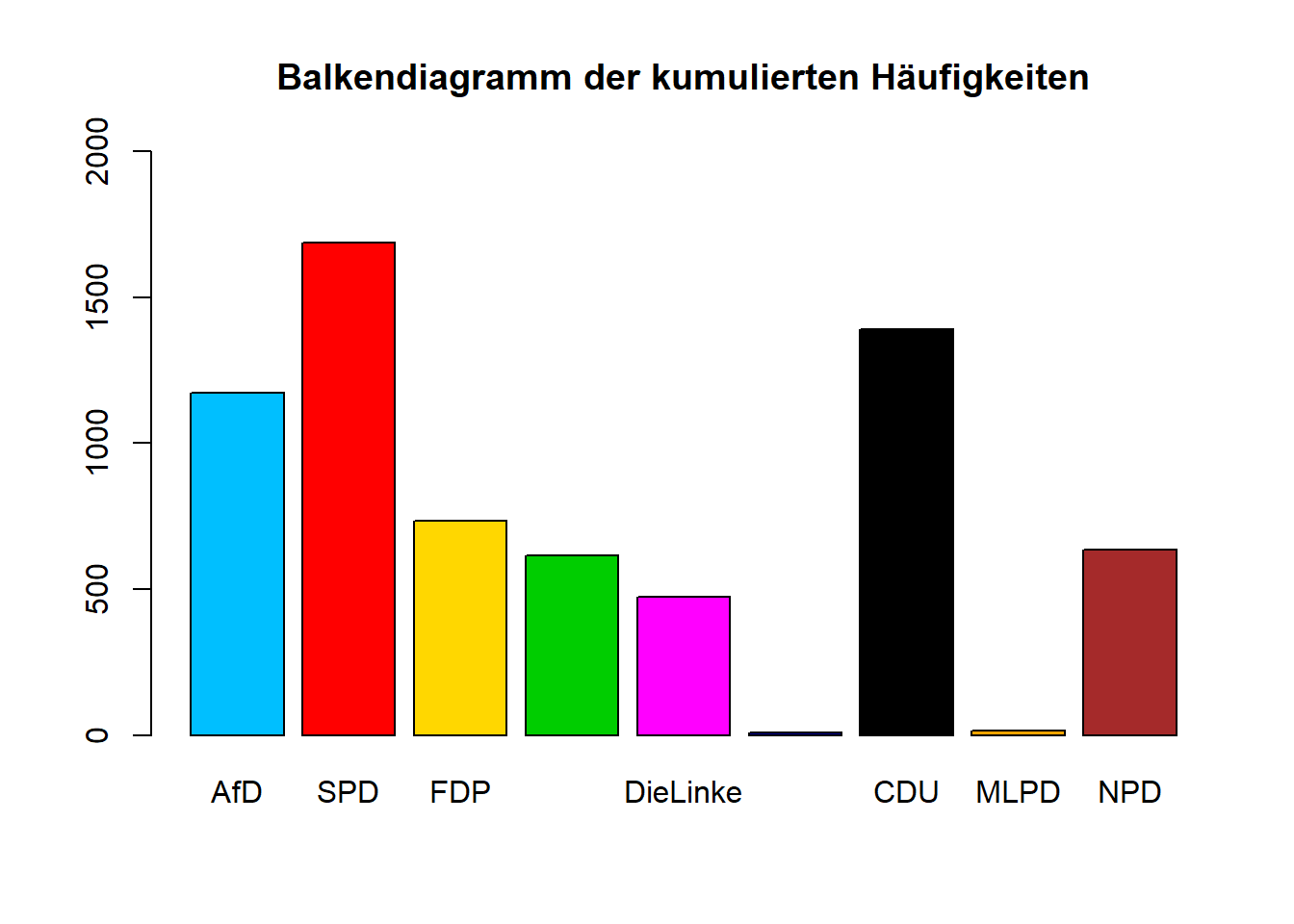
Wie bereits erwähnt, funktioniert das Diagramm auch mithilfe von p1_long. Falls du sehen willst, wie das Diagramm mit diesem Datensatz erstellt werden kann, schau dir den folgenden kleinen Abschnitt an. Für die nächsten Schritte zur Erstellung der App bietet sich der Gebrauch von p1_long jedoch nicht so sehr an, weshalb für dieses Diagramm die Variante mit p1_wide benutzt werden sollte.
Mit p1_long gestaltet sich die Auswahl der korrekten Werte für die Höhen aus der Variable Prozent_kumuliert etwas komplizierter, da die Werte aller Parteien in einer Spalte liegen. Aus diesem Grund muss man hier bestimmte Zeilen dieser Variable für die Höhen auswählen. Bei dem vollständigen Datensatz mit 1710 Zeilen wissen wir, dass es zu jeder Partei 190 Daten gibt. Die relevanten Höhen liegen also in den Zeilen 190, 380, 570, … Damit wir dort heran kommen, benutzen wir vereinfacht den seq-Befehl. Dieser ermöglicht es, aus einer Zahlenspanne von A bis B jede X-te Zahl auszuwählen (genereller Aufbau: seq(A, B, X)). Das sieht dann für den gesamten Datensatz folgendermaßen aus:
barplot(height = p1_long$Prozent_kumuliert[seq(0, 1710, 190)],
beside = FALSE, ylim = c(0, 2000),
col = c('deepskyblue', 'red', 'gold', 'green3', 'magenta',
'darkblue', 'black', 'orange', 'brown'),
names.arg = c('AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke',
'Tierschutzpartei', 'CDU', 'MLPD', 'NPD'),
main = "Balkendiagramm der kumulierten Häufigkeiten")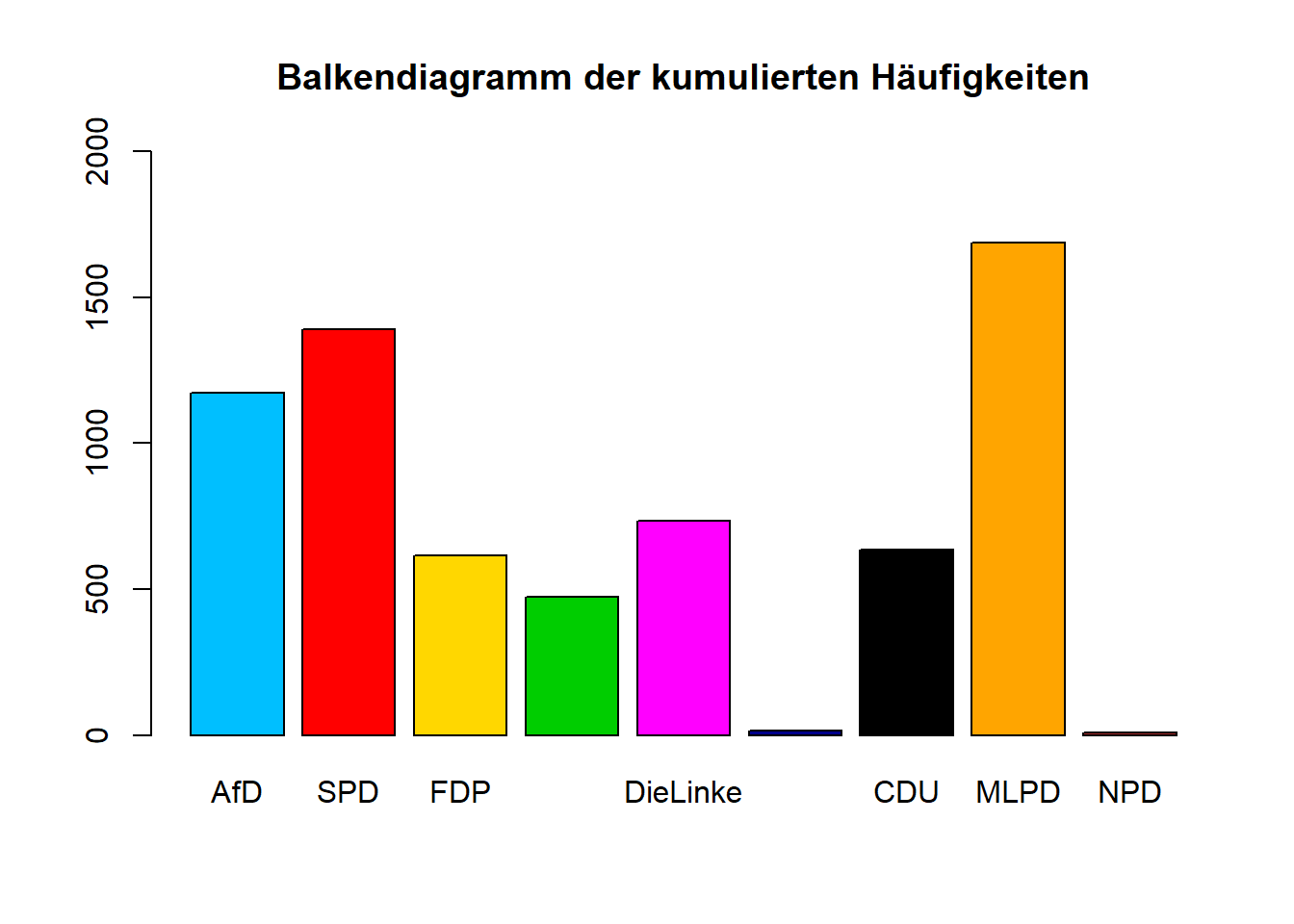
Damit das Ganze dann noch etwas reaktiver ist, also in der Lage ist, auf mehrere Modifikationen des Datensatzes zu reagieren (beispielsweise die Reduktion auf eine bestimmte Zeitspanne), kann man den Befehl dann noch folgendermaßen modifizieren:
barplot(height = p1_long$Prozent_kumuliert[
seq(0, length(p1_long$Prozent_kumuliert), length(p1_long$Prozent_kumuliert)/9)
],
beside = FALSE, ylim = c(0, 2000),
col = c('deepskyblue', 'red', 'gold', 'green3', 'magenta',
'darkblue', 'black', 'orange', 'brown'),
names.arg = c('AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke',
'Tierschutzpartei', 'CDU', 'MLPD', 'NPD'),
main = "Balkendiagramm der kumulierten Häufigkeiten")barplot-Befehls aufs Neue bestimmt. Im späteren Verlauf dieses Abschnitts des Projekts wird deutlich, warum gerade das von großer Wichtigkeit ist. Jedoch ist darauf hinzuweisen, dass die Variante mit p1_wide deutlich einfacher ist.Kuchendiagramm mit kumulierten Häufigkeiten
Diagramm 4 soll ein Kuchendiagramm mit der kumulierten Häufigkeit der Parteien sein. Hierfür werden die gleichen Daten wie in Diagramm 3 benötigt. Es gibt also wiederum die Möglichkeit, das Diagramm mit p1_long oder p1_wide zu erstellen. Doch mit p1_wide ist es vermutlich einfacher, weshalb im Folgenden auch nur dieser Weg betrachtet wird (für Erklärung der Erstellung der Grafik mit p1_long siehe oben).
Auch für die Erstellung von Kuchendiagrammen können in R entweder die pie-Funktion oder ggplot2 verwendet werden.
Ebenso wie bei dem zuvor erstellten Balkendiagramm muss man zur Erstellung eines Kuchendiagramms mit ggplot2 aus p1_wide einen neuen Datensatz erstellen (auch hier sollte man wiederum der Einfachheit halber die Variablen manuell benennen).
p1_new <- data.frame(names(p1_wide[, 2:10]), colSums(p1_wide[, 2:10]))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")Mit diesem Datensatz kann man nun ein Kuchendiagramm mit ggplot2 erstellen. Da es jedoch keine explizite Funktion für Kuchendiagramme gibt, muss man einen alternativen Weg zum Ziel finden. Unser Vorgehen siehst du im Folgenden:
ggplot(p1_new, aes(x = "", y = Prozent_kumuliert, fill = Partei)) + # X bleibt leer, da die Beschriftung manuell eingefügt werden muss; Y = Werte zur Erstellung des Diagramms; "fill" = wonach sollen die Abschnitte des Kuchens gefärbt werden
scale_fill_manual(values = farben) + # Farbkodierung der Parteien
geom_bar(stat = "identity", width = 1) + # Grundstruktur: Balkendiagramm [stat = "identity" erreicht das Gleiche, wie wenn man von vorn herein geom_col() benutzt]
coord_polar("y", start = 0) + # hiermit überführt man das Balkendiagramm in ein Kuchendiagramm
theme_void() + # void = kein Hintergrund, keine Achsen etc., alles weiß
ggtitle("Kuchendiagramm") + # Titel des Plots
theme(axis.ticks = element_blank(), # keine Achsenmarkierungen/Skalierung
axis.text.y = element_blank(), # keine Beschriftung auf der y-Achse (Skala)
axis.text.x = element_text(colour = 'black'), # Beschriftung auf der x-Achse in schwarz (Skala bzw. Parteinamen)
axis.title = element_blank()) + # keine Labels für beide Achsen
scale_y_continuous( # Erstellung der Beschriftung der x-Achse außerhalb des Kuchens
breaks = cumsum(p1_new$Prozent_kumuliert) - p1_new$Prozent_kumuliert/2, # Platzierung der Beschriftung (in der Mitte des jeweiligen Abschnitts)
labels = p1_new$Partei) # Zur Beschriftung sollen die Parteinamen verwendet werden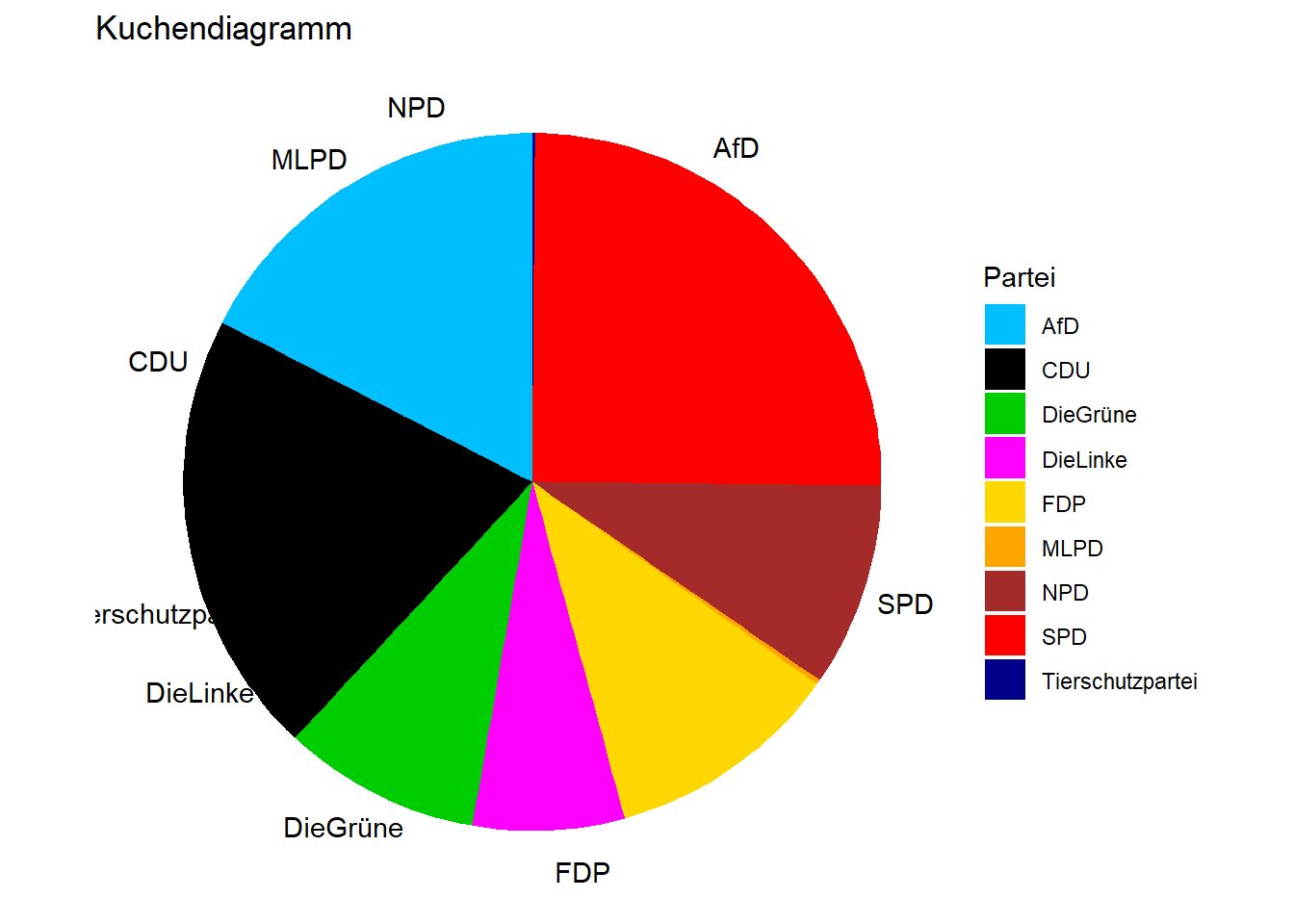
Wie du sehen kannst, funktioniert das in der Art fast einwandfrei. Die Funktion konnte erfolgreich ein Kuchendiagramm mit den gegebenen neun Parteien erstellen. Das einzige Problem ist, dass die Beschriftungen nicht mit den Kuchenabschnitten übereinstimmen. Das liegt daran, dass ggplot nicht die ursprüngliche Reihenfolge der Parteien aus dem Datensatz p1_new übernimmt, sondern die Abschnitte automatisch in alphabetischer Reihenfolge gegen den Uhrzeigersinn darstellt. Damit also Kuchenstücke und Beschriftung übereinstimmen, müssen die Parteien alphabetisch geordnet werden. Das kann mit dem order-Befehl umgesetzt werden mit dem Zusatz, dass die Parteien dieses Mal absteigend geordnet werden müssen (weil die Beschriftung im Uhrzeigersinn geschieht).
# Die Zeilen von p1_new werden nach der Variable "Partei" alphabetisch umsortiert. Dabei gilt decreasing = TRUE; unten im Alphabet (Z) soll im Datensatz also oben (Zeile 1) stehen.
p1_new <- p1_new[order(p1_new$Partei, decreasing = TRUE), ]
ggplot(p1_new, aes(x = "", y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
theme_void() +
ggtitle("Kuchendiagramm") +
theme(axis.ticks = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_text(colour = 'black'),
axis.title = element_blank()) +
scale_y_continuous(
breaks = cumsum(p1_new$Prozent_kumuliert) - p1_new$Prozent_kumuliert/2,
labels = p1_new$Partei)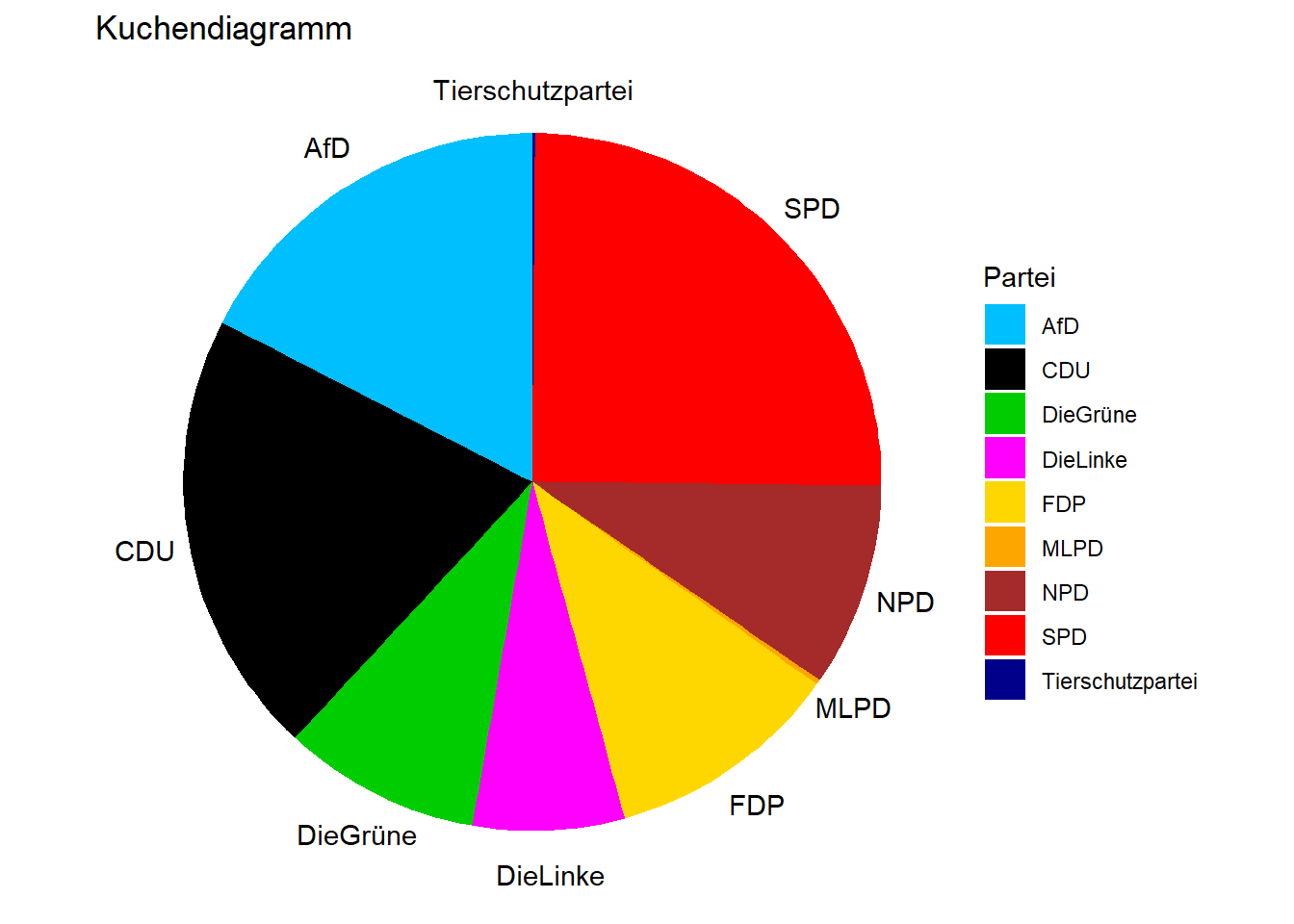
Kuchendiagramm mit pie
Die pie-Funktion arbeitet mit den Argumenten x (für die Daten), main (für den Titel), col (für die Farben) und vielen mehr. In diesem Fall sieht das dann folgendermaßen aus:
pie(x = colSums(p1_wide[,2:10]),
main = 'Kuchendiagramm der kumulierten Häufigkeiten',
col = c('deepskyblue', 'red', 'gold', 'green3', 'magenta',
'darkblue', 'black', 'orange', 'brown')
)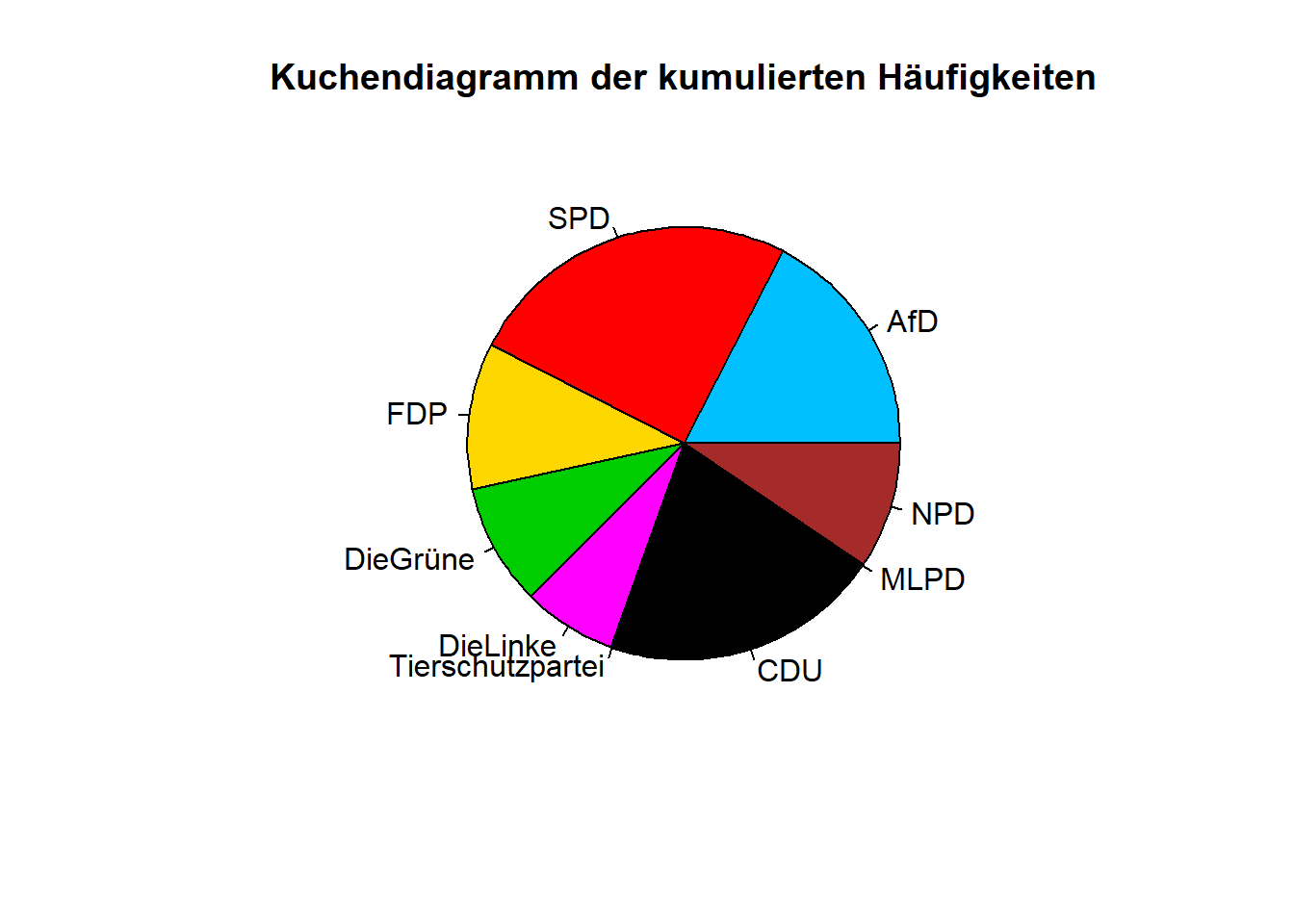
Bei pie muss man einbußen bei der Farbkodierung akzeptieren. Die Farben können hier nicht explizit den Parteien zugewiesen werden, sondern werden “von vorne nach hinten” automatisch vergeben.
pie kann man Kuchendiagramme in deutlich kürzerer Zeit und deutlich einfacherer erstellen.Damit wurden alle Vorbereitung getroffen und nötige Inhalte für die App erstellt. Nun kann mit der Erstellung der eigentlich App begonnen werden. Der nächste Abschnitt behandelt zunächst einmal das User Interface.
Lösung 3 - User Interface
An diesem Punkt beginnen wir, mit dem shiny-Paket zu arbeiten. Aus diesem Grund sollte dieses spätestens jetzt heruntergeladen werden und dann in die aktuelle Sitzung geladen werden.
#install.packages("shiny") -> nur notwendig, sofern du das Paket nicht bereits heruntergeladen hast
library(shiny)Die Problemstellung gibt für die Gestaltung des User Interfaces fünf Bestandteile vor:
- Die Daten sollen in einem Diagramm dargestellt werden. Die Darstellungsform soll wählbar sein.
- Der Titel des Diagramms soll durch die Anwender:innen definierbar sein.
- Die angezeigten Parteien sollen manuell wählbar sein.
- Der dargestellte Zeitraum soll durch die Anwender:innen bestimmbar sein.
- Zusatz: Verwendung eines Action Buttons
WICHTIG!: Alle reaktiven Inhalte, die durch die Inputs beeinflusst werden, können nicht im User Interface ausgeführt und erstellt werden. Aus diesem Grund wird hier mit InputId’s gearbeitet, deren Inhalt erst im Server spezfiziert wird.
1.) Die Diagramme für die Darstellung der Daten haben wir bereits im zweiten Teilabschnitt erstellt. Diese sollen durch eine navbarPage in die App eingearbeitet werden. Dadurch wird immer nur eins der Diagramme angezeigt. Mithilfe der Navigationsleiste kann dann zwischen den verschiedenen Diagrammen hin und her geschaltet werden. Innerhalb der navbarPage legt man mit tabPanel-Befehlen die Inhalte der Unterseiten fest. Dabei legt man zuerst fest, wie der Name der Unterseite in der Navigationsleiste lauten soll, und danach was auf dieser Unterseite abgebildet werden soll. Das Endresultat kann dann folgendermaßen aussehen:
navbarPage(strong("Darstellungsart"), # Titel der Navigationsleiste (steht ganz links), 'strong()' macht die Schrift fett
tabPanel("Liniendiagramm", # Titel der Unterseite
plotOutput("Liniendiagramm")), # Inhalt der Unterseite -> Hier soll der Output mit der Bezeichnung "Liniendiagramm" dargestellt werden.
tabPanel("Liniendiagramm (kumuliert)",
plotOutput("Liniendiagramm_kumuliert")),
tabPanel("Balkendiagramm (kumuliert)",
plotOutput("Balkendiagramm")),
tabPanel("Kuchendiagramm (kumuliert)",
plotOutput("Kuchendiagramm")))Wie hier zu sehen ist, können die Diagramme noch nicht im User Interface erstellt werden. Dafür werden sogenannte Platzhalter/Bezeichnungen eingeführt, die dann später mit Inhalt gefüllt werden. So wird zum Beispiel die erste Unterseite der Navigationsleiste mit plotOutput("Liniendiagramm") gefüllt. Das bedeutet, dass an diesem Punkt der Output mit der Bezeichnung Liniendiagramm dargestellt werden soll. Was dieser Output ist und wie er erstellt wird, ist hier noch nicht spezifiziert, da das Liniendiagramm (wie auch die anderen Diagramme) von den folgenden drei Inputs abhängig sein wird. Und wie bereits erwähnt: Im User Interface können nur statische Bestandteile der App erstellt werden.
2.) Die zweite Vorgabe aus der Problemstellung ist, dass der Titel der Diagramme durch die Anwender:innen der App definierbar sein soll. Das bedeutet, dass zusätzlich ein Eingabefeld für normalen Text benötigt wird. Dafür gibt es einen relativ simplen Befehl: textInput(). textInput() erstellt ein Input-Feld für normalen Text und benötigt dafür die Argumente inputId für die Bezeichnung des Inputs für die Wiederverwendung im Server und (falls erwünscht) label für die Beschriftung dieses Input-Feldes (Dort kann man für die Anwender:innen erklären, was im Input-Feld gefordert ist bzw. was die Funktion des Input-Feldes ist.).
textInput(inputId = "Titel", label = "Titel der Grafik")
3.) Die dritte Vorgabe ist, dass die im Diagramm angezeigten Parteien manuell wählbar sein sollen. Dafür braucht man einen Input, bei dem man für jede Partei manuell entscheiden kann, ob sie angezeigt werden soll oder nicht. Es wäre sehr umständlich für alle 9 Parteien ein eigenes Input-Feld mit den Möglichkeit JA und NEIN zu erstellen, deshalb fällt hier die günstigste Wahl auf ein checkboxGroupInput. Diese Input-Form ermöglicht es, für jede Partei durch Ankreuzen festzulegen, ob diese angezeigt werden soll oder nicht. Neben den bereits erklärten Argumenten unter 2.) kommen hier die Argumente inline und choices dazu. Mit choices kann man angeben, welche Möglichkeiten vorhanden sein sollen; in unserem Fall die neun im Datensatz vorhandenen Parteien. Mit inline kann man dann entscheiden, ob die Möglichkeiten untereinander oder “inline”, also in einer Linie, dargestellt werden sollen.
checkboxGroupInput(inputId = "Parteien",
label = "Parteien",
inline = TRUE,
choices = c("AfD", "SPD", "FDP", "DieGrüne", "DieLinke",
"Tierschutzpartei", "CDU", "MLPD", "NPD"))
4.) Die letzte Anforderung ist die Möglichkeit zur Eingrenzung des betrachteten Zeitintervalls. Für solche Funktionen hält shiny bereits ein spezialisiertes Input-Fenster parat: dateRangeInput(). Neben den Argumenten inputId und label kann man hier zusätzlich die Argumente start und format angeben. Mit format legt man das Format der Datumsangabe fest. Da diese Datumsangabe mit den Daten in den Datensätzen p1_long und p1_wide übereinstimmen sollten, sollte man sich hier ebenso für das Format "yyyy-mm-dd" entscheiden. Mit start kann man darüber hinaus die default-Einstellung des Startdatums in der App spezifizieren (end liegt standardmäßig auf dem aktuellen Datum; kann man auch festlegen, für diesen Fall aber nicht zwingend notwendig). Der R-Code dazu sieht dann folgendermaßen aus:
dateRangeInput(inputId = "Datum",
label = "Zeitspanne",
start = "2000-01-01",
format = "yyyy-mm-dd")
5.) Zusätzlich dazu kann man dem Ganzen auch noch einen sogenannten actionButton hinzufügen. Mithilfe von diesem actionButton kann man bewusst steuern, wann gewisse Veränderungen in den Input-Fenstern in den Output übernommen werden sollen.
actionButton(inputId = "Update", label = "Diagramm erzeugen")Jetzt kann man diese 5 Bestandteile einfach mal in ein User Interface zusammenfügen und ausführen. Dafür kann man den Standardaufbau einer shiny-App mithilfe des snippets shinyapp abrufen (während der Eingabe von “shinyapp” öffnen sich Vorschläge; daraus einfach ‘shinyapp – snippet’ auswählen und ENTER drücken) und alle Inputs bei ui einfügen:
ui <- fluidPage(
navbarPage(strong("Darstellungsart"),
tabPanel("Liniendiagramm",
plotOutput("Liniendiagramm")),
tabPanel("Liniendiagramm (kumuliert)",
plotOutput("Liniendiagramm_kumuliert")),
tabPanel("Balkendiagramm (kumuliert)",
plotOutput("Balkendiagramm")),
tabPanel("Kuchendiagramm (kumuliert)",
plotOutput("Kuchendiagramm"))),
dateRangeInput(inputId = "Datum",
label = "Zeitspanne",
start = "2000-01-01",
format = "yyyy-mm-dd"),
textInput(inputId = "Titel", label = "Titel der Grafik"),
checkboxGroupInput(inputId = "Parteien",
label = "Parteien",
inline = TRUE,
choices = c("AfD", "SPD", "FDP", "DieGrüne", "DieLinke",
"Tierschutzpartei", "CDU", "MLPD", "NPD")),
actionButton(inputId = "Update", label = "Diagramm erzeugen")
)
server <- function(input, output, session) {
}
shinyApp(ui, server)Nun kann man das vorläufige User Interface der App betrachten. Am Anfang der Seite ist die Navigationsleiste zu sehen. Darunter ist ein großer leerer Bereich für die Inhalte der Unterseiten, da diese ja bisher noch nicht erstellt wurden. Am Ende der Seite sind die drei Inputs für Titel, Zeitraum und die Parteien zu sehen und der Action Button mit der Aufschrift “Diagramm erzeugen”.
Natürlich kann man an der App in ihrem aktuellen Status allem voran die Formatierung bemängeln. Die App enthält keine Farben, es gibt keinen Titel, die Input-Fenster sind nicht an die Größe der Seite angepasst und alle Bestandteile stehen einfach nur untereinander. Die Problemstellung schreibt diese optischen Veränderungen zwar nicht vor; doch sie machen die App deutlich ansehnlicher. Im Folgenden wird dir eine mögliche Formatierung des User Interfaces der App vorgestellt.
ui <- fluidPage(
style = "background: #337ab7; color: white;", # Format der Gesamtseite: Hintergrundfarbe mit dem tag #337ab7 und Schriftfarbe weiß
tags$head(tags$style(".navbar {background-color: #eded00;}", # Navigationsleiste: Hintergrundfarbe mit dem tag #eded00
".navbar-default .navbar-brand {color: black; background-color: #ffaa00}")), # Navigationsleistentitel mit der Schriftfarbe schwarz und der Hintergrundfarbe #ffaa00
titlePanel( # hier wird ein Titelfeld ganz oben eingefügt
title = h1(strong("Suchanfragen deutscher Parteien"), align = "center"), # Überschrift der Formatierung h1 in fett (->strong) und zentriert (align = "center")
windowTitle = "Suchanfragen deutscher Parteien"), # Titel, der im Tab angezeigt wird
wellPanel( # erstellt ein Element, das die darin liegenden Objekte gruppiert
style = "background: #87CEFA; border-color: #2e6da4", # Format dieses Elements
navbarPage(strong("Darstellungsart"),
tabPanel("Liniendiagramm",
plotOutput("Liniendiagramm")),
tabPanel("Liniendiagramm (kumuliert)",
plotOutput("Liniendiagramm_kumuliert")),
tabPanel("Balkendiagramm (kumuliert)",
plotOutput("Balkendiagramm")),
tabPanel("Kuchendiagramm (kumuliert)",
plotOutput("Kuchendiagramm"))
),
br(), # fügt einen break ein -> entspicht einer Leerzeile im Text
fluidRow( # erstellt eine Reihe, die sich an die Fensterbreite anpasst ("fluid")
column(6, # spezifiziert, wo dieser Input stehen soll: belegt die ersten 6 Spalten (eine Zeile besteht aus 12 Spalten = nimmt also die Hälfte der Seite ein)
dateRangeInput(inputId = "Datum",
label = "Zeitspanne",
start = "2000-01-01",
format = "yyyy-mm-dd")),
column(6, # besetzt die 6 Spalten auf der rechten Seite; also die rechte Hälfte des Fensters
textInput(inputId = "Titel",
label = "Titel der Grafik"))),
fluidRow(
column(9, checkboxGroupInput(
inputId = "Parteien",
label = "Parteien",
inline = TRUE,
choices = c("AfD", "SPD", "FDP", "DieGrüne", "DieLinke",
"Tierschutzpartei", "CDU", "MLPD", "NPD"))),
column(3, br(), actionButton(
inputId = "Update",
label = strong("Diagramm erzeugen"), # Die Beschriftung des ActionButtons soll fett sein.
style = "color: #fff; background-color: #337ab7; border-color: #2e6da4")) # Der Button selbst soll die Schriftfarbe #fff haben, die Hintergrundfarbe #337ab7 und die Rahmenfabre #2e6da4.
)
)
)
server <- function(input, output, session) {
}
shinyApp(ui, server)Bedeutung von fluidRow & column
In der verschönerten Version des User Interfaces wurden die beiden Befehle fluidRow und column verwendet. Diese dienen dazu, die erstellten Objekte schöner anzuordnen.
Mit fluidRow erstellt man dabei eine Reihe, deren Besonderheit es ist, dass sie sich der Fenstergröße anpassen kann (deshalb “fluid”). Die Bedeutung davon wird klar, wenn man betracht, wie der column-Befehl funktioniert.
Mit column legt man dann nämlich fest, in welcher/n Spalte/n dieser Reihe ein bestimmtes Objekt liegen soll. Nutzt das Fenster der App die gesamte Bildschirmbreite, dann besteht die App aus 12 Spalten. Mit diesem Wissen kann man nun arbeiten, um bestimmten Objekten den benötigten Raum zu geben und Reihen beliebig aufzuteilen.
numericInputs, dann kann man mit der Spaltenaufteilung “6|6” beiden Inputs eine Hälfte (6 Spalten) des Bildschirms zuweisen. Belegt das Fenster der App jedoch nicht die gesamte Breite des Bildschirms, dann stehen der App weniger als 12 Spalten zur Verfügung. Das heißt, dass die beiden numericInputs nun nicht mehr vollständig in einer Reihe angezeigt werden können, da es sich bei der Spaltenzuweisung um eine absolute (nicht veränderbare/nicht “fluide”) Angabe handelt. Theoretisch müsste diese App nun zu groß für das Fenster sein, sodass man mit Schiebereglern agieren müsste. Doch an diesem Punkt greifen die Vorteile des fluidRow-Befehls, denn durch diesen werden die beiden Inputs nun untereinander dargestellt. Probiere das gerne einmal aus, indem du die Fenstergröße der App etwas verändert.Das Endergebnis ist bereits etwas hübscher und deutet an, was mit dem Design alles möglich ist. Falls du dich fragst, was es mit den Farbcodes auf sich hat und woher diese kommen: HTML (worauf shiny basiert) hat ein Farbsystem, das mit diesen 6-stelligen Codes arbeitet; diese sind im Internet relativ einfach auffindbar und verfolgen eine relativ einfache Logik. Für mehr Infos dazu schau dir einfach mal die Website html-color-codes.info an, wenn du dich für die Logik hinter der Farbkodierung interessierst und vielleicht deine eigene Farb-Kombination zusammenstellen willst. Eine weitere Möglichkeit ist die Website farbtabelle.at, die dir eine Farbtabelle mit über 4000 Farben und zugehörigen Farbcodes bereitstellt.
An diesem Punkt kannst du das User Interface als abgeschlossen betrachten. Nur die Outputs der verschiedenen Navigationstabs müssen noch in Abhängigkeit der Inputs (inklusive des Action Buttons) erstellt und eingefügt werden. Die Umsetzung dieser letzten Anforderung wird im letzten Teilabschnitt “Server” besprochen.
Lösung 4 - Server
Zunächst kann man alle Diagramme in diese Funktion übernehmen. Diese Diagramme muss man nun nur noch in eine reaktive Funktion packen (renderPlot) und dann durch einen Zuweisungspfeil spezifizieren, welchen Output das jeweilige Diagramm darstellt. Dabei sind die Bezeichnungen aus den tabPanels von besonderer Bedeutung, da diese hier für die Zuordnung von Diagramm zu tabPanel ausschlaggebend sind.
server <- function(input, output, session) {
# Liniendiagramm
output$Liniendiagramm <- renderPlot({
ggplot(data = p1_long, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) +
xlab('Zeitraum') +
ylab('Anfragen (in % des Monats-Maximums)') +
ggtitle('Suchanfragen deutscher Parteien') +
scale_color_manual(values = farben) +
theme_bw()
})
# Kumuliertes Liniendiagramm
output$Liniendiagramm_kumuliert <- renderPlot({
ggplot(data = p1_long, aes(x = nMonat, y = Prozent_kumuliert, group = Partei)) +
geom_line(aes(colour = Partei)) +
xlab('Zeitraum') +
ylab('Anfragen (in % des Monats-Maximums/kumuliert)') +
ggtitle('Suchanfragen deutscher Parteien') +
scale_color_manual(values = farben) +
theme_bw()
})
# Balkendiagramm
output$Balkendiagramm <- renderPlot({
p1_new <- data.frame(names(p1_wide[, 2:10]), colSums(p1_wide[, 2:10]))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
ggplot(p1_new, aes(x = Partei, y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_col(color = "black") +
theme_bw() +
xlab("Partei") +
ylab("kumulierte Suchhäufigkeiten") +
ggtitle('Suchanfragen deutscher Parteien')
})
# Kuchendiagramm
output$Kuchendiagramm <- renderPlot({
p1_new <- data.frame(names(p1_wide[, 2:10]), colSums(p1_wide[, 2:10]))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
p1_new <- p1_new[order(p1_new$Partei, decreasing = TRUE), ]
ggplot(p1_new, aes(x = "", y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
theme_void() +
ggtitle('Suchanfragen deutscher Parteien') +
theme(axis.ticks = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_text(colour = 'black'),
axis.title = element_blank()) +
scale_y_continuous(
breaks = cumsum(p1_new$Prozent_kumuliert) - p1_new$Prozent_kumuliert/2,
labels = p1_new$Partei)
})
}Das bildet nun die Grundstruktur für den Server. Jetzt geht es darum, die reaktiven
Inputs in die Diagramme zu integrieren. Fangen wir dafür bei der einfachsten Sache an: dem Titel. Der angegebene Titel wird in der Variable input$Titel gespeichert, da bei diesem Input inputId = "Titel" von uns festgelegt wurde. Diese Variable setzen wir nun einfach an die Stelle des Titels in den vier Diagrammen:
server <- function(input, output, session) {
# Liniendiagramm
output$Liniendiagramm <- renderPlot({
ggplot(data = p1_long, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) +
xlab('Zeitraum') +
ylab('Anfragen (in % des Monats-Maximums)') +
ggtitle(input$Titel) +
scale_color_manual(values = farben) +
theme_bw()
})
# Kumuliertes Liniendiagramm
output$Liniendiagramm_kumuliert <- renderPlot({
ggplot(data = p1_long, aes(x = nMonat, y = Prozent_kumuliert, group = Partei)) +
geom_line(aes(colour = Partei)) +
xlab('Zeitraum') +
ylab('Anfragen (in % des Monats-Maximums/kumuliert)') +
ggtitle(input$Titel) +
scale_color_manual(values = farben) +
theme_bw()
})
# Balkendiagramm
output$Balkendiagramm <- renderPlot({
p1_new <- data.frame(names(p1_wide[, 2:10]), colSums(p1_wide[, 2:10]))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
ggplot(p1_new, aes(x = Partei, y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_col(color = "black") +
theme_bw() +
xlab("Partei") +
ylab("kumulierte Suchhäufigkeiten") +
ggtitle(input$Titel)
})
# Kuchendiagramm
output$Kuchendiagramm <- renderPlot({
p1_new <- data.frame(names(p1_wide[, 2:10]), colSums(p1_wide[, 2:10]))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
p1_new <- p1_new[order(p1_new$Partei, decreasing = TRUE), ]
ggplot(p1_new, aes(x = "", y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
theme_void() +
ggtitle(input$Titel) +
theme(axis.ticks = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_text(colour = 'black'),
axis.title = element_blank()) +
scale_y_continuous(
breaks = cumsum(p1_new$Prozent_kumuliert) - p1_new$Prozent_kumuliert/2,
labels = p1_new$Partei)
})
}Im zweiten Schritt geht es darum, ein variables Zeitintervall miteinzubeziehen. Dafür muss man den Datensatz vor der Verwendung in den Diagrammen manipulieren. Diese Manipulation soll jedoch nicht bei jeder kleinsten Veränderung auftreten, sondern erst dann, wenn der Action Button betätigt wurde. Um das zu verwirklichen, werden die Funktionen reactiveValues und observeEvent benötigt. Mit reactiveValues erstellt man ein reaktives Objekt, in unserem Fall der Datensatz p1_long, der durch die Inputs verändert werden kann. Man schreibt also:
rv <- reactiveValues(data = p1_long). Der Datensatz ist nun ein reaktives Objekt, das über rv$data abrufbar ist, und außerdem stellt p1_long, also der gesamte Datensatz, den Ausgangsdatensatz für die Erstellung der Diagramme beim Öffnen der App dar. Jetzt benutzt man den Befehl observeEvent, um rv$data dann zu aktualisieren, wenn der Action Button betätigt wird. Wie lässt sich diese Aktualisierung jedoch bewerkstelligen? Die genaue Erklärung dazu erhältst du (wenn du möchtest) im folgenden kleinen Unterabschnitt.
Aktualisierung der betrachteten Zeitspanne
Das Problem von Daten ist, dass sie nicht den typischen Strukturen von Zahlen folgen. Zahlen stehen für sich, während Daten aus den drei Komponenten Tag, Monat und Jahr bestehen. Aus diesem Grund muss der Input aus den beiden Input-Feldern in ein Datums-Format (POSIXct) gebracht werden, um es mit den Daten aus der VariablenMonat vergleichen zu können. Glücklicherweise liegen die Daten in den Input-Feldern bereits im Format ‘JJJJ-MM-TT’ vor, sodass man einfach den Befehl as.POSIXct verwenden kann. Jetzt geht es darum, vom Datensatz p1_long nur jene Zeilen beizubehalten, deren Datum (nMonat) in der angegebenen Datumspanne der Input-Felder liegt. Daraus ergeben sich die zwei Bedingungen as.POSIXct(input$Datum[1]) < p1_long$nMonat und as.POSIXct(input$Datum[2]) > p1_long$nMonat für die Auswahl der Zeilen.Nun hat man die Veränderung näher bestimmt, die durch einen Knopfdruck ausgelöst werden soll. Jetzt gilt es noch, den Knopfdruck in die Funktion mit einzubeziehen. Wie bereits erwähnt, nutzt man dafür die observeEvent-Funktion. Diese Funktion reagiert auf Veränderungen des ersten Arguments. Hier ist der Inhalt des ersten Arguments input$Update, dessen Wert sich bei jedem Knopfdruck verändert (und zwar von 0 zu 1 und dann wieder zu 0 usw.). Das heißt, dass sich bei jedem Knopfdruck input$Update ändert, wodurch rv$data auf eine mögliche Veränderung von input$Datum reagieren soll. Das Ganze sieht dann folgendermaßen aus:
rv <- reactiveValues(data = p1_long)
observeEvent(input$Update, {
rv$data <- p1_long[as.POSIXct(input$Datum[1]) < p1_long$nMonat
& as.POSIXct(input$Datum[2]) > p1_long$nMonat,]}) # ACHTUNG: Nicht die geschweifte Klammer vergessen!Das Ganze muss dann auch noch für p1_wide umgesetzt werden, da auch dieser Datensatz in der Erstellung der Diagramme benötigt wird.
Wichtig: Danach befinden sich die relevanten Datensätze zur Erstellung der Diagramme in rv$data für die ersten beiden Diagramme und in rv2$data für die Diagramme drei und vier! Das muss also in den Befehlen der Diagramme auch noch verändert werden!
Der R-Code dazu sieht dann folgendermaßen aus:
server <- function(input, output, session) {
# Datenauswahl (Zeitplots)
rv <- reactiveValues(data = p1_long)
observeEvent(input$Update, {
rv$data <- p1_long[as.POSIXct(input$Datum[1]) < p1_long$nMonat
& as.POSIXct(input$Datum[2]) > p1_long$nMonat,]})
# Liniendiagramm
output$Liniendiagramm <- renderPlot({
ggplot(data = rv$data, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) +
xlab('Zeitraum') +
ylab('Anfragen (in % des Monats-Maximums)') +
ggtitle(input$Titel) +
scale_color_manual(values = farben) +
theme_bw()
})
# Kumuliertes Liniendiagramm
output$Liniendiagramm_kumuliert <- renderPlot({
ggplot(data = rv$data, aes(x = nMonat, y = Prozent_kumuliert, group = Partei)) +
geom_line(aes(colour = Partei)) +
xlab('Zeitraum') +
ylab('Anfragen (in % des Monats-Maximums/kumuliert)') +
ggtitle(input$Titel) +
scale_color_manual(values = farben) +
theme_bw()
})
# Datenauswahl (Gesamtplots)
rv2 <- reactiveValues(data = p1_wide[, 2:10]) # nur Spalte 2-10, da die Spalten 1 und 11 das Datum enthalten und keine Prozentangaben
observeEvent(input$Update, {
rv2$data <- p1_wide[as.POSIXct(input$Datum[1]) < p1_wide$nMonat
& as.POSIXct(input$Datum[2]) > p1_wide$nMonat,]})
# Balkendiagramm
output$Balkendiagramm <- renderPlot({
p1_new <- data.frame(names(rv2$data), colSums(rv2$data))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
ggplot(p1_new, aes(x = Partei, y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_col(color = "black") +
theme_bw() +
xlab("Partei") +
ylab("kumulierte Suchhäufigkeiten") +
ggtitle(input$Titel)
})
# Kuchendiagramm
output$Kuchendiagramm <- renderPlot({
p1_new <- data.frame(names(rv2$data), colSums(rv2$data))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
p1_new <- p1_new[order(p1_new$Partei, decreasing = TRUE), ]
ggplot(p1_new, aes(x = "", y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
theme_void() +
ggtitle(input$Titel) +
theme(axis.ticks = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_text(colour = 'black'),
axis.title = element_blank()) +
scale_y_continuous(
breaks = cumsum(p1_new$Prozent_kumuliert) - p1_new$Prozent_kumuliert/2,
labels = p1_new$Partei)
})
}Führt man den Server nun aus und schaut sich die vorläufige App an, stößt man nach dem Ausprobieren der bisher implizierten Funktionen auf eine Problematik: Das kumulierte Liniendiagramm reagiert nicht korrekt auf die Begrenzungen der Zeitspanne. Anstatt dass sich immer wieder ein neuer Plot bildet, bei dem die einzelnen Linien immer bei Null beginnen, wird bei einer Begrenzung der Zeitspanne lediglich der ausgewählte Abschnitt des Ausgangsplots abgebildet. Aus diesem Grund sollten die kumulierten Werte bei jeder Veränderung von rv$data erneut berechnet werden.
output$Liniendiagramm_kumuliert <- renderPlot({
# Aktualisierung der kumulierten Prozente immer dann, wenn sich rv$data verändert:
rv$data$Prozent_kumuliert <- unlist(tapply(rv$data$Prozent, rv$data$Partei, cumsum))
ggplot(data = rv$data, aes(x = nMonat, y = Prozent_kumuliert, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Monats-Maximums/kumuliert)') + # Beschriftung y-Achse
ggtitle(input$Titel) + # Überschrift
scale_color_manual(values = farben) +
theme_bw()
})Im letzten Schritt muss man noch die Auswahl der Parteien mit in die Erstellung der Diagramme einbeziehen. Auch hier setzt man vor der Erstellung der Diagramme an den Datensätzen selbst an. Der Input aus der checkbockGroupInput-Funktion kommt in input$Partei als einfacher Text an. Ist zum Beispiel CDU angekreuzt, befindet sich im Objekt input$Partei ein Objekt CDU. Aufgrunddessen lässt sich eine Bedingung mit dem is.element-Befehl erstellen, der jene Reaktivität der Diagramme umsetzt.
Im Datensatz p1_long findet man eine Variable Partei, in der die jeweilige Partei angegeben ist. Hier muss man also einfach jene Zeilen des Datensatzes auswählen, in denen die Partei aus der Variable Partei ein Objekt von input$Partei ist.
Für den Datensatz p1_wide findet sich keine solche Variable. Hier hat jede Partei eine eigene Spalte, weshalb die Partei-Bedingung hier die relevanten Spalten auswählt.
Im R-Code umgesetzt sieht das dann folgendermaßen aus und bildet mitunter das Endprodukt des Servers:
server <- function(input, output, session) {
# Datenauswahl (Zeitplots)
rv <- reactiveValues(data = p1_long)
observeEvent(input$Update, {
rv$data <- p1_long[is.element(p1_long$Partei, input$Parteien)
& as.POSIXct(input$Datum[1]) < p1_long$nMonat
& as.POSIXct(input$Datum[2]) > p1_long$nMonat,]})
# Liniendiagramm
output$Liniendiagramm <- renderPlot({
ggplot(data = rv$data, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Monats-Maximums)') + # Beschriftung y-Achse
ggtitle(input$Titel) + # Überschrift
scale_color_manual(values = farben) +
theme_bw()
})
# Kumuliertes Liniendiagramm
output$Liniendiagramm_kumuliert <- renderPlot({
rv$data$Prozent_kumuliert <- unlist(tapply(rv$data$Prozent, rv$data$Partei, cumsum))
ggplot(data = rv$data, aes(x = nMonat, y = Prozent_kumuliert, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Monats-Maximums/kumuliert)') + # Beschriftung y-Achse
ggtitle(input$Titel) + # Überschrift
scale_color_manual(values = farben) +
theme_bw()
})
# Datenauswahl (Gesamtplots)
rv2 <- reactiveValues(data = p1_wide[,2:10])
observeEvent(input$Update, {
rv2$data <- p1_wide[as.POSIXct(input$Datum[1]) < p1_wide$nMonat
& as.POSIXct(input$Datum[2]) > p1_wide$nMonat,
input$Parteien]})
# Balkendiagramm
output$Balkendiagramm <- renderPlot({
p1_new <- data.frame(names(rv2$data), colSums(rv2$data))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
ggplot(p1_new, aes(x = Partei, y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_col(color = "black") +
theme_bw() +
xlab("Partei") +
ylab("kumulierte Suchhäufigkeiten") +
ggtitle(input$Titel)
})
# Kuchendiagramm
output$Kuchendiagramm <- renderPlot({
p1_new <- data.frame(names(rv2$data), colSums(rv2$data))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
p1_new <- p1_new[order(p1_new$Partei, decreasing = TRUE), ]
ggplot(p1_new, aes(x = "", y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
theme_void() +
ggtitle(input$Titel) +
theme(axis.ticks = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_text(colour = 'black'),
axis.title = element_blank()) +
scale_y_continuous(
breaks = cumsum(p1_new$Prozent_kumuliert) - p1_new$Prozent_kumuliert/2,
labels = p1_new$Partei)
})
}Zusatz: Formelle Fertigstellung
Wie bereits in den Tipps erwähnt, sollte man eine App ohne vorhergehenden Code ausführen können. Dafür bedarf es der Aufnahme der Vorbereitungen in die server-Funktion. Zusammengenommen beläuft sich das auf die folgenden Code-Zeilen (inklusive des Ladens weiterer Pakete):
# Paket laden
library(ggplot2)
# Daten einlesen
p1_long <- readRDS("p1_long.rds")
p1_wide <- readRDS("p1_wide.rds")
# Monate formatieren
p1_long$nMonat <- as.character(p1_long$Monat)
p1_long$nMonat <- paste0(p1_long$nMonat, '-01')
p1_long$nMonat <- strptime(p1_long$nMonat, format="%Y-%m-%d")
p1_long$nMonat <- as.POSIXct(p1_long$nMonat)
p1_wide$nMonat <- as.character(p1_wide$Monat)
p1_wide$nMonat <- paste0(p1_wide$nMonat, '-01')
p1_wide$nMonat <- strptime(p1_wide$nMonat, format="%Y-%m-%d")
p1_wide$nMonat <- as.POSIXct(p1_wide$nMonat)
# Farbkodierung der Parteien
farben <- c('AfD' = 'deepskyblue', 'CDU' = 'black', 'DieGrüne' = 'green3',
'DieLinke' = 'magenta', 'FDP' = 'gold', 'MLPD' = 'orange',
'NPD' = 'brown', 'SPD' = 'red', 'Tierschutzpartei' = 'darkblue')
# Kumulierte Suchanfragen
p1_long <- p1_long[order(p1_long$Partei), ]
p1_long$Prozent_kumuliert <- unlist(tapply(p1_long$Prozent, p1_long$Partei, cumsum))Das gesamte Dokument aus User Interface und Server sieht dann abschließend folgendermaßen aus:
library(shiny)
ui <- fluidPage(
theme = "bootstrap.css", style = "background: #337ab7; color: white",
tags$head(tags$style(".navbar {background-color: #eded00;}",
".navbar-default .navbar-brand {color: black;}")),
titlePanel(
h1(strong("Suchanfragen deutscher Parteien"), align = "center"),
windowTitle = "Suchanfragen deutscher Parteien"),
wellPanel(style = "background: #87CEFA; border-color: #2e6da4",
navbarPage(
strong("Darstellungsart"),
tabPanel("Liniendiagramm", plotOutput("Liniendiagramm")),
tabPanel("Liniendiagramm (kumuliert)", plotOutput("Liniendiagramm_kumuliert")),
tabPanel("Balkendiagramm (kumuliert)", plotOutput("Balkendiagramm")),
tabPanel("Kuchendiagramm (kumuliert)", plotOutput("Kuchendiagramm"))
),
br(),
fluidRow(
column(6,
dateRangeInput(
inputId = "Datum", label = "Zeitspanne",
start = "2000-01-01", format = "yyyy-mm-dd")),
column(6, textInput(
inputId = "Titel", label = "Titel der Grafik"))
),
fluidRow(
column(9, checkboxGroupInput(
inputId = "Parteien", label = "Parteien", inline = TRUE,
choices = c("AfD", "SPD", "FDP", "DieGrüne", "DieLinke",
"Tierschutzpartei", "CDU", "MLPD", "NPD"))),
column(3, br(), actionButton(
inputId = "Update", label = strong("Diagramm erzeugen"),
style = "color: #fff; background-color: #337ab7; border-color: #2e6da4"))
)
)
)
server <- function(input, output, session) {
# Paket laden
library(ggplot2)
# Daten einlesen
p1_long <- readRDS('p1_long.rds')
p1_wide <- readRDS('p1_wide.rds')
# Monate formatieren
p1_long$nMonat <- as.character(p1_long$Monat)
p1_long$nMonat <- paste0(p1_long$nMonat, '-01')
p1_long$nMonat <- strptime(p1_long$nMonat, format="%Y-%m-%d")
p1_long$nMonat <- as.POSIXct(p1_long$nMonat)
p1_wide$nMonat <- as.character(p1_wide$Monat)
p1_wide$nMonat <- paste0(p1_wide$nMonat, '-01')
p1_wide$nMonat <- strptime(p1_wide$nMonat, format="%Y-%m-%d")
p1_wide$nMonat <- as.POSIXct(p1_wide$nMonat)
# Farbkodierung der Parteien
farben <- c('AfD' = 'deepskyblue', 'CDU' = 'black', 'DieGrüne' = 'green3',
'DieLinke' = 'magenta', 'FDP' = 'gold', 'MLPD' = 'orange',
'NPD' = 'brown', 'SPD' = 'red', 'Tierschutzpartei' = 'darkblue')
# Kumulative Suchanfragen
p1_long <- p1_long[order(p1_long$Partei), ]
p1_long$Prozent_kumuliert <- unlist(tapply(p1_long$Prozent, p1_long$Partei, cumsum))
# Datenauswahl (Zeitplots)
rv <- reactiveValues(data = p1_long)
observeEvent(input$Update, {
rv$data <- p1_long[is.element(p1_long$Partei, input$Parteien)
& as.POSIXct(input$Datum[1]) < p1_long$nMonat
& as.POSIXct(input$Datum[2]) > p1_long$nMonat,]})
# Liniendiagramm
output$Liniendiagramm <- renderPlot({
ggplot(data = rv$data, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Monats-Maximums)') + # Beschriftung y-Achse
ggtitle(input$Titel) + # Überschrift
scale_color_manual(values = farben) +
theme_bw()
})
# Kumuliertes Liniendiagramm
output$Liniendiagramm_kumuliert <- renderPlot({
rv$data$Prozent_kumuliert <- unlist(tapply(rv$data$Prozent, rv$data$Partei, cumsum))
ggplot(data = rv$data, aes(x = nMonat, y = Prozent_kumuliert, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Monats-Maximums/kumuliert)') + # Beschriftung y-Achse
ggtitle(input$Titel) + # Überschrift
scale_color_manual(values = farben) +
theme_bw()
})
# Datenauswahl (Gesamtplots)
rv2 <- reactiveValues(data = p1_wide[,2:10])
observeEvent(input$Update, {
rv2$data <- p1_wide[as.POSIXct(input$Datum[1]) < p1_wide$nMonat
& as.POSIXct(input$Datum[2]) > p1_wide$nMonat,
input$Parteien]})
# Balkendiagramm
output$Balkendiagramm <- renderPlot({
p1_new <- data.frame(names(rv2$data), colSums(rv2$data))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
ggplot(p1_new, aes(x = Partei, y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_col(color = "black") +
theme_bw() +
xlab("Partei") +
ylab("kumulierte Suchhäufigkeiten") +
ggtitle(input$Titel)
})
# Kuchendiagramm
output$Kuchendiagramm <- renderPlot({
p1_new <- data.frame(names(rv2$data), colSums(rv2$data))
names(p1_new)[1]<-paste("Partei")
names(p1_new)[2]<-paste("Prozent_kumuliert")
p1_new <- p1_new[order(p1_new$Partei, decreasing = TRUE), ]
ggplot(p1_new, aes(x = "", y = Prozent_kumuliert, fill = Partei)) +
scale_fill_manual(values = farben) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
theme_void() +
ggtitle(input$Titel) +
theme(axis.ticks = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_text(colour = 'black'),
axis.title = element_blank()) +
scale_y_continuous(
breaks = cumsum(p1_new$Prozent_kumuliert) - p1_new$Prozent_kumuliert/2,
labels = p1_new$Partei)
})
}
shinyApp(ui, server)Wenn man nun ui und server erstellt hat, kann man die vollständige App folgendermaßen abrufen:
shinyApp(ui, server)So könnte die App dann letztlich bei dir aussehen:
Es ergibt sich also eine App, die mehrere Diagrammen mit mehr oder weniger dem gleichen Datensatz erstellen kann. Diese Diagramme reagieren direkt auf Veränderungen des Titels im dazugehörigen Input-Fenster. Auf die ausgewählte Zeitspanne und die ausgewählten Parteien reagieren die Diagramme nicht direkt, sondern erst dann, wenn die Veränderungen durch das Drücken des “Diagramm erzeugen”-Buttons auf die Diagramme angewendet werden. Da sich die App hier nun wieder an die Breite des Textfensters angepasst hat, kannst du dir die App hier nochmals in voller Breite (und damit in der Basis-Formatierung) anschauen.
Lösungen zu Teil 2: Sudokus lösen
Hier sind die Lösungen zum zweiten Abschnitt des Projekts “Sudokus lösen”. Wie bereits erwähnt, handelt es sich hier nur um eine Möglichkeit, die angesprochenen Ziele umzusetzen. Die Lösungen sind also vor allem als Vorschlag zu betrachten; andere Wege sind logischerweise auch denkbar, möglicherweise sogar besser. Damit die Lösung für dich etwas übersichtlicher ist, ist der gesamte Prozess in drei Abschnitte aufgeteilt, die du bereits aus den Tipps kennen solltest.
Teil 1 - Vorbereitungen/Sudoku-Ausgabe
Bevor du mit diesem Projekt anfangen kannst, brauchst du ungelöste Sudokus als .rds-Dateien. Sofern du Projekt 5 noch nicht bearbeitet hast und du dir keine eigenen Sudokus erstellen kannst, kannst du dir hier und hier zwei Sudokus herunterladen. Diese kannst du im Folgenden in die aktuelle R-Sitzung laden und zum Ausprobieren der vorgeschlagenen App verwenden.
BeispielSudoku <- readRDS("BeispielSudokuLeicht.rds")Jetzt kannst du die Darstellung des Sudokus aus Projekt 5 übernehmen. Dafür wurde unter anderem das Paket plot.matrix verwendet, das nun wiederum geladen werden muss:
#install.packages("plot.matrix") <- nur ausführen, wenn du dieses Paket noch nie benutzt hast
library(plot.matrix)Am Beispiel von dem geladenen Sudoku können wir uns nun anschauen, wie die Abbildung am Ende von Projekt 5 aussah:
par(yaxt = "n", xaxt = "n", mar = c(0, 0, 4, 0))
plot(BeispielSudoku,
main = "Sudoku", xlab = "", ylab = "",
breaks = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10),
col = c("yellow" , "orange", "red", "violet", "lightblue",
"cornflowerblue", "lightgreen", "chartreuse3", "lightsalmon4"),
border = F, text.cell = list(cex = 1), fmt.cell='%.0f',
na.print = '', na.col = "white",
xlim = c(0.5, 9.5), ylim = c(0.5, 9.5))
abline(h = 0.5, lwd = 5)
abline(h = 1.5, lwd = 0.5)
abline(h = 2.5, lwd = 0.5)
abline(h = 3.5, lwd = 2)
abline(h = 4.5, lwd = 0.5)
abline(h = 5.5, lwd = 0.5)
abline(h = 6.5, lwd = 2)
abline(h = 7.5, lwd = 0.5)
abline(h = 8.5, lwd = 0.5)
abline(h = 9.5, lwd = 5)
abline(v = 0.5, lwd = 5)
abline(v = 1.5, lwd = 0.5)
abline(v = 2.5, lwd = 0.5)
abline(v = 3.5, lwd = 2)
abline(v = 4.5, lwd = 0.5)
abline(v = 5.5, lwd = 0.5)
abline(v = 6.5, lwd = 2)
abline(v = 7.5, lwd = 0.5)
abline(v = 8.5, lwd = 0.5)
abline(v = 9.5, lwd = 5)
Für die App muss diese Abbildung noch etwas angepasst werden. Zum Einen wurden in der ursprünglichen Abbildung die Achsenbeschriftungen durch den par-Befehl entfernt. Da wir diese im Folgenden jedoch benötigen, muss das gelöscht werden. Hier haben wir uns jedoch dazu entschieden, den par-Befehl beizubehalten, um beispielsweise die Schriftgröße der Achsenbeschriftung durch cex.axis und dessen Schriftfarbe durch col.axis anzupassen.
par(cex.axis = 1.5, col.axis = 'darkblue')Die Abbildung sieht nun folgendermaßen aus:
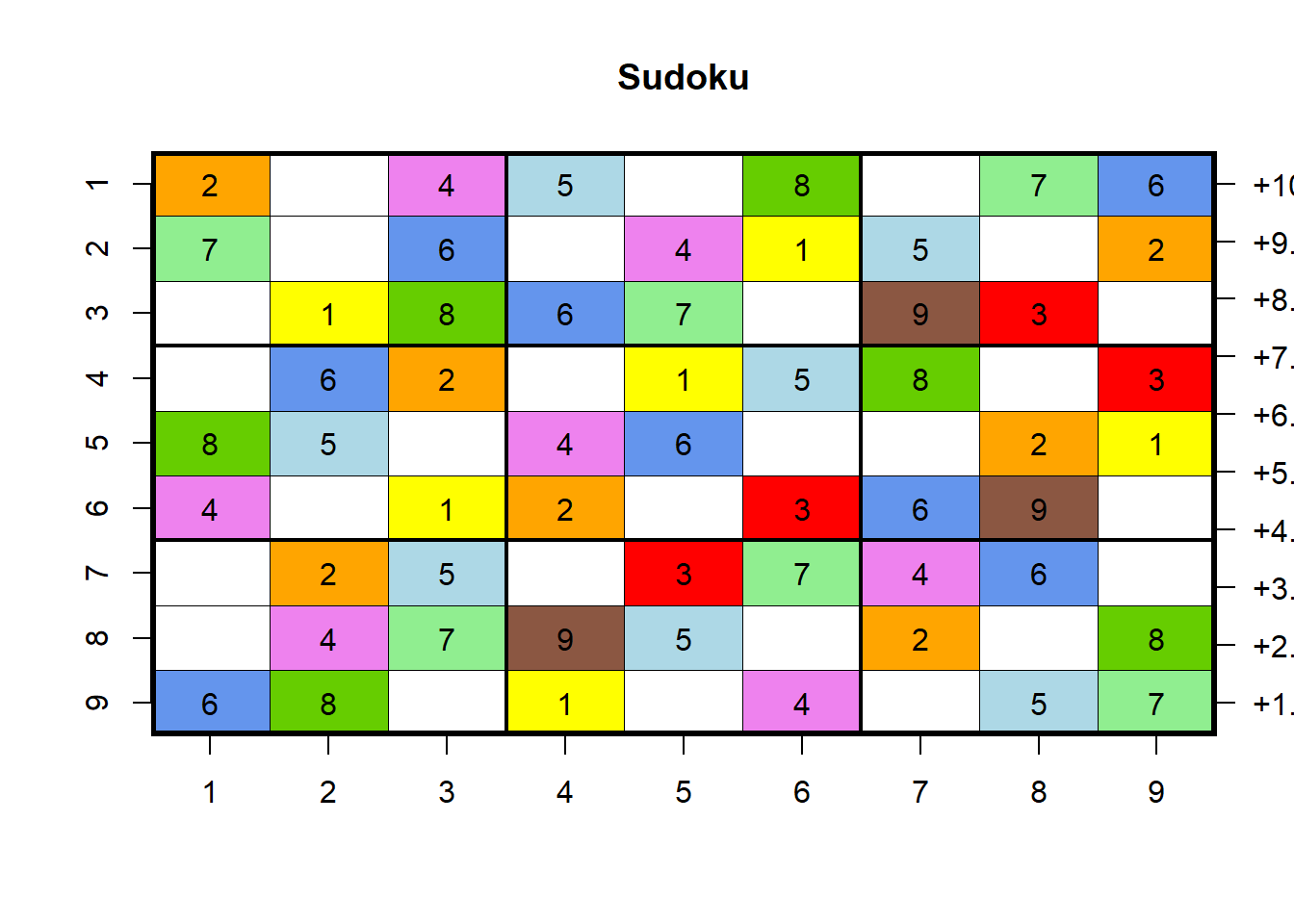
Außerdem braucht man in der Abbildung keinen Titel (main-Argument entfernen), die Beschriftung an der rechten Seite muss entfernt werden (key = NULL hinzufügen) und die Schriftgröße der Zahlen im Sudoku kann vergrößert werden (z.B. text.cell = list(cex = 2). In Folge dessen kann man die Abstände des Sudokus zum Rand der Abbildung mit dem mar-Argument in der par-Funktion anpassen. Die angepasste Abbildung des Sudokus sieht dann letztlich folgendermaßen aus:
par(cex.axis = 1.5, col.axis = 'darkblue', mar = c(4,4,0,2))
plot(BeispielSudoku,
xlab = "", ylab = "",
breaks = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10),
col = c("yellow" , "orange", "red", "violet", "lightblue",
"cornflowerblue", "lightgreen", "chartreuse3", "lightsalmon4"),
border = F, text.cell = list(cex = 2), fmt.cell='%.0f',
na.print = '', na.col = "white", key = NULL,
xlim = c(0.5, 9.5), ylim = c(0.5, 9.5))
abline(h = 0.5, lwd = 5)
abline(h = 1.5, lwd = 0.5)
abline(h = 2.5, lwd = 0.5)
abline(h = 3.5, lwd = 2)
abline(h = 4.5, lwd = 0.5)
abline(h = 5.5, lwd = 0.5)
abline(h = 6.5, lwd = 2)
abline(h = 7.5, lwd = 0.5)
abline(h = 8.5, lwd = 0.5)
abline(h = 9.5, lwd = 5)
abline(v = 0.5, lwd = 5)
abline(v = 1.5, lwd = 0.5)
abline(v = 2.5, lwd = 0.5)
abline(v = 3.5, lwd = 2)
abline(v = 4.5, lwd = 0.5)
abline(v = 5.5, lwd = 0.5)
abline(v = 6.5, lwd = 2)
abline(v = 7.5, lwd = 0.5)
abline(v = 8.5, lwd = 0.5)
abline(v = 9.5, lwd = 5)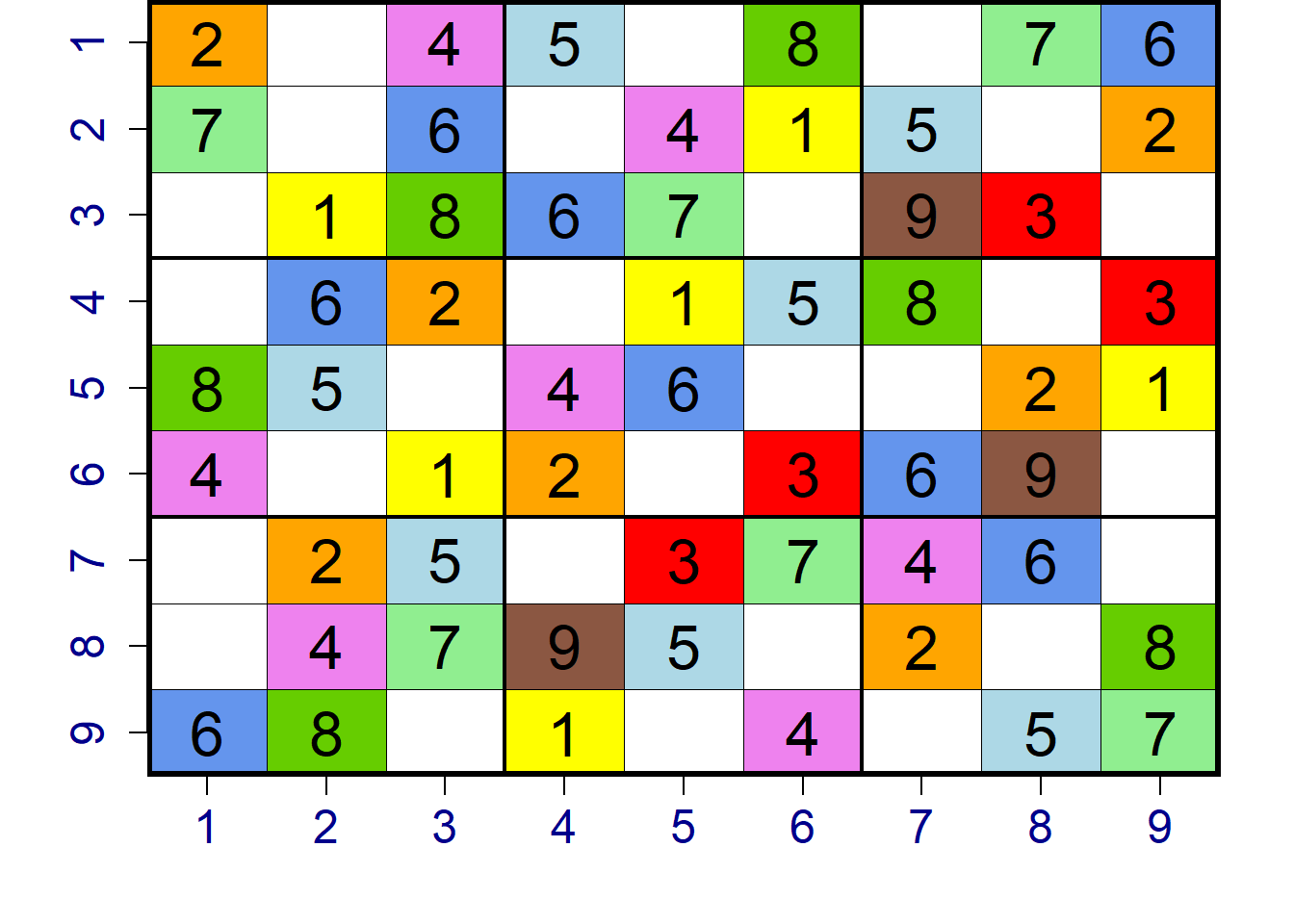
Teil 2 - User Interface
An diesem Punkt beginnen wir, mit dem shiny-Paket zu arbeiten. Aus diesem Grund sollte dieses spätestens jetzt heruntergeladen werden und dann in die aktuelle Sitzung geladen werden.
#install.packages("shiny") -> nur notwendig, sofern du das Paket nicht bereits heruntergeladen hast
library(shiny)Wie bereits in der Problemstellung erwähnt, kann man für die Umsetzung einer App zum Lösen von Sudokus eine pageWithSidebar verwenden. Dabei setzt man alle Inputs in die sogenannte “Sidebar” und das Sudoku setzt man in das mainPanel - so im Groben die Idee zur Umsetzung im User Interface. Zunächst sollten jedoch die einzelnen Inputs betrachtet werden, die zur Umsetzung der Anforderungen aus der Problemstellung benötigt werden. Hier nochmal die Übersicht:
- Die App sollte ein “Default-Sudoku” beinhalten, das beim Öffnen der App angezeigt wird.
- Das Sudoku sollte mithilfe von Inputs vollständig befüllbar sein.
- Es sollten nur jene Zahlen veränderbar sein, die nicht zuvor durch das Sudoku gegeben waren.
- Alle durch die Anwender:innen eingesetzten Zahlen sollten ständig veränderbar sein.
- Man sollte sein eigenes Sudoku in die App laden können (im .rds-Format) und es dort lösen können. Die Punkte 1-4 sollten also derart umgesetzt werden, dass sie für jedes geladene Sudoku Gültigkeit besitzen.
Die Punkte 1, 3 und 4 beziehen sich auf Inhalte, die nicht im User Interface bewerkstelltigt werden können (sondern im Server). Für diesen Abschnitt bleiben also nur die Punkte 2 und 5, die eingearbeitet werden müssen.
2.) Das Einsetzen von Zahlen ist auf dem Papier eine leichte Aufgabe: Die gefundenen Zahlen werden einfach in die leeren Kästchen geschrieben. Doch hier gestaltet sich dieser Prozess etwas komplizierter. Der Sudoku-Abbildung liegt eine 9x9-Matrix zugrunde, die an bestimmten Stellen mit Zahlen gefüllt ist. Damit man Zahlen einsetzen kann, muss eben diese 9x9-Matrix verändert werden. Dafür wird jedoch nicht nur die Information benötigt, welche Zahl eingesetzt werden soll, sondern auch eine Koordinate aus Zeile und Spalte, die besagt, wo diese Zahl eingesetzt werden soll. Aus diesem Grund braucht es in diesem Fall drei Zahlen-Inputs, die jeweils mit Werten von 1 bis 9 befüllt werden können. Dafür hält shiny die Funktion numericInput mit den Argumenten inputId, label, value, min und max bereit.
inputIdspeichert die Bezeichnung für diesen Input, mit der im Server gearbeitet werden kann (im Server verwendbar als Variable mitinput$inputId).labelgibt an, welche Benennung das Input-Fenster für die Anwender:innen der App haben soll.valuestellt den Ausgangswert dar, der beim Start der App ausgewählt ist.minundmaxermöglichen es, den Wertebereich einzugrenzen, der durch das Input-Fenster angenommen wird.
Für diesen Fall könnten die drei Inputs folgendermaßen aussehen:
numericInput(inputId = "row",
label = "Reihe",
value = '', min = 1, max = 9)
numericInput(inputId = "column",
label = "Spalte",
value = '', min = 1, max = 9)
numericInput(inputId = "num",
label = "Zahl",
value = '', min = 1, max = 9)Damit die Abbildung nicht auf jede Veränderung in einem dieser drei Inputs reagiert, macht hier ein actionButton Sinn, mit dem man im Server die Reaktivität der Abbildung auf diese drei Inputs steuern kann. Das ist deshalb von großer Wichtigkeit, da die Funktion erst dann eine Zahl einsetzen soll, wenn alle DREI Inputs angegeben wurden. Der actionButton benötigt in diesem Fall nur die beiden Argumente inputId und label (siehe oben).
actionButton(inputId = "go",
label = "Zahl einsetzen")5.) Neben dem Einsetzen von Zahlen soll außerdem die Möglichkeit bestehen, ein eigenes Sudoku im .rds-Format hochzuladen. Dafür hält shiny die Funktion fileInput bereit. Diese Funktion beinhaltet neben den bereits bekannten Argumenten inputId und label die Argumente accept, buttonLabel und placeholder.
acceptbegrenzt die durch das Input-Fenster akzeptierten Datei-Formate.buttonLabelermöglicht es, den Button zum Hochladen individuell zu benennen.placeholdernimmt einen Platzhalter-Text für das Input-Fenster entgegen, der dort angezeigt wird, wenn noch keine Datei geladen wurde.
fileInput(inputId = "Matrix",
label = "Füge hier dein eigenes Sudoku (als .rds) ein!",
accept = ".rds",
buttonLabel = "Datei hochladen",
placeholder = "Noch keine Datei hochgeladen.")Auch hier können wir zur Sicherheit einen actionButton einfügen, mit dem man dann später steuern kann, ob und wann die hochgeladene Datei in die Abbildung übernommen werden soll.
actionButton(inputId = "use",
label = "Sudoku benutzen")Alle diese Input-Fenster kann man nun in ein Skript zusammenfügen und zum Test einmal ausführen:
ui <- fluidPage(
fileInput(inputId = "Matrix",
label = "Füge hier dein eigenes Sudoku (als .rds) ein!",
accept = ".rds",
buttonLabel = "Datei hochladen",
placeholder = "Noch keine Datei hochgeladen."),
actionButton(inputId = "use",
label = "Sudoku benutzen"),
numericInput(inputId = "row",
label = "Reihe",
value = '', min = 1, max = 9),
numericInput(inputId = "column",
label = "Spalte",
value = '', min = 1, max = 9),
numericInput(inputId = "num",
label = "Zahl",
value = '', min = 1, max = 9),
actionButton(inputId = "go",
label = "Zahl einsetzen")
)
server <- function(input, output, session) {
}
shinyApp(ui, server)Die erforderten Inputs sind nun zwar alle vorhanden, doch die App sieht rein optisch gesehen nicht sehr ansprechend aus. Zuerst setzen wir das Ganze in das allgemeine Layout pageWithSidebar: mit allen Inputs im Seitenfenster, dem Output “Sudokus” (der im Server erstellt wird) im Hauptfenster und einem Titel (titlePanel):
ui <- pageWithSidebar(
titlePanel(
h1(strong(em("Hier kann man Sudokus lösen!")))),
sidebarPanel(
fileInput(inputId = "Matrix",
label = "Füge hier dein eigenes Sudoku (als .rds) ein!",
accept = ".rds",
buttonLabel = "Datei hochladen",
placeholder = "Noch keine Datei hochgeladen."),
actionButton(inputId = "use",
label = "Sudoku benutzen"),
numericInput(inputId = "row",
label = "Reihe",
value = '', min = 1, max = 9),
numericInput(inputId = "column",
label = "Spalte",
value = '', min = 1, max = 9),
numericInput(inputId = "num",
label = "Zahl",
value = '', min = 1, max = 9),
actionButton(inputId = "go",
label = "Zahl einsetzen")),
mainPanel(
plotOutput("Sudokus"))
)Wichtig: Damit das User Interface funktioniert, braucht man einen Titel, den man entweder mit den Standardbefehlen h1, h2, h3, … oder einem titlePanel erstellen kann. Dazu lässt sich jeglich Formatierung der Schrift kombinieren (z.B. strong() = fett, em() = kursiv, etc.).
Zu diesem Zeitpunkt hat man bereits eine angemessene Struktur in die einzelnen Elemente gebracht, doch es lassen sich noch einige weitere Verbesserungen vornehmen.
ui <- pageWithSidebar(
titlePanel(
h1(strong(em("Hier kann man Sudokus lösen!")),
align = "center", #der Titel wird zentriert ("center")
style = 'background: aqua'), #der Hintergrund des Titels bekommt die Farbe "aqua"
windowTitle = "Sudokus lösen!"), #das Fenster (im Browser) bekommt den Titel "Sudokus lösen!"
sidebarPanel(
h3("Willst du dein eigenes Sudoku lösen? Lade dein Sudoku einfach hier hoch!"), #Unterüberschrift für das Hochladen der Datei
br(), #Leerzeile
fileInput(inputId = "Matrix",
label = "Füge hier dein eigenes Sudoku (als .rds) ein!",
accept = ".rds",
buttonLabel = "Datei hochladen",
placeholder = "Noch keine Datei hochgeladen."),
actionButton(inputId = "use",
label = "Sudoku benutzen"),
h3("Wo willst du eine Zahl einsetzen?"), #Unterüberschrift für das Einsetzen der Zahlen
numericInput(inputId = "row",
label = "Reihe",
value = '', min = 1, max = 9),
numericInput(inputId = "column",
label = "Spalte",
value = '', min = 1, max = 9),
numericInput(inputId = "num",
label = "Zahl",
value = '', min = 1, max = 9),
actionButton(inputId = "go",
label = "Zahl einsetzen")),
mainPanel(
wellPanel(plotOutput("Sudokus", width = "640px", height = "600px"), align = "center") # Output wird in ein "Panel" gesetzt. Darin hat der Output eine vorgegebene Höhe und Breite und wird zentriert.
)
)
shinyApp(ui, server)Damit kann man das User Interface als fertig betrachten. Natürlich ist es möglich die Hintergrundfarbe, die Schriftfarbe, die Schriftart, die Schriftgröße, die Rahmenfarbe, die Rahmenart, und vieles mehr individuell für jedes einzelne Element zu bestimmen, doch so weit wollen wir hier nicht unbedingt gehen. Zum Einen ginge das möglicherweise zu weit und hätte mehr mit CSS als mit shiny zu tun und zum Anderen beinhaltet die Sudoku-Abbildung bereits einige Farben, weshalb ein farbenfrohes User Interface möglicherweise kontraproduktiv wäre. Letztlich ist das Ganze dir selbst überlassen und du kannst jede Formatierung vornehmen, die du möchtest. Falls du daran größeres Interesse haben solltest, kannst du dir auch einfach eine kleine Einführung zu CSS anschauen.
Teil 3 - Server
Mit ausgearbeitetem User Interface und erstellter Sudoku-Abbildung gilt es nun nur noch, die geforderten Funktionen im Server technisch umzusetzen. Schauen wir uns dafür nochmals die Anforderungen aus der Problemstellung an:
- Die App sollte ein “Default-Sudoku” beinhalten, das beim Öffnen der App angezeigt wird.
- Das Sudoku sollte mithilfe von Inputs vollständig befüllbar sein.
- Es sollten nur jene Zahlen veränderbar sein, die nicht zuvor durch das Sudoku gegeben waren.
- Alle durch die Anwender:innen eingesetzten Zahlen sollten ständig veränderbar sein.
- Man sollte sein eigenes Sudoku in die App laden können (im .rds-Format) und es dort lösen können. Die Punkte 1-4 sollten also derart umgesetzt werden, dass sie für jedes geladene Sudoku Gültigkeit besitzen.
Diese können wir in zwei Schritte aufteilen:
1.) Damit man anhand der gegebenen Oberfläche ein Sudoku lösen kann, braucht man einen reaktiven Datensatz, der auf die Eingabe der Zahlen reagiert, diese an der entsprechenden Stelle einsetzt und aus dem dann eine neue/aktualisierte Abbildung erstellt wird. Damit man schon beim Öffnen ein Sudoku angezeigt bekommt, braucht man außerdem ein Sudoku, dass standardmäßig die Grundlage für den reaktiven Datensatz bildet. Im ersten Schritt sorgen wir also dafür, dass eben dieses “Default-Sudoku” besteht. Dafür wird das bereits geladene BeispielSudoku verwendet.
server <- function(input, output, session) {
BeispielSudoku <- readRDS('BeispielSudokuLeicht.rds') #Sudoku laden
rv <- reactiveValues(data = BeispielSudoku) #Sudoku als reaktiven Datensatz speichern
}Wenn jetzt eine Zahl eingesetzt wird - die Anwender:innen also den actionButton mit der Aufschrift “Zahl einsetzen” betätigt hat - dann soll im reaktiven Datensatz an der ausgewählten Koordinate aus Zeile und Spalte die besagte Zahl eingesetzt werden. Dieses Einsetzen soll jedoch an die Bedingung geknüpft sein, dass es sich um ein von Anfang an freies Feld handelt; ansonsten könnte man auch durch das Sudoku gegebene Zahlen verändern (was man logischerweise nicht möchte). Aus diesem Grund benutzt man hier das Objekt BeispielSudoku, das im gesamten Verlauf nicht verändert wird und damit den Ausgangszustand des Sudokus perfekt widerspiegelt.
server <- function(input, output, session) {
BeispielSudoku <- readRDS('BeispielSudokuLeicht.rds') #Sudoku laden
rv <- reactiveValues(data = BeispielSudoku) #Sudoku als reaktiven Datensatz speichern
observeEvent(input$go, { #Wenn der Action Button betätigt wird, soll das in der geschweiften Klammer geschehen.
if(is.na(BeispielSudoku[input$row, input$column])){ #Wenn das ausgewählte Feld im Ausgangssudoku ein leeres Feld war, dann...
rv$data[input$row, input$column] <- input$num #... soll an dieser Stelle input$num eingesetzt werden
}
})
}Funktionsweise des Action-Buttons
Der Action-Button spielt in diesem Teil der Funktion in Verbindung mit der observeEvent-Funktion eine wichtige Rolle. Aus diesem Grund gibt es hier ein paar Details zu dessen Funktionsweise.
Der Action-Button funktioniert wie eine typische Input-Funktion und lässt sich durch einfaches Klicken betätigen. Doch was passiert mit einem Klick im Hintergrund? Das wird deutlich, wenn man sich anschaut, welche Ausgabe in der Input-Variable ankommt. Hier kann man sich vorstellen, dass der Button zwei Stadien einnehmen kann: Stadium A (“0”) und Stadium B (“1”). Zunächst liegt der Button in Stadium A (“0”) vor. Betätigt man jedoch diesen Button ein Mal, dann springt der Button in Stadium B (“1”). Wird der Button nun ein zweites Mal betätigt, dann springt der Button zurück in Stadium (“0”). Das heißt, dass der Button bei jedem Klick von einem Stadium in das andere wechselt.
DieobserveEvent-Funktion reagiert immer dann, wenn sich das Objekt in Argument 1 verändert. Aufgrund der Systematik des Action Buttons reagiert die Funktion in diesem Fall also auf jeden Klick.Anhand dieser Befehle kann man den Server nun vorläufig abschließen, indem man die Sudoku-Abbildung in eine reaktive Funktion (renderPlot) steckst, einem Output zuweist (Output$OutputId; OutputId aus dem User Interface) und die Quelle der Abbildung zu rv$data veränderst. Damit ist es dir möglich, das Default-Sudoku problemlos zu lösen (mit den Funktionen, die durch die Anforderungen 1-4 impliziert sind).
server <- function(input, output, session) {
BeispielSudoku <- readRDS('BeispielSudokuLeicht.rds')
rv <- reactiveValues(data = BeispielSudoku)
observeEvent(input$go, {
if(is.na(BeispielSudoku[input$row, input$column])){
rv$data[input$row, input$column] <- input$num
}
})
output$Sudokus <- renderPlot({
par(cex.axis = 1.5, col.axis = 'darkblue', mar = c(4,4,0,2))
plot(rv$data, border = F,
col = c("yellow" , "orange", "red", "violet", "lightblue",
"cornflowerblue", "lightgreen", "chartreuse3", "lightsalmon4"),
na.col = "white", xlab = "", ylab = "", text.cell = list(cex = 2),
key = NULL, fmt.cell='%.0f', na.print = '',
xlim = c(0.5, 9.5), ylim = c(0.5, 9.5))
abline(h = 0.5, lwd = 5)
abline(h = 1.5, lwd = 0.5)
abline(h = 2.5, lwd = 0.5)
abline(h = 3.5, lwd = 2)
abline(h = 4.5, lwd = 0.5)
abline(h = 5.5, lwd = 0.5)
abline(h = 6.5, lwd = 2)
abline(h = 7.5, lwd = 0.5)
abline(h = 8.5, lwd = 0.5)
abline(h = 9.5, lwd = 5)
abline(v = 0.5, lwd = 5)
abline(v = 1.5, lwd = 0.5)
abline(v = 2.5, lwd = 0.5)
abline(v = 3.5, lwd = 2)
abline(v = 4.5, lwd = 0.5)
abline(v = 5.5, lwd = 0.5)
abline(v = 6.5, lwd = 2)
abline(v = 7.5, lwd = 0.5)
abline(v = 8.5, lwd = 0.5)
abline(v = 9.5, lwd = 5)
})
}
2.) Nun besteht die Aufgabe nur noch darin, ein die Hochlade-Funktion in die gesamte Funktion zu implizieren. Zunächst einmal müssen wir uns dafür anschauen, was in dem zugehörigen Input (input$Matrix) ankommt. Schau dir dafür einfach mal diese Übersicht an. Es wird deutlich, dass beim Einlesen von eigenen Daten in unserem Fall unter input$Matrix$datapath der Dateipfad abgespeichert wird. Das heißt, dass wir zu diesem Zeitpunkt noch nicht den Datensatz mit der 9x9-Matrix zur Hand haben. Dieser muss dann eingelesen werden, wenn der dazugehörige Action Button mit der Aufschrift “Sudoku benutzen” betätigt wurde. Dazu verwenden wir abermals die observeEvent-Funktion mit input$use als Auslöse-Objekt und speichern den Datensatz als reaktives Objekt ab.
observeEvent(input$use, {
rv$data <- readRDS(input$Matrix$datapath)
})Vorausschauend können wir den Datensatz auch noch ein zweites Mal in einer “festen” Variable abspeichern, um später den Abgleich mit dem Ausgangssudoku durchführen zu können (damit vorgegebene Zahlen unverändlich sind). Da sich diese jedoch je nach eingelesenem Datensatz verändert, benutzen wir dafür die reactive-Funktion. Diese sorgt dafür, dass dieses Objekt (meinSudoku) beim Einlesen des Sudokus erstellt wird und ab diesem Zeitpunkt für jede weitere Operation verwendet wird (bis zum Einlesen eines neuen Sudokus).
observeEvent(input$use, {
rv$data <- readRDS(input$Matrix$datapath)
})
meinSudoku <- reactive({
readRDS(input$Matrix$datapath)
})Sofern man nun ein eigenes Sudoku einliest, kann dieses in der Sudoku-Abbildung verwendet werden. Doch zu diesem Zeitpunkt funktioniert das Einsetzen der Zahlen nicht, denn das richtet sich immer noch nach dem Ausgangssudoku. Aus diesem Grund kann jetzt eine if-Funktion dafür verwendet werden, je nach Ausgangslage verschiedene Zahlenabgleichs-Funktionen auszuwählen. Dafür kann man die Bedingung is.null(input$Matrix) verwenden, da das Input-Objekt NULL beinhaltet, sofern keine Datei hochgeladen wurde.
observeEvent(input$go, { #Action Button zum Einsetzen einer Zahl wurde betätigt.
if(is.null(input$Matrix)){ #Wenn keine Datei eingelesen wurde...
if(is.na(BeispielSudoku[input$row, input$column])){ #...und wenn das ausgewählte Feld im Ausgangssudoku (BeispielSudoku) leer war...
rv$data[input$row, input$column] <- input$num #...dann soll in dieses Feld die Zahl input$num eingesetzt werden.
}
}
})Diese Funktion beschreibt nun erst einmal den Fall, dass kein eigenes Sudoku eingelesen wurde und mit dem Ausgangssudoku gearbeitet werden soll. Jetzt muss noch der zweite Fall betrachtet werden, bei dem es ein eingelesenes Sudoku gibt:
observeEvent(input$go, { #Action Button zum Einsetzen einer Zahl wurde betätigt.
if(is.null(input$Matrix)){ #Wenn keine Datei eingelesen wurde und...
if(is.na(BeispielSudoku[input$row, input$column])){ #...wenn das ausgewählte Feld im Ausgangssudoku (BeispielSudoku) leer war, ...
rv$data[input$row, input$column] <- input$num #...dann soll in dieses Feld die Zahl input$num eingesetzt werden.
}
}
if(!is.null(input$Matrix)) { #Wenn "nicht kein Sudoku", also ein Sudoku, hochgeladen wurde und...
if(is.na(meinSudoku()[input$row, input$column])) { #...wenn das ausgewählte Feld im ursprünglichen hochgeladenen Sudoku(meinSudoku) leer war, ...
rv$data[input$row, input$column] <- input$num #...dann soll in dieses Feld die Zahl input$num eingesetzt werden.
}
}
})So werden letztlich beide Fälle explizit berücksichtigt. Wichtig zu beachten ist dabei, dass man das Objekt meinSudoku in der Bedingung der if-Funktion als reaktiven Ausdruck, also mit Klammern dahinter, anwählen muss: meinSudoku(). Jetzt kann man die ausarbeiteten Befehle aus 1.) und 2.) zusammenfügen und erhält folgenden abschließenden Server:
server <- function(input, output, session) {
BeispielSudoku <- readRDS('BeispielSudokuLeicht.rds')
rv <- reactiveValues(data = BeispielSudoku)
observeEvent(input$use, {
rv$data <- readRDS(input$Matrix$datapath)
})
meinSudoku <- reactive({
readRDS(input$Matrix$datapath)
})
observeEvent(input$go, {
if(is.null(input$Matrix)){
if(is.na(BeispielSudoku[input$row, input$column])){
rv$data[input$row, input$column] <- input$num
}
}
if(!is.null(input$Matrix)) {
if(is.na(meinSudoku()[input$row, input$column])) {
rv$data[input$row, input$column] <- input$num
}
}
})
output$Sudokus <- renderPlot({
par(cex.axis = 1.5, col.axis = 'darkblue', mar = c(4,4,0,2))
plot(rv$data, border = F,
col = c("yellow" , "orange", "red", "violet", "lightblue",
"cornflowerblue", "lightgreen", "chartreuse3", "lightsalmon4"),
na.col = "white", xlab = "", ylab = "", text.cell = list(cex = 2),
key = NULL, fmt.cell='%.0f', na.print = '',
xlim = c(0.5, 9.5), ylim = c(0.5, 9.5))
abline(h = 0.5, lwd = 5)
abline(h = 1.5, lwd = 0.5)
abline(h = 2.5, lwd = 0.5)
abline(h = 3.5, lwd = 2)
abline(h = 4.5, lwd = 0.5)
abline(h = 5.5, lwd = 0.5)
abline(h = 6.5, lwd = 2)
abline(h = 7.5, lwd = 0.5)
abline(h = 8.5, lwd = 0.5)
abline(h = 9.5, lwd = 5)
abline(v = 0.5, lwd = 5)
abline(v = 1.5, lwd = 0.5)
abline(v = 2.5, lwd = 0.5)
abline(v = 3.5, lwd = 2)
abline(v = 4.5, lwd = 0.5)
abline(v = 5.5, lwd = 0.5)
abline(v = 6.5, lwd = 2)
abline(v = 7.5, lwd = 0.5)
abline(v = 8.5, lwd = 0.5)
abline(v = 9.5, lwd = 5)
})
}Zusatz: Formelle Fertigstellung
Wie bereits in den Tipps erwähnt, sollte man eine App ohne vorhergehenden Code ausführen können. Dafür bedarf es der Aufnahme der Vorbereitungen in die server-Funktion. In diesem Fall beläuft sich das nur auf das Laden eines zusätzlichen Pakets:
# Paket laden
library(plot.matrix)Das gesamte Dokument aus User Interface und Server sieht dann abschließend folgendermaßen aus:
library(shiny)
ui <- pageWithSidebar(
titlePanel(
h1(strong(em("Hier kann man das Sudoku lösen!")),
align = "center", style = 'background: aqua'),
windowTitle = "Sudokus lösen!"),
sidebarPanel(
h3("Willst du dein eigenes Sudoku lösen? Lade dein Sudoku einfach hier hoch!"),
br(),
fileInput(inputId = "Matrix",
label = "Füge hier dein eigenes Sudoku (als .rds) ein!",
accept = ".rds",
buttonLabel = "Datei hochladen",
placeholder = "Noch keine Datei hochgeladen."),
actionButton(inputId = "use",
label = "Sudoku benutzen"),
h3("Wo willst du eine Zahl einsetzen?"),
numericInput(inputId = "row",
label = "Reihe",
value = '', min = 1, max = 9),
numericInput(inputId = "column",
label = "Spalte",
value = '', min = 1, max = 9),
numericInput(inputId = "num",
label = "Zahl",
value = '', min = 1, max = 9),
actionButton(inputId = "go",
label = "Zahl einsetzen")),
mainPanel(
wellPanel(
plotOutput("Sudokus", width = "640px", height = "600px"),
align = "center"
)
)
)
server <- function(input, output, session) {
# Paket laden
library(plot.matrix)
# Default-Sudoku laden
BeispielSudoku <- readRDS('BeispielSudokuLeicht.rds')
# Sudoku-Auswahl für die Erstellung der Sudoku-Abbildung
rv <- reactiveValues(data = BeispielSudoku)
observeEvent(input$use, {
rv$data <- readRDS(input$Matrix$datapath)
})
meinSudoku <- reactive({
readRDS(input$Matrix$datapath)
})
# Zahlen einsetzen
observeEvent(input$go, {
if(is.null(input$Matrix) & is.na(BeispielSudoku[input$row, input$column])){
rv$data[input$row, input$column] <- input$num
}
if(!is.null(input$Matrix)) {
if(is.na(meinSudoku()[input$row, input$column])) {
rv$data[input$row, input$column] <- input$num
}
}
})
# Abbildung erstellen
output$Sudokus <- renderPlot({
par(cex.axis = 1.5, col.axis = 'darkblue', mar = c(4,4,0,2))
plot(rv$data, border = F,
col = c("yellow" , "orange", "red", "violet", "lightblue",
"cornflowerblue", "lightgreen", "chartreuse3", "lightsalmon4"),
na.col = "white", xlab = "", ylab = "", text.cell = list(cex = 2),
key = NULL, fmt.cell='%.0f', na.print = '',
xlim = c(0.5, 9.5), ylim = c(0.5, 9.5))
abline(h = 0.5, lwd = 5)
abline(h = 1.5, lwd = 0.5)
abline(h = 2.5, lwd = 0.5)
abline(h = 3.5, lwd = 2)
abline(h = 4.5, lwd = 0.5)
abline(h = 5.5, lwd = 0.5)
abline(h = 6.5, lwd = 2)
abline(h = 7.5, lwd = 0.5)
abline(h = 8.5, lwd = 0.5)
abline(h = 9.5, lwd = 5)
abline(v = 0.5, lwd = 5)
abline(v = 1.5, lwd = 0.5)
abline(v = 2.5, lwd = 0.5)
abline(v = 3.5, lwd = 2)
abline(v = 4.5, lwd = 0.5)
abline(v = 5.5, lwd = 0.5)
abline(v = 6.5, lwd = 2)
abline(v = 7.5, lwd = 0.5)
abline(v = 8.5, lwd = 0.5)
abline(v = 9.5, lwd = 5)
})
}
shinyApp(ui, server)Führt man nun die Endprodukte aus den Abschnitten User Interface (ui) und Server (server) aus, kann man mit dieser Funktion die Applikation starten.
shinyApp(ui, server)So könnte die App dann letztlich bei dir aussehen:
Damit ist man also nicht nur in der Lage, über das erstellte Interface das Ausgangssudoku vollständig zu lösen, sondern man kann auch eigene Sudokus hochladen und mit diesem Interface bearbeiten. Da sich die App hier nun wieder an die Breite des Textfensters angepasst hat, kannst du dir die App hier nochmals in voller Breite (und damit in der Basis-Formatierung) anschauen.